本文共 12615 字,大约阅读时间需要 42 分钟。
文章目录
一、多项式对数据的处理
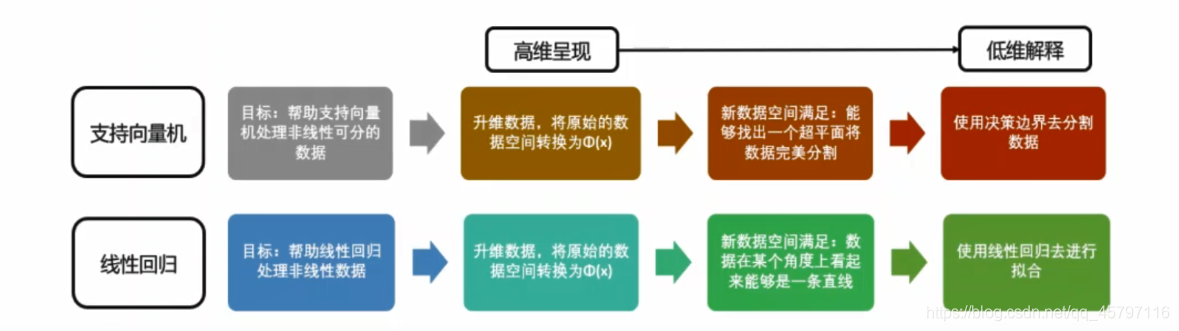
除了分箱之外,另一种更普遍的用于解决"线性回归只能处理线性数据"问题的手段,就是使用多项式回归对线性回归进行改进。这样的手法是机器学习研究者们从支持向量机中获得的:支持向量机通过升维可以将非线可分数据转化为线性可分,然后使用核函数在低维空间中进行计算,这是一种高维呈现,低维解释的思维。我们也可以让线性回归使用类似于升维的转换,将数据由非线性转换为线性,从而为线性回归赋予处理非线性数据的能力。
 接下来,我们就来看看线性模型中的升维工具:多项式变化。这是一种
接下来,我们就来看看线性模型中的升维工具:多项式变化。这是一种通过增加自变量上的次数,而将数据映射到高维空间的方法,只要我们设定一个自变量上的次数(大于1),就可以相应地获得数据投影在高次方的空间中的结果,简单的举个例子说就是将二维数据转为三维、四维空间数据。这种方法可以非常容易地通过 sklearn中的PolynomialFeatures类来实现。 注意区分: • 多项式变化是在高维呈现时进行,多项式核函数是在地位解释的时候进行 • 类似于分箱,多项式变化也都是在原始数据集上进行处理,使得数据集能够实现线性回归拟合
class sklearn.preprocessing.PolynomialFeatures(degree=2, *, interaction_only=False, include_bias=True, order='C')

from sklearn.preprocessing import PolynomialFeaturesimport numpy as np# 假设原始数据是一维的,经过转换成为2维x = np.arange(1,4).reshape(-1,1)print(x.ndim) # 2# [[1],# [2],# [3]]# 二次多项式,参数degree控制多项式的次方ploy = PolynomialFeatures(degree=2)# 接口transform直接调用,x_ = ploy.fit_transform(x)# [[1. 1. 1.],# [1. 2. 4.],# [1. 3. 9.]]ploy = PolynomialFeatures(degree=3)# 接口transform直接调用x__ = ploy.fit_transform(x)# [[ 1. 1. 1. 1.],# [ 1. 2. 4. 8.],# [ 1. 3. 9. 27.]]ploy = PolynomialFeatures(degree=4)# 接口transform直接调用x___ = ploy.fit_transform(x)# [[ 1. 1. 1. 1. 1.],# [ 1. 2. 4. 8. 16.],# [ 1. 3. 9. 27. 81.]]
不难注意到,多项式变化后数据看起来不太一样了:首先,数据的特征(维度)增加了,这正符合我们希望的将数据转换到高维空间的愿望。其次,维度的增加是有一定的规律的。不难发现,如果我们本来的特征矩阵中只有一个特征x,而转换后我们得到:
 这个规律在转换为二次多项式的时候同样适用。原本,我们的模型应该是形似y=ax+b的结构,而转换后我们的特征变化导致了模型的变化。根据我们在支持向量机中的经验,现在这个被投影到更高维空间中的数据在某个角度上看起来已经是一条直线了,于是我们可以继续使用线性回归来进行拟合。线性回归是会对每个特征拟合出权重w的,所以当我们拟合高维数据的时候,我们会得到下面的模型:
这个规律在转换为二次多项式的时候同样适用。原本,我们的模型应该是形似y=ax+b的结构,而转换后我们的特征变化导致了模型的变化。根据我们在支持向量机中的经验,现在这个被投影到更高维空间中的数据在某个角度上看起来已经是一条直线了,于是我们可以继续使用线性回归来进行拟合。线性回归是会对每个特征拟合出权重w的,所以当我们拟合高维数据的时候,我们会得到下面的模型: 
这就是大家会在大多数数学和机器学习教材中会看到的"多项式回归"的表达式。这个过程看起来非常简单,只不过是将原始的x上的次方增加,并且为这些次方项都加上权重w,然后增加一列所有次方为0的列作为截距乘数的x0,参数 include_bias就是用来控制x0的生成的。
① 一维数据集简单案例 ---- (维度针对特征数而言)
# 原始数据集xx = np.arange(1,4).reshape(-1,1)# 对数据集进行多项式变化ploy = PolynomialFeatures(degree=3)xxx = ploy.fit_transform(x)# [[ 1. 1. 1. 1.],# [ 1. 2. 4. 8.],# [ 1. 3. 9. 27.]]# 生成数据集yrnd = np.random.RandomState(42)y = rnd.random(3)# [0.37454012 0.95071431 0.73199394]# 对x、y进行线性拟合result = LinearRegression().fit(xxx,y)# 查看生成的系数wprint(result.coef_)# [-9.71445147e-16 2.48123876e-01 4.31857528e-01 -1.38217467e-01]# 查看生成的截距print(result.intercept_)# -0.1672238171928806

在这里结合多项式表达式我们可以看到,线性回归并没有把多项式生成的w0当作是截距项,因为对于程序而言只负责处理输入的数据,并没有指明哪一项数据是截距项。
- 所以我们可以选择:
关闭多项式回归中的 include_bias - 也可以选择:
关闭线性回归中的 fit_intercept
result1 = LinearRegression(fit_intercept=False).fit(xxx,y)print(result1.coef_) # [-0.13619259 0.1912333 0.46288875 -0.14338934]print(result1.intercept_) # 0.0
当我们关闭线性回归模型中的截距生成项的时候,从生成的W中选取一项为w0,并与x0相乘,然后加上没有生成的截距0。总体看来也就相当于将截距整合在了前面的w0、x0中了。
② 多维数据集案例 ---- (维度针对特征数而言)
在现实的生活中,处理一维数据是不现实的。更多的是处理多维(多特征)的数据集,这个时候,针对于一维的多项式转化规律已经不能完全适用了。
♦ 二维测试
from sklearn.preprocessing import PolynomialFeaturesimport numpy as npx = np.arange(6).reshape(3,2)#[[0 1],# [2 3],# [4 5]]# 测试多项式转化 --- 二次多项式poly = PolynomialFeatures(degree=2).fit_transform(x)#[[ 1. 0. 1. 0. 0. 1.],# [ 1. 2. 3. 4. 6. 9.],# [ 1. 4. 5. 16. 20. 25.]]

♦ 三维测试
poly_ = PolynomialFeatures(degree=3).fit_transform(x)# [[ 1. 0. 1. 0. 0. 1. 0. 0. 0. 1.],# [ 1. 2. 3. 4. 6. 9. 8. 12. 18. 27.],# [ 1. 4. 5. 16. 20. 25. 64. 80. 100. 125.]]

在多项式回归中,我们可以规定是否产生平方或立方项,其实如果我们只要求高次项的话,x1x2会是一个比x₁²更好的高次项,因为x₁x₂和x₁之间的共线性会比x₁²与x1之间的共线性好那么一点点(只是一点点,虽然结果有时相同),而我们多项式转化之后是需要使用线性回归模型来进行拟合的,就算机器学习中不是那么在意数据上的基本假设,但是太过分的共线性还是会影响到模型的拟合。因此 sklearn中存在着控制是否要生成平方和立方项的参数 interactiononly默认为 False,以减少共线性。来看这个参数是如何工作的:
# 测试多项式转化 --- 二次多项式poly = PolynomialFeatures(degree=2).fit_transform(x)#[[ 1. 0. 1. 0. 0. 1.],# [ 1. 2. 3. 4. 6. 9.],# [ 1. 4. 5. 16. 20. 25.]]poly_interaction_true = PolynomialFeatures(degree=2,interaction_only=True).fit_transform(x)# [[ 1. 0. 1. 0.], # [ 1. 2. 3. 6.], # [ 1. 4. 5. 20.]]
通过对比可以发现,当参数interaction_only设为True的时候,多项式转化只生成了交互项。这里所谓的交互项是指形如x₁x₁的多项式。
随着原特征矩阵的维度上升,随着我们规定的最高次数的上升,数据会变得越来越复杂,维度越来越多,并且这种维度的增加并不能用太简单的数学公式表达出来。因此,多项式回归没有固定的模型表达式,多项式回归的模型最终长什么样子是由数据和最高次数决定的,因此我们无法断言说某个数学表达式"就是多项式回归的数学表达",因此要求解多项式回归不是一件容易的事儿。
③ 多项式回归处理非线性问题
- 首先使用线性回归进行一次拟合,之后便于和多项式回归拟合效果进行对比。
# 设置随机种子数rnd = np.random.RandomState(42) # 设置随机种子数x = rnd.uniform(-3,3,size=100)y = np.sin(x) + rnd.normal(size=len(x)) / 3# 准备好数据集x = x.reshape(-1,1)# 创建测试数据集 x0 ---- 等差数列(均匀分布在训练集x的取值范围内的1000个点)line =np.linspace(-3,3,1000,endpoint=False).reshape(-1,1)# 对原始数据进行拟合LinearR = LinearRegression().fit(x,y)score = LinearR.score(x,y) # 0.5361526059318595# 对测试数据集进行拟合效果的评分score_test = LinearR.score(line,np.sin(line)) # 0.6800102369793312
- 使用多项式转化数据为高维后,在进行拟合
# 多项式转化x_ = PolynomialFeatures(degree=5).fit_transform(x)line_ = PolynomialFeatures(degree=5).fit_transform(line)# 多项式训练数据集拟合LinearR_ = LinearRegression().fit(x_,y)x_score = LinearR_.score(x_,y) # 0.8561679370344799# 多项式测试数据集拟合line_score = LinearR_.score(line_,np.sin(line)) # 0.9868904451787983
通过对比可以明显的发现,通过多项式回归,对于线性回归处理非线性数据的提升效果十分明显。
④ 可视化
# -*- coding: utf-8# @Time : 2021/1/19 11:34# @Author : ZYX# @File : Example13_多项式回归处理可视化.py# @software: PyCharmimport numpy as npimport matplotlib.pyplot as pltfrom sklearn.linear_model import LinearRegressionfrom sklearn.preprocessing import PolynomialFeatures# 设置随机种子数rnd = np.random.RandomState(42) # 设置随机种子数x = rnd.uniform(-3,3,size=100)y = np.sin(x) + rnd.normal(size=len(x)) / 3# 准备好数据集x = x.reshape(-1,1)# 创建测试数据集 x0 ---- 等差数列(均匀分布在训练集x的取值范围内的1000个点)line =np.linspace(-3,3,1000,endpoint=False).reshape(-1,1)# 对原始数据进行拟合LinearR = LinearRegression().fit(x,y)# 多项式转化x_ = PolynomialFeatures(degree=5).fit_transform(x)line_ = PolynomialFeatures(degree=5).fit_transform(line)# 多项式训练数据集拟合LinearR_ = LinearRegression().fit(x_,y)# 放置画布fig,ax1 = plt.subplots(1)# 将测试数据代入predict接口,获得模型的拟合效果ax1.plot(line,LinearR.predict(line),linewidth=2,color='green',label='linear regression')ax1.plot(line,LinearR_.predict(line_),linewidth=2,color='red',label='Polynomial regression')# 绘制原数据集ax1.plot(x[:,0],y,'o',c='k')#其他图形选项ax1. legend(loc="best")ax1. set_ylabel("Regression output")ax1. set_xlabel("Input feature")ax1. set_title("Result before discretization")plt. tight_layout()plt. show() 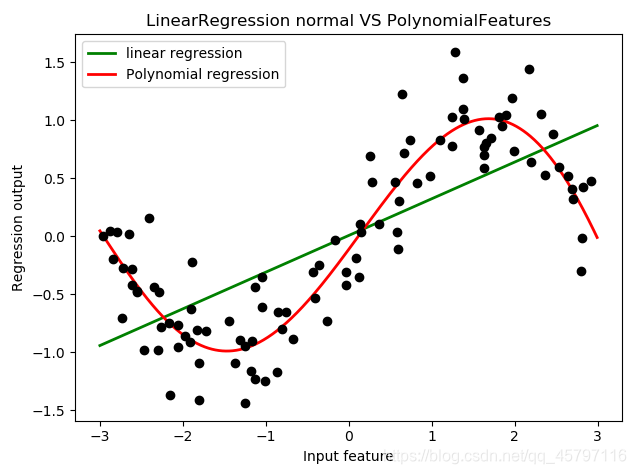
d = 2
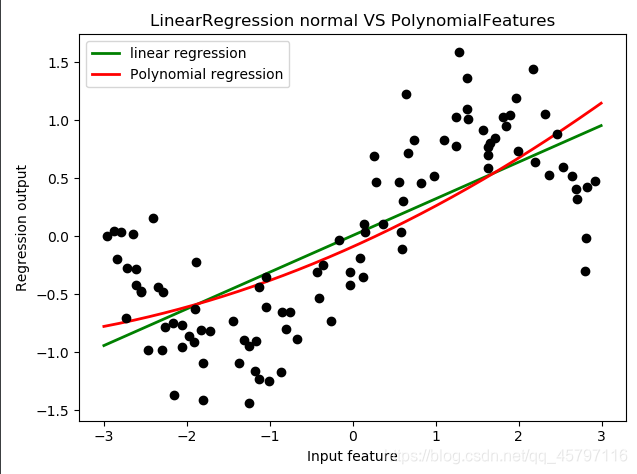 过低的高次项,会使得拟合没有明显的效果!
过低的高次项,会使得拟合没有明显的效果! d = 10
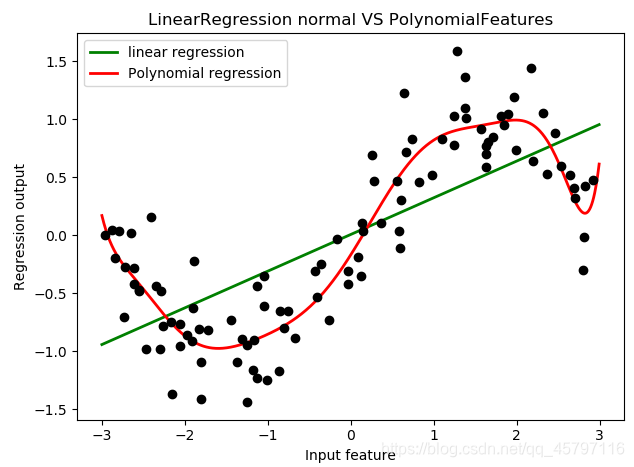
d = 20
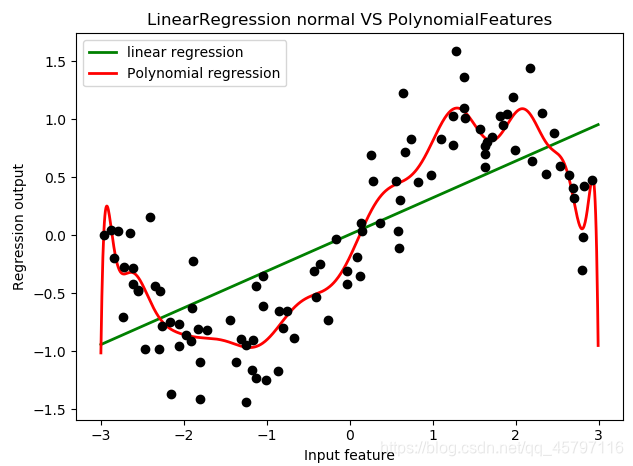 过高的高次项会使得过拟合!
过高的高次项会使得过拟合! 从这里大家可以看出,多项式回归能够较好地拟合非线性数据,还不容易发生过拟合,可以说是保留了线性回归作为线性模型所带的“不容易过拟合和“计算快速”的性质,同时又实现了优秀地拟合非线性数据。
二、多项式回归的可解释性 < get_ feature_names() >
线性回归是一个具有高解释性的模型,它能够对每个特征拟合出参数w以帮助我们理解每个特征对于标签的贡献程度。当我们进行了多项式转换后,尽管我们还是形成形如线性回归的方程,但随着数据维度和多项式次数的增加,对应的特征也变得异常复杂,我们可能无法一眼看出增维后的特征是由之前的什么特征组成的(之前我们都是肉眼可以直接进行判断)。不过,多项式回归的可解释性依然是存在的,我们可以使用接口get_ feature_names来调用生成的新特征矩阵的各个特征上的名称,以便帮助我们解释模型。来看下面的例子:
import numpy as npfrom sklearn.preprocessing import PolynomialFeaturesfrom sklearn.linear_model import LinearRegression# 创建原始数据集x = np.arange(9).reshape(3,3)# 对数据集进行多项式转化poly = PolynomialFeatures(degree=5).fit(x)# 调用重要接口get_feature_names --- 获取高维特征的组合feature_names = poly.get_feature_names()'''['1', 'x0', 'x1', 'x2', 'x0^2', 'x0 x1', 'x0 x2', 'x1^2', 'x1 x2', 'x2^2', 'x0^3', 'x0^2 x1', 'x0^2 x2', 'x0 x1^2', 'x0 x1 x2', 'x0 x2^2', 'x1^3', 'x1^2 x2', 'x1 x2^2', 'x2^3', 'x0^4', 'x0^3 x1', 'x0^3 x2', 'x0^2 x1^2', 'x0^2 x1 x2', 'x0^2 x2^2', 'x0 x1^3', 'x0 x1^2 x2', 'x0 x1 x2^2', 'x0 x2^3', 'x1^4', 'x1^3 x2', 'x1^2 x2^2', 'x1 x2^3', 'x2^4', 'x0^5', 'x0^4 x1', 'x0^4 x2', 'x0^3 x1^2', 'x0^3 x1 x2', 'x0^3 x2^2', 'x0^2 x1^3', 'x0^2 x1^2 x2', 'x0^2 x1 x2^2', 'x0^2 x2^3', 'x0 x1^4', 'x0 x1^3 x2', 'x0 x1^2 x2^2', 'x0 x1 x2^3', 'x0 x2^4', 'x1^5', 'x1^4 x2', 'x1^3 x2^2', 'x1^2 x2^3', 'x1 x2^4', 'x2^5']'''
通过简单的数据集的应用,我们可以发现get_feature_names()返回的是线性回归拟合后的回归系数代表的特征组合,这样一来就很好的解释了某个ω的具体含义。
下面我们使用加利福尼亚房屋价值数据集进一步探究:
① 读取加利福尼亚数据集
# 分析处理加利福尼亚数据import pandas as pdfrom sklearn.datasets import fetch_california_housing as fch# 加载数据集house_value = fch()x = pd.DataFrame(house_value.data)y = house_value.targetfeature_name = house_value.feature_names# ['MedInc', 'HouseAge', 'AveRooms', 'AveBedrms', 'Population', 'AveOccup', 'Latitude', 'Longitude']
② 多项式转化加利福尼亚数据集并进行解释
# 使用多项式转化加利福尼亚数据集poly = PolynomialFeatures(degree=2).fit(x,y)name1 = poly.get_feature_names()'''['1', 'x0', 'x1', 'x2', 'x3', 'x4', 'x5', 'x6', 'x7', 'x0^2', 'x0 x1', 'x0 x2', 'x0 x3', 'x0 x4', 'x0 x5', 'x0 x6', 'x0 x7', 'x1^2', 'x1 x2', 'x1 x3', 'x1 x4', 'x1 x5', 'x1 x6', 'x1 x7', 'x2^2', 'x2 x3', 'x2 x4', 'x2 x5', 'x2 x6', 'x2 x7', 'x3^2', 'x3 x4', 'x3 x5', 'x3 x6', 'x3 x7', 'x4^2', 'x4 x5', 'x4 x6', 'x4 x7', 'x5^2', 'x5 x6', 'x5 x7', 'x6^2', 'x6 x7', 'x7^2']'''# 在get_feature_names中传入列名,结果就会显示出具体列名的组合name2 = poly.get_feature_names(feature_name)'''['1', 'MedInc', 'HouseAge', 'AveRooms', 'AveBedrms', 'Population', 'AveOccup', 'Latitude', 'Longitude', 'MedInc^2', 'MedInc HouseAge', 'MedInc AveRooms', 'MedInc AveBedrms', 'MedInc Population', 'MedInc AveOccup', 'MedInc Latitude', 'MedInc Longitude', 'HouseAge^2', 'HouseAge AveRooms', 'HouseAge AveBedrms', 'HouseAge Population', 'HouseAge AveOccup', 'HouseAge Latitude', 'HouseAge Longitude', 'AveRooms^2', 'AveRooms AveBedrms', 'AveRooms Population', 'AveRooms AveOccup', 'AveRooms Latitude', 'AveRooms Longitude', 'AveBedrms^2', 'AveBedrms Population', 'AveBedrms AveOccup', 'AveBedrms Latitude', 'AveBedrms Longitude', 'Population^2', 'Population AveOccup', 'Population Latitude', 'Population Longitude', 'AveOccup^2', 'AveOccup Latitude', 'AveOccup Longitude', 'Latitude^2', 'Latitude Longitude', 'Longitude^2']'''
③ 对转化高维数据进行线性回归拟合
# 将数据转换为多项式特征x_ = poly.transform(x)# 构建线性回归模型,训练数据集x_reg = LinearRegression().fit(x_,y)# 获取 coef_ 回归系数coef = reg.coef_# 使用zip方法,将回归系数与特征对应point_coef = [*zip(name2,coef)]'''[('1', 5.919548140983327e-08), ('MedInc', -11.24302560111705), ('HouseAge', -0.8488985550865563), ('AveRooms', 6.441059400883809), ('AveBedrms', -31.591330845036552), ('Population', 0.00040609067821869747), ('AveOccup', 1.0038623251695358), ('Latitude', 8.705681915719547), ('Longitude', 5.880632747311831), ('MedInc^2', -0.03130812100951305), ('MedInc HouseAge', 0.0018599475393629849), ('MedInc AveRooms', 0.0433020363878387), ('MedInc AveBedrms', -0.18614228848200254), ('MedInc Population', 5.7283140110601324e-05), ('MedInc AveOccup', -0.0025901945074209877), ('MedInc Latitude', -0.15250571869449078), ('MedInc Longitude', -0.14424294470380816), ('HouseAge^2', 0.00021172536249781818), ('HouseAge AveRooms', -0.0012621898121656394), ('HouseAge AveBedrms', 0.010611503740612389), ('HouseAge Population', 2.8188531235643024e-06), ('HouseAge AveOccup', -0.001817169463553861), ('HouseAge Latitude', -0.010069037408715655), ('HouseAge Longitude', -0.009999501833718248), ('AveRooms^2', 0.0072694776...''' ④ 利用多项式回归的可解释性找出重要特征
- 主要就是将组合的特征转为DataFrame,在对其按照回归系数的比重进行排序。
# 将对应结果转为DF,进行降序排序sort_coef = pd.DataFrame(point_coef,columns=['feature','coef']).sort_values(by="coef",ascending=False)''' 主要是回归系数占比较大的前几个特征feature coef [7: Latitude 8.705681915719547], [3: AveRooms 6.441059400883809], [8: Longitude 5.880632747311831], [6: AveOccup 1.0038623251695358], [30: AveBedrms^2 0.16018095673076496], [43: Latitude Longitude 0.10810717328652852], [28: AveRooms Latitude 0'''
三、探索多项式回归对于模型表现的提升
import pandas as pdfrom time import timefrom sklearn.linear_model import LinearRegressionfrom sklearn.datasets import fetch_california_housing as fchfrom sklearn.preprocessing import PolynomialFeaturesfrom sklearn.ensemble import RandomForestRegressor as RFR# 读取数据集house_value = fch()x = pd.DataFrame(house_value.data)y = house_value.target# 将数据集进行多项式转化poly = PolynomialFeatures(degree=4).fit(x,y)x_ = poly.transform(x)# 对原始数据进行线性回归进行拟合reg = LinearRegression().fit(x,y)# 获取R2指数score = reg.score(x,y) # 0.6062326851998051# 对多项式化数据集进行线性回归拟合reg_ = LinearRegression().fit(x_,y)# 获取R2指数score_ = reg_.score(x_,y) # 0.7451596609109877# 查看解释point = poly.get_feature_names(house_value.feature_names)coef = reg_.coef_combine = [*zip(point,coef)]sort_coef = pd.DataFrame(combine,columns=['features','coef']).sort_values(by='coef')
可以发现,对于非线性数据集,在使用了多项式回归处理后,其效果会有很大的提升。从原本的0.606提升至了0.745,说明多项式回归在某种意义上能够有效的解决非线性数据集问题。
# 对比:使用随机森林回归非线性模型进行处理time0 = time()RFR_score = RFR(n_estimators=100).fit(x,y).score(x,y) # 0.9741543756049823print("time:{}".format(time()-time0))# time:11.149184942245483# 对多项式化数据集进行线性回归线性模型处理time0 = time()reg_ = LinearRegression().fit(x_,y)# 获取R2指数score_ = reg_.score(x_,y) # 0.7451596609109877print("time:{}".format(time()-time0)) # time:0.7400212287902832 与此同时,我们使用随机森林回归,预设定生成100棵树,然后对原始数据集进行回归拟合,其效果达到了0.974。但是同时,与其高度的拟合效果所相反的就是它耗费了大量的时间。我们可以看到,使用多项式回归后的线性回归拟合用时0.75秒左右,而随机森林回归的用时是11.15秒左右,约为15倍。在实际的应用过程中,一般来说需要运行较为快的,但是不排除精确结果情况,所以需要根据具体的需求,对模型进行适当的选择。
四、多项式回归属于线性模型?还是非线性模型
对于普通的非线性而言,就是我们拟合的数据结果中,不含有高次自变量。单从这一个角度以及如下公式来看,多项式回归属于非线性模型无疑。



发表评论
最新留言
关于作者
