提升树 & GBDT
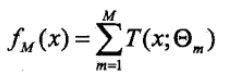 这里分类树(二分类)就用Adaboost就行 回归树采用残差训练
这里分类树(二分类)就用Adaboost就行 回归树采用残差训练 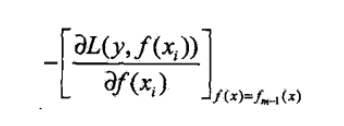
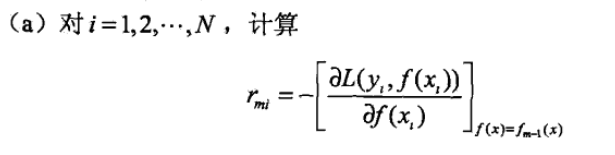
 注意,这里获得的rmi实际上就是残查(估计值),一共得到N个近似残差值
注意,这里获得的rmi实际上就是残查(估计值),一共得到N个近似残差值
发布日期:2021-05-09 14:26:28
浏览次数:18
分类:精选文章
本文共 994 字,大约阅读时间需要 3 分钟。
仍然采用的是加法模型:
注意看,这里没有用权值。 这里分类树(二分类)就用Adaboost就行 回归树采用残差训练 
GBDT的思想可以用一个通俗的例子解释,假如有个人30岁,我们首先用20岁去拟合,发现损失有10岁,这时我们用6岁去拟合剩下的损失,发现差距还有4岁,第三轮我们用3岁拟合剩下的差距,差距就只有一岁了。如果我们的迭代轮数还没有完,可以继续迭代下面,每一轮迭代,拟合的岁数误差都会减小。
但是有个问题:不同损失函数的时候比较难办(除了平方,对数,其他的不太好求)
这就是GBDT:用损失函数的负梯度来拟合本轮损失的近似值,进而拟合一个CART回归树 1.gbdt 是通过采用加法模型(即基函数的线性组合),以及不断减小训练过程产生的残差来达到将数据分类或者回归的算法。
gbdt通过多轮迭代,每轮迭代产生一个弱分类器(CART TREE),每个分类器在上一轮分类器的残差基础上进行训练。对弱分类器的要求一般是足够简单,并且是低方差和高偏差的。因为训练的过程是通过降低偏差来不断提高最终分类器的精度(因为本身具有一定的抑制过拟合作用)GBDT的核心就在于,每一棵树学的是之前所有树结论和的残差,这个残差就是一个加预测值后能得真实值的累加量。比如A的真实年龄是18岁,但第一棵树的预测年龄是12岁,差了6岁,即残差为6岁。那么在第二棵树里我们把A的年龄设为6岁去学习,如果第二棵树真的能把A分到6岁的叶子节点,那累加两棵树的结论就是A的真实年龄;如果第二棵树的结论是5岁,则A仍然存在1岁的残差,第三棵树里A的年龄就变成1岁,继续学。
残差的意思就是: A的预测值 + A的残差 = A的实际值),所以A的残差就是16-15=1(注意,A的预测值是指前面所有树累加的和,这里前面只有一棵树所以直接是15,如果还有树则需要都累加起来作为A的预测值) 无论此时的cost function是什么,是均方差还是均差,只要它以误差作为衡量标准,残差向量(-1, 1, -1, 1)都是它的全局最优方向,这就是Gradient。 注意,这里获得的rmi实际上就是残查(估计值),一共得到N个近似残差值 发表评论
最新留言
关注你微信了!
[***.104.42.241]2025年04月19日 03时39分14秒
关于作者

喝酒易醉,品茶养心,人生如梦,品茶悟道,何以解忧?唯有杜康!
-- 愿君每日到此一游!
推荐文章
成功解决升级virtualenv报错问题
2021-05-11
如何使用Linux命令查看端口是否被占用
2021-05-11
Redis——服务器
2021-05-11
iOS KVC
2021-05-11
iOS 宏定义的使用与规范
2021-05-11
CoreText(四):行 CTLineRef
2021-05-11
CoreText(五):省略号
2021-05-11
iOS 8:一、tableView右滑显示选择
2021-05-11
解决hadoop出现Warning: fs.defaultFS is not set异常
2021-05-11
Android开发之获取常用android设备参数信息
2021-05-11
Jenkins打包之本地远程自动打包教程
2021-05-11
【SQLI-Lab】靶场搭建
2021-05-11
java——如何停止一个线程
2021-05-11
linux环境下nginx安装
2021-05-11
mysql 分区-range分区(二)
2021-05-11
Vue 使用fetch无法获取最新的数据请求 cache引起的错误
2021-05-11
Xception 设计进化
2021-05-11
shell基础---行转列(awk),列转行(tr)
2021-05-11
抗DDOS攻击
2021-05-11
白红宇的个人博客 - 记录点点滴滴的事 - 您是第 460881851 位访客