0001 requests库的简单使用,自动下载百度图片中的图片(优雅地云吸猫)
 打开方式有三种:
打开方式有三种: 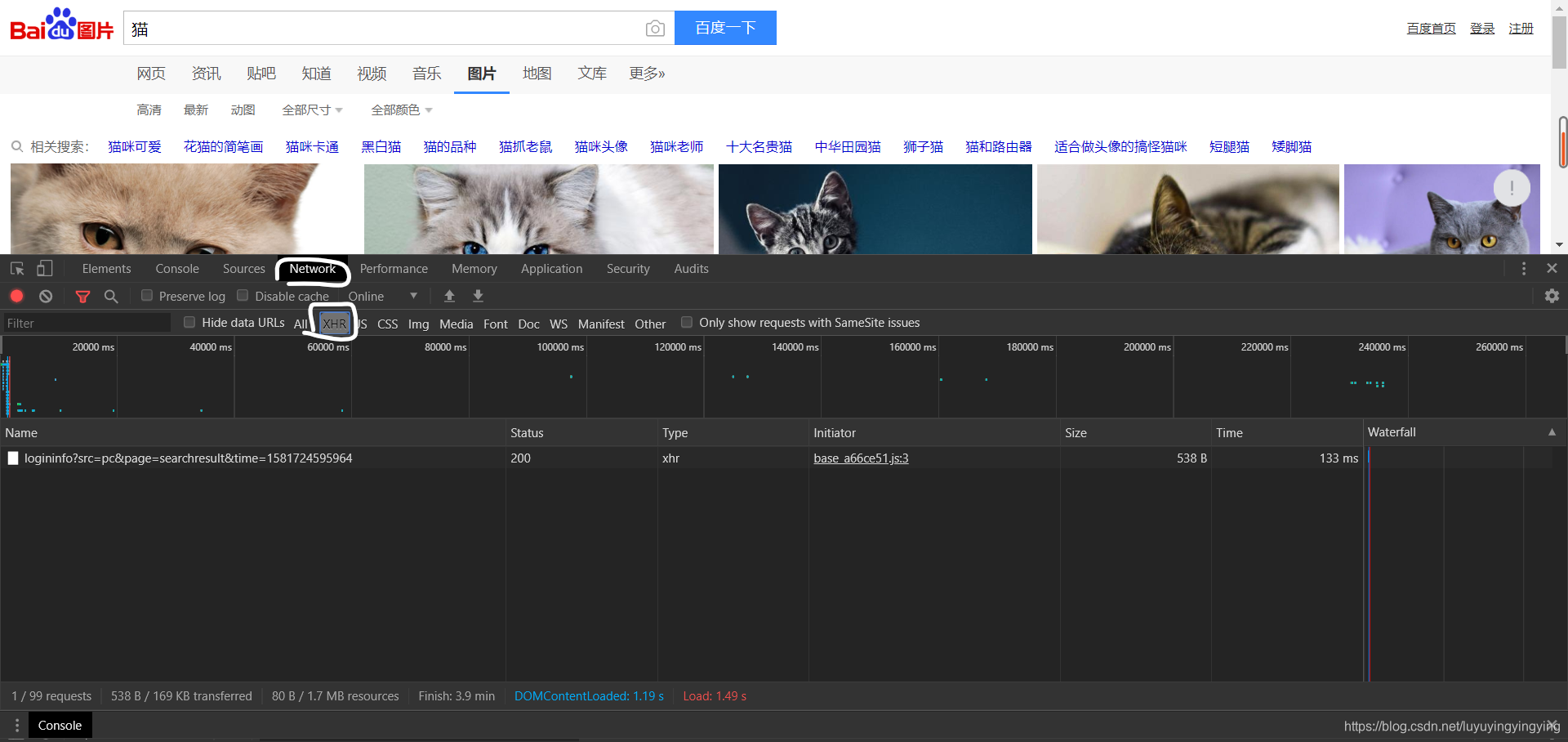 由于百度图片使用了Ajax交互,只有在你下拉滚轮的时候才会显示出更多的图片,所以我们需要下拉几次滚轮 Ajax交互是一种动态的交互网页,只有在你做出向下滚动之类的操作,网页上的资源才会加载出来,并且随时需要随时加载。
由于百度图片使用了Ajax交互,只有在你下拉滚轮的时候才会显示出更多的图片,所以我们需要下拉几次滚轮 Ajax交互是一种动态的交互网页,只有在你做出向下滚动之类的操作,网页上的资源才会加载出来,并且随时需要随时加载。 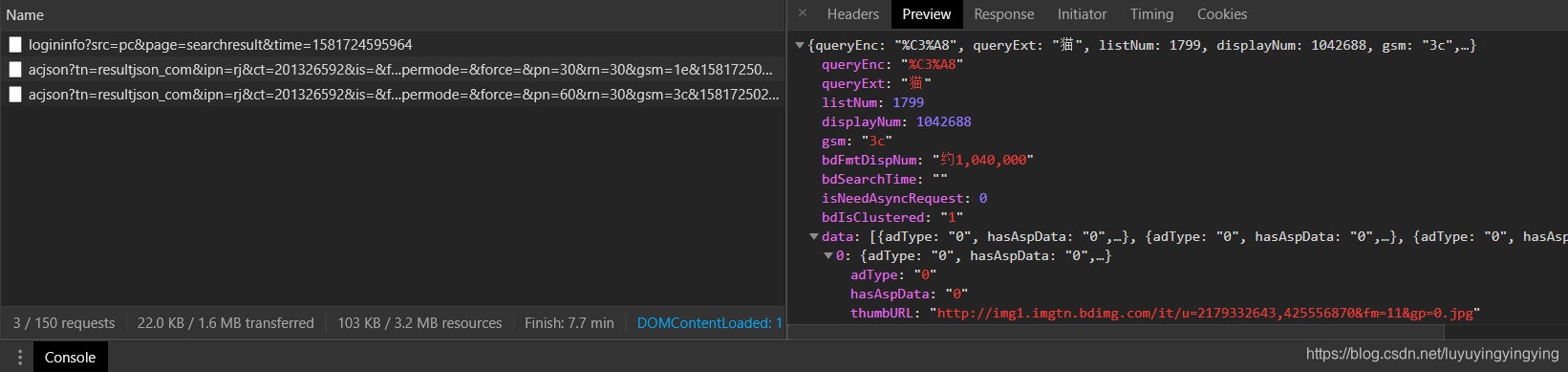 我们复制这个url,在地址栏输入,并打开,可以看到一张与猫有关的图片
我们复制这个url,在地址栏输入,并打开,可以看到一张与猫有关的图片 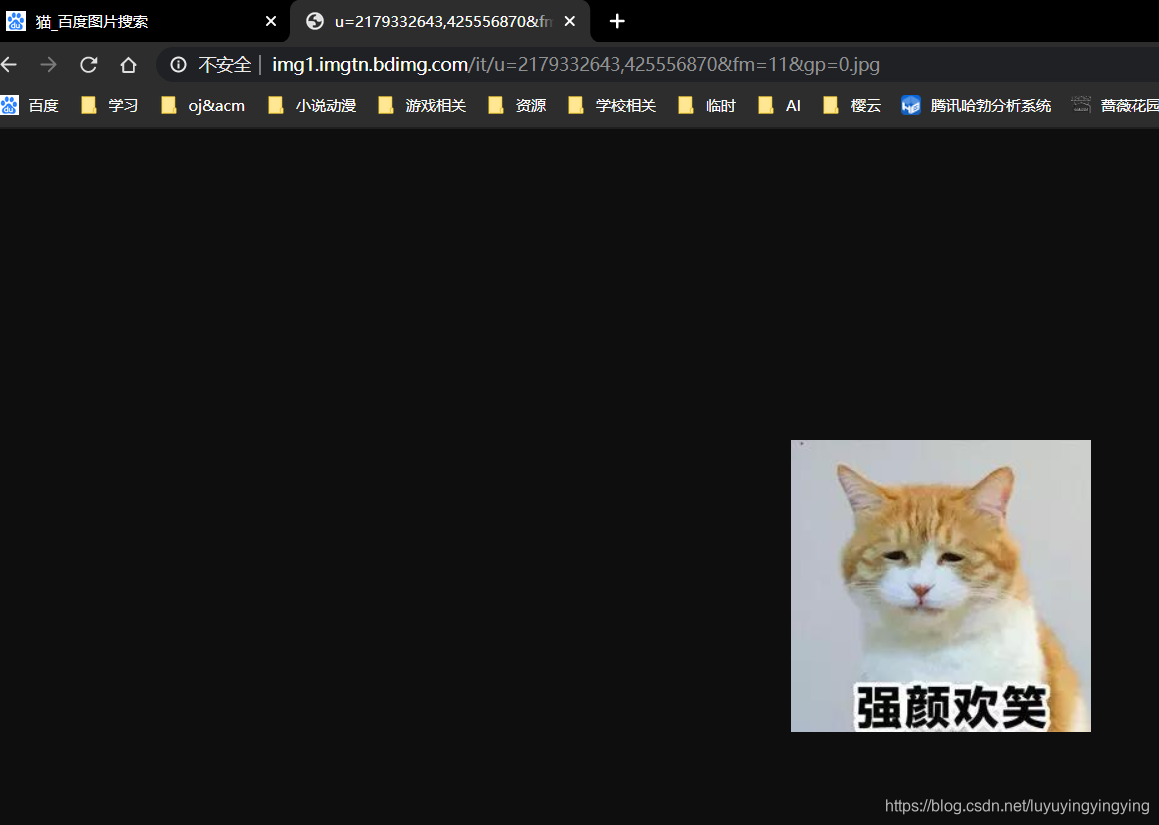
 找到了我们要爬取资源的规律,就可以来编写爬虫代码了
找到了我们要爬取资源的规律,就可以来编写爬虫代码了 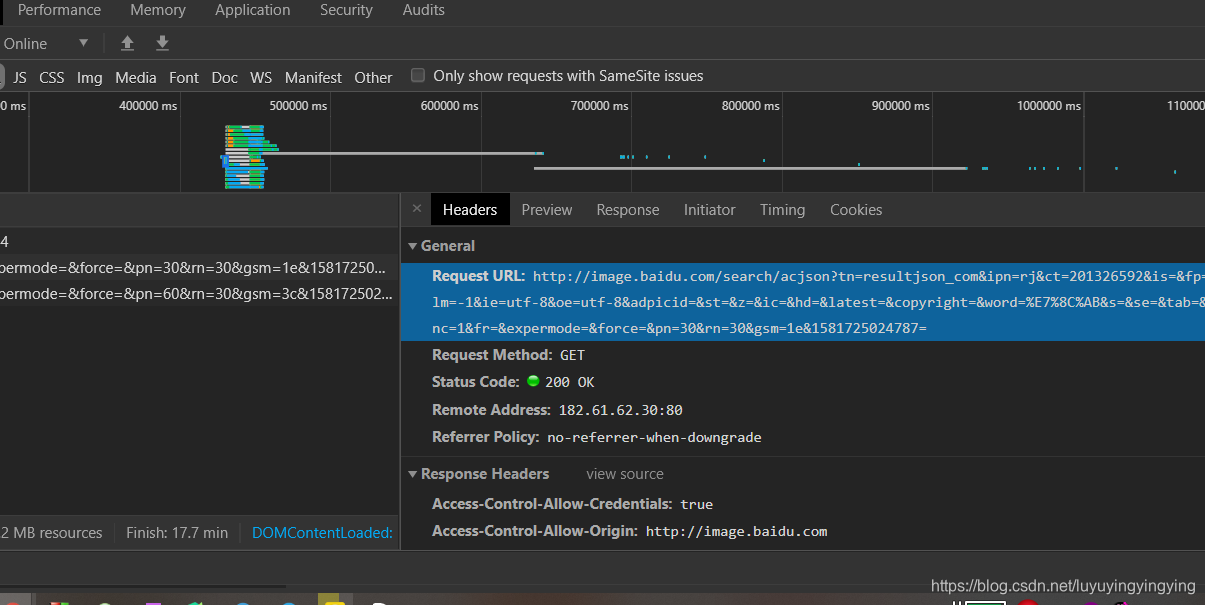
 我们想要下载的图片的url在data里,所以我们要读取data中的数据。 这里网页上的代码是json代码,与python中的字典很相似,所以我们可以使用python中字典的方式获取json中的元素。
我们想要下载的图片的url在data里,所以我们要读取data中的数据。 这里网页上的代码是json代码,与python中的字典很相似,所以我们可以使用python中字典的方式获取json中的元素。  这样,我们就写好了获取图片url的函数
这样,我们就写好了获取图片url的函数 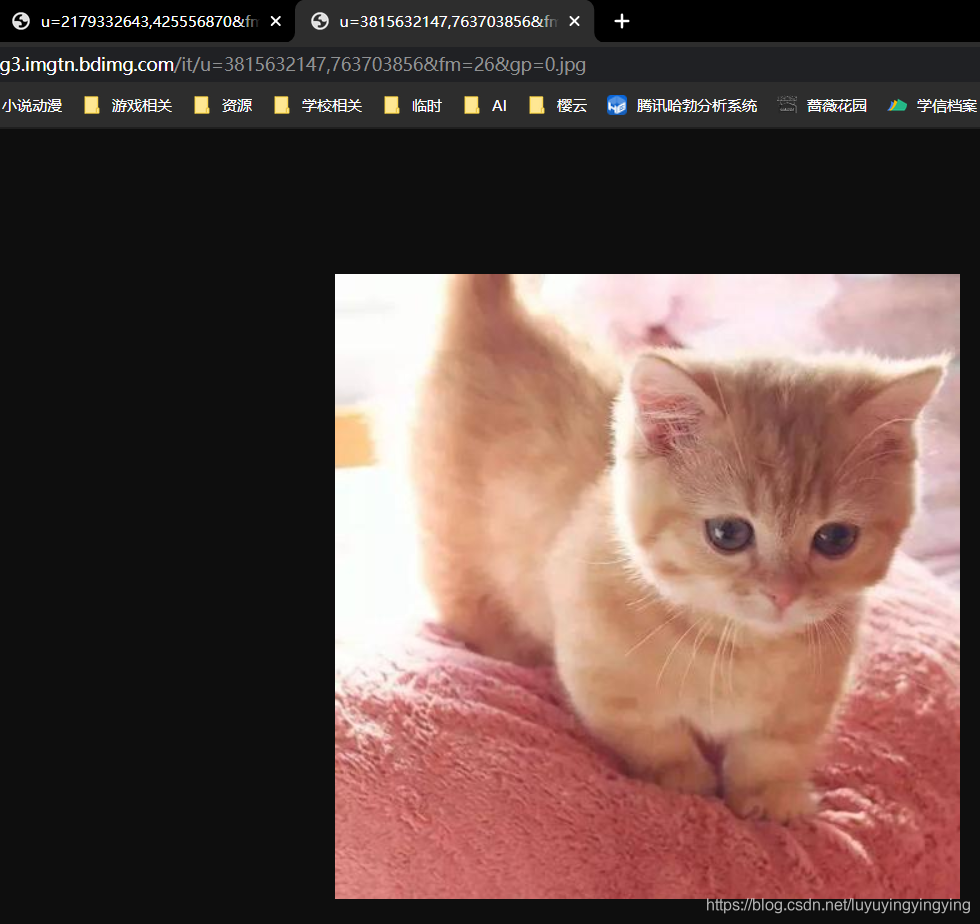 下一步就是要下载这些图片了 还记得我们之前在主函数中写的url吗 那个url下面只有30张图片,所以我们要把url重新写一下 我们下拉网页,可以看到这里出现了很多长得非常像的url
下一步就是要下载这些图片了 还记得我们之前在主函数中写的url吗 那个url下面只有30张图片,所以我们要把url重新写一下 我们下拉网页,可以看到这里出现了很多长得非常像的url 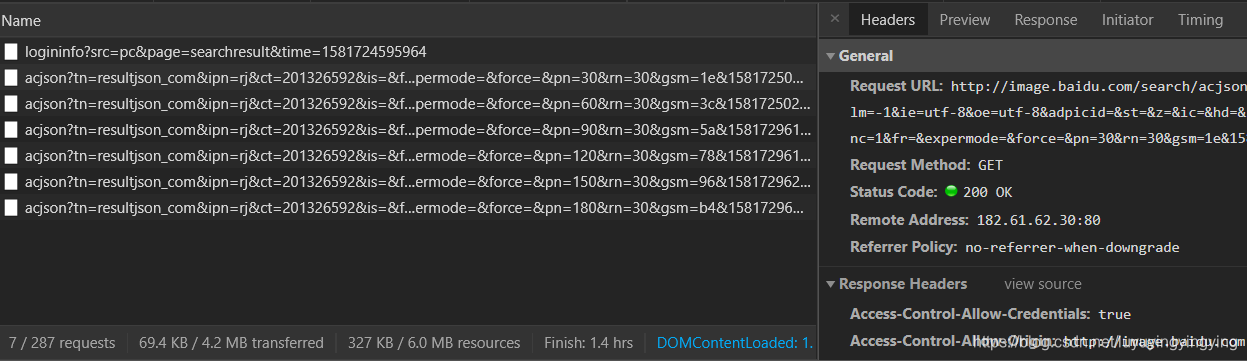 我们把这些url都复制下来,分析一下
我们把这些url都复制下来,分析一下 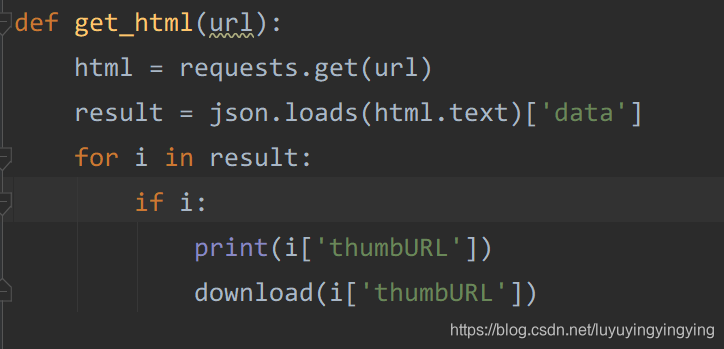 运行,我们便可以看到图片被下载下来了
运行,我们便可以看到图片被下载下来了  但是我们发现,这个图片打不开
但是我们发现,这个图片打不开  事实上,这是因为服务器识别出了你的爬虫,阻止了它的下载行为 那么,我们如何绕过这个识别呢? 只要我们把爬虫伪装成人就可以了 正常我们是通过浏览器访问网站的,浏览器在向网站发送get请求的时候,会同时发送一个请求头
事实上,这是因为服务器识别出了你的爬虫,阻止了它的下载行为 那么,我们如何绕过这个识别呢? 只要我们把爬虫伪装成人就可以了 正常我们是通过浏览器访问网站的,浏览器在向网站发送get请求的时候,会同时发送一个请求头 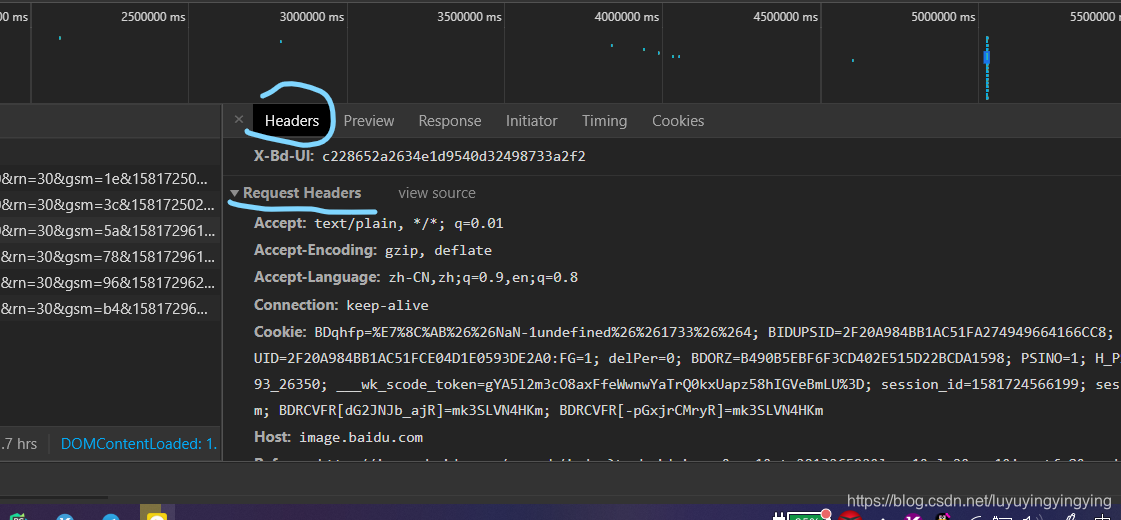 这个request headers 我们只要在get的时候,发送和浏览器一样的请求头就可以了。 我们需要的主要是三个参数
这个request headers 我们只要在get的时候,发送和浏览器一样的请求头就可以了。 我们需要的主要是三个参数  refeter表示请求的来源,我是从哪个链接来到这个链接的 User-Agent是浏览器的标识 X-Requested-With是让服务器识别是Ajax请求还是普通的请求 将这个三个参数,写进一个字典即可
refeter表示请求的来源,我是从哪个链接来到这个链接的 User-Agent是浏览器的标识 X-Requested-With是让服务器识别是Ajax请求还是普通的请求 将这个三个参数,写进一个字典即可 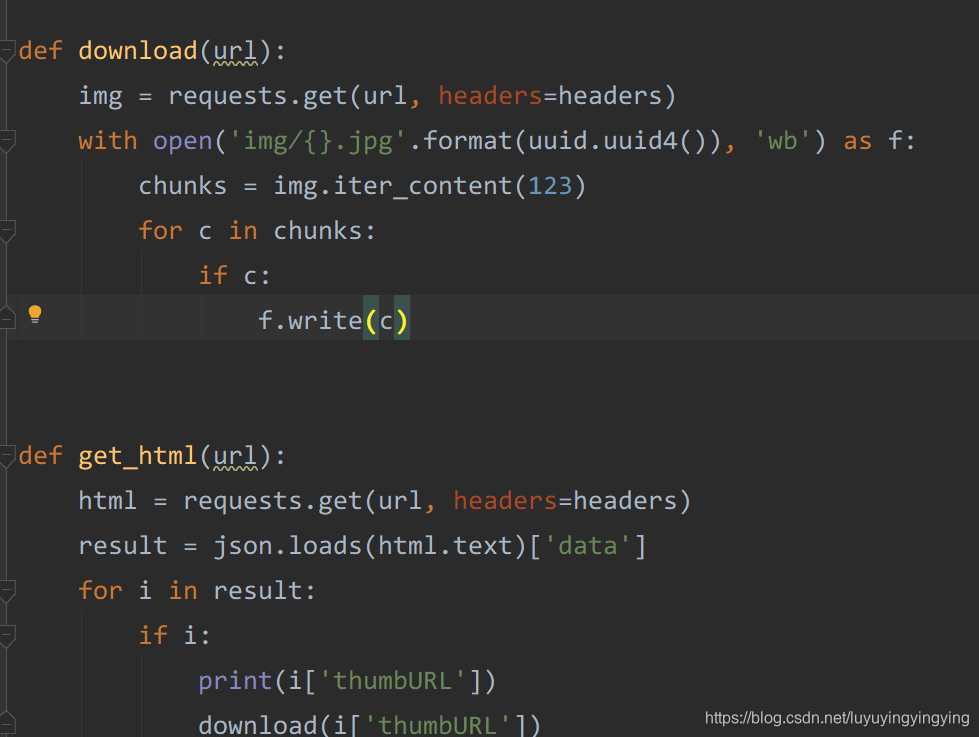 这时,我们在运行,就可以发现我们成功下载下来图片了
这时,我们在运行,就可以发现我们成功下载下来图片了可以开始吸猫了 
 在获取页面的时候,有可能它的data下面没有数据,这时候就会报错导致程序停止运行,所以我们加一个try
在获取页面的时候,有可能它的data下面没有数据,这时候就会报错导致程序停止运行,所以我们加一个try 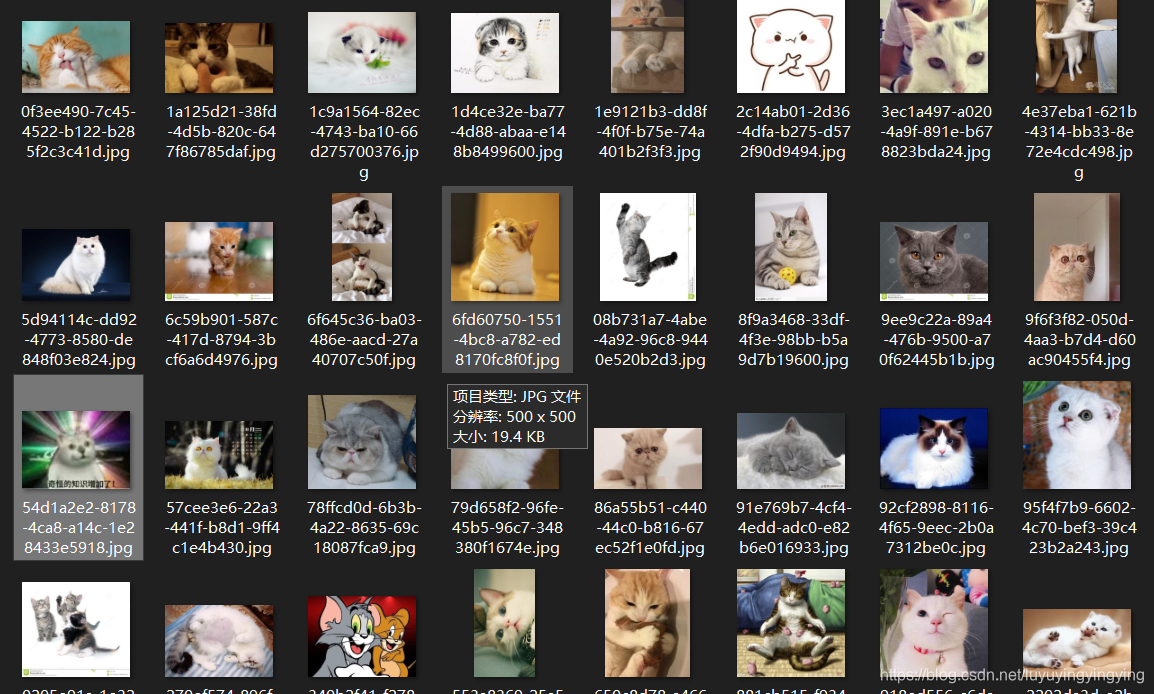
 requests中除了可以加请求头,还可以加代理ip 代理的获取可以百度搜“快代理”和“西刺代理”
requests中除了可以加请求头,还可以加代理ip 代理的获取可以百度搜“快代理”和“西刺代理” 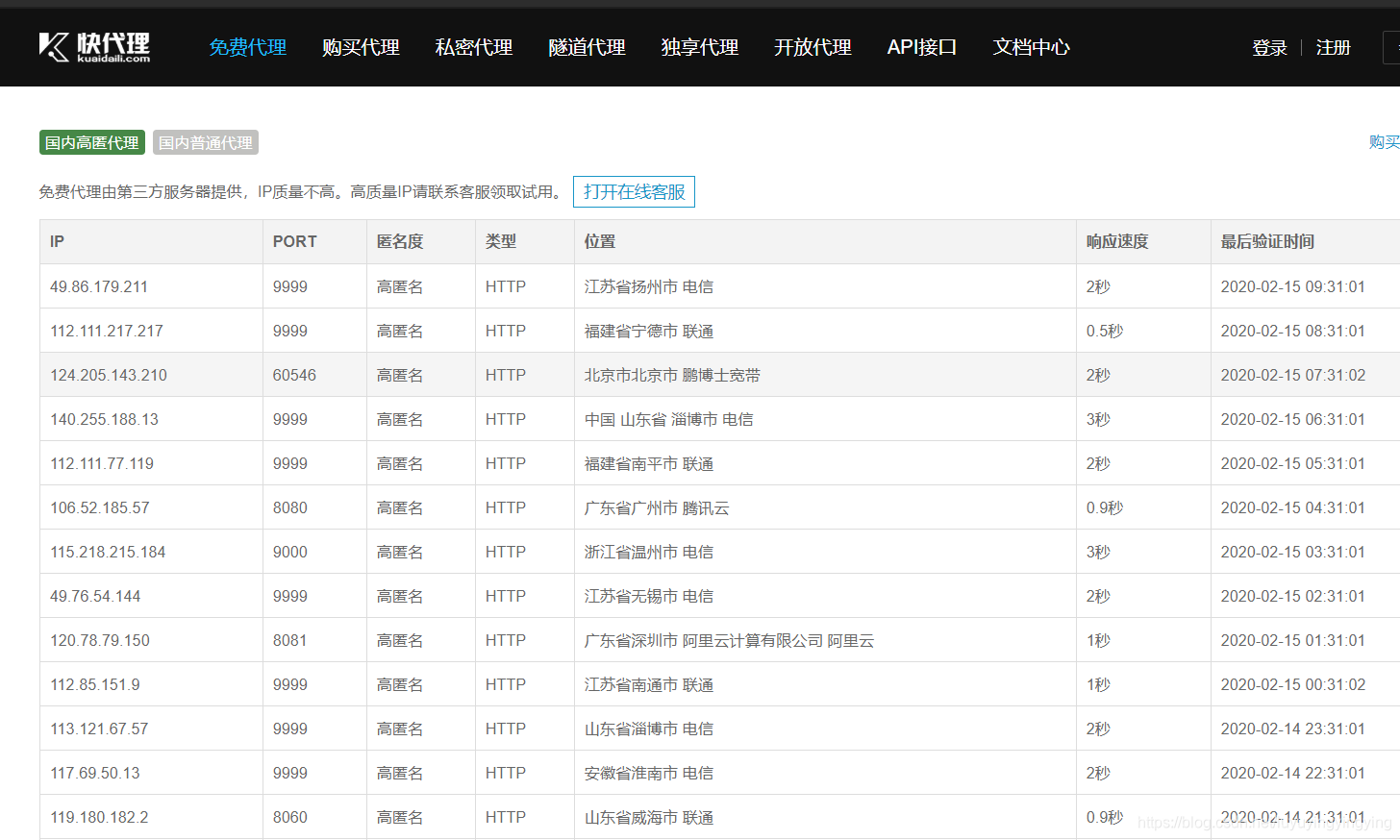 同样将代理以字典的形式写下来,然后在session里引用即可
同样将代理以字典的形式写下来,然后在session里引用即可
发布日期:2021-05-07 18:24:45
浏览次数:19
分类:精选文章
本文共 6293 字,大约阅读时间需要 20 分钟。
获取网页的信息
使用reques中的get
为了不让服务器把我们的爬虫当成机器人,我们要写一个请求头 用chrome打开百度,搜索猫的图片 然后打开这个界面 打开方式有三种: - 按F12
- 鼠标右键,点击检查
- ctrl + shift +i
我的chrome使用了一个黑色主题,所以打开后是黑色的,一般默认为白色
依次点击NetWork—XHR 由于百度图片使用了Ajax交互,只有在你下拉滚轮的时候才会显示出更多的图片,所以我们需要下拉几次滚轮 Ajax交互是一种动态的交互网页,只有在你做出向下滚动之类的操作,网页上的资源才会加载出来,并且随时需要随时加载。 可以看到,此时多出了一些内容
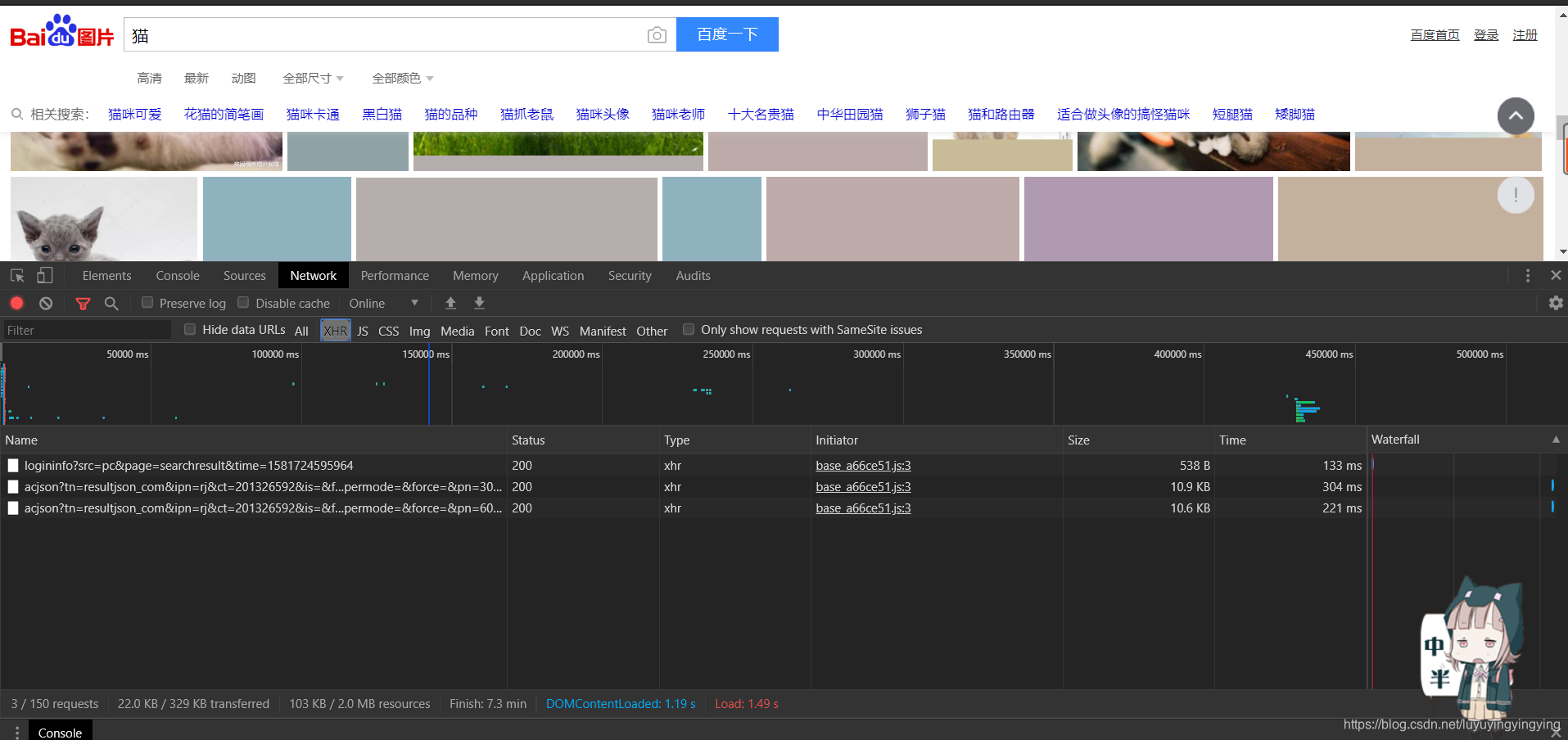
我们复制这个url,在地址栏输入,并打开,可以看到一张与猫有关的图片 找到了我们要爬取资源的规律,就可以来编写爬虫代码了 打开pycharm,新建一个文件,将requests导入
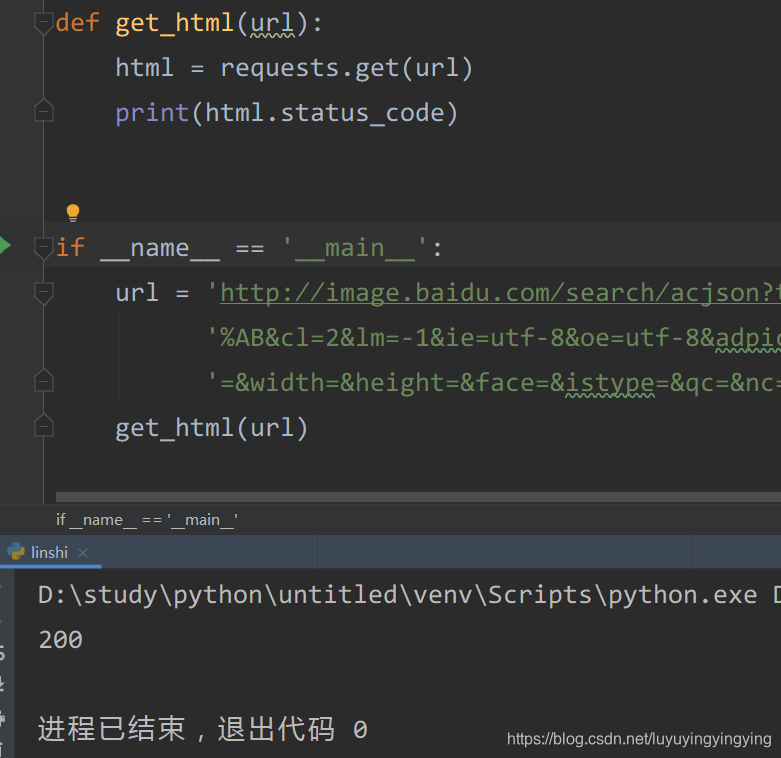
先写一个小函数,用来获取网页def get_html(url): html = requests.get(url) print(html.status_code)
根据第零篇文章可知,status_code,也就是状态码,为200时,表示我们可以正常访问
接着,我们在主函数中写下刚才网站的url url在headers中获取 if __name__ == '__main__': url = 'http://image.baidu.com/search/acjson?tn=resultjson_com&ipn=rj&ct=201326592&is=&fp=result&queryWord=%E7%8C' \ '%AB&cl=2&lm=-1&ie=utf-8&oe=utf-8&adpicid=&st=&z=&ic=&hd=&latest=©right=&word=%E7%8C%AB&s=&se=&tab' \ '=&width=&height=&face=&istype=&qc=&nc=1&fr=&expermode=&force=&pn=30&rn=30&gsm=1e&1581725024787= ' get_html(url)
然后点击main旁边的绿三角运行
可以看到,输出了200,表示我们访问成功 我们想要下载的图片的url在data里,所以我们要读取data中的数据。 这里网页上的代码是json代码,与python中的字典很相似,所以我们可以使用python中字典的方式获取json中的元素。 result = html.json()['data']
这里调用了requests中的json函数,不过requests是一个第三方的库,这里更推荐官方给出的json库,所以这里我们导入一个json,并把这句改写一下
result = json.loads(html.text)['data']
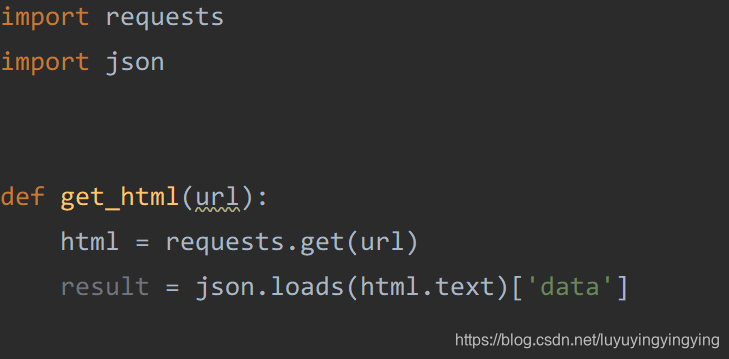
这样,我们就写好了获取图片url的函数 def get_html(url): html = requests.get(url, headers=headers) result = json.loads(html.text)['data'] for i in result: if i: print(i['thumbURL'])
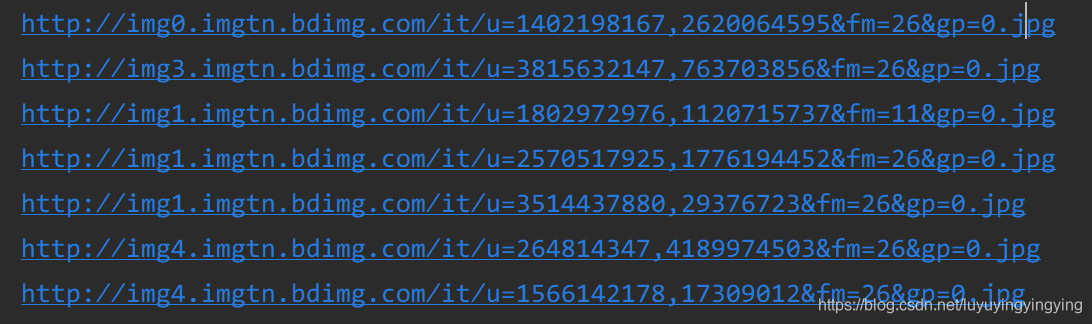
下一步就是要下载这些图片了 还记得我们之前在主函数中写的url吗 那个url下面只有30张图片,所以我们要把url重新写一下 我们下拉网页,可以看到这里出现了很多长得非常像的url 我们把这些url都复制下来,分析一下 'http://image.baidu.com/search/acjson?tn=resultjson_com&ipn=rj&ct=201326592&is=&fp=result&queryWord=%E7%8C%AB&cl=2&lm=-1&ie=utf-8&oe=utf-8&adpicid=&st=&z=&ic=&hd=&latest=©right=&word=%E7%8C%AB&s=&se=&tab=&width=&height=&face=&istype=&qc=&nc=1&fr=&expermode=&force=&pn=30&rn=30&gsm=1e&1581725024787=''http://image.baidu.com/search/acjson?tn=resultjson_com&ipn=rj&ct=201326592&is=&fp=result&queryWord=%E7%8C%AB&cl=2&lm=-1&ie=utf-8&oe=utf-8&adpicid=&st=&z=&ic=&hd=&latest=©right=&word=%E7%8C%AB&s=&se=&tab=&width=&height=&face=&istype=&qc=&nc=1&fr=&expermode=&force=&pn=60&rn=30&gsm=3c&1581725025100=''http://image.baidu.com/search/acjson?tn=resultjson_com&ipn=rj&ct=201326592&is=&fp=result&queryWord=%E7%8C%AB&cl=2&lm=-1&ie=utf-8&oe=utf-8&adpicid=&st=&z=&ic=&hd=&latest=©right=&word=%E7%8C%AB&s=&se=&tab=&width=&height=&face=&istype=&qc=&nc=1&fr=&expermode=&force=&pn=90&rn=30&gsm=5a&1581729618142='
通过分析我们可以看到,pn这一个参数以每30为间隔增长,那么,获取图片最主要的就是靠pn这个参数了。
所以,我们对url进行一下改写,每次改变pn的值,并且每次增加30url = ['http://image.baidu.com/search/acjson?tn=resultjson_com&ipn=rj&ct=201326592&is=&fp=result&queryWord=%E7%8C' \ '%AB&cl=2&lm=-1&ie=utf-8&oe=utf-8&adpicid=&st=&z=&ic=&hd=&latest=©right=&word=%E7%8C%AB&s=&se=&tab' \ '=&width=&height=&face=&istype=&qc=&nc=1&fr=&expermode=&force=&pn={}&rn=30&gsm=1e&1581725024787= '.format(i) for i in range(30, 100, 30)] 将url改写为一个列表,并且每次让pn后面的值增加30
这样,我们就可以一下获取90个图片的url接下来是下载。
在与代码相同的目录下面,新建一个名为img的文件夹 为了给下载的图片进行重命名,我们可以使用一个叫uuid的库,它可以生成随机数def download(url): img = requests.get(url) with open('img/{}.jpg'.format(uuid.uuid4()), 'wb') as f: chunks = img.iter_content(123) for c in chunks: if c: f.write(c) iter_content里面填的是字节大小,可以控制读写速度,减轻cpu的压力
再在get_html里调用download 运行,我们便可以看到图片被下载下来了 但是我们发现,这个图片打不开 事实上,这是因为服务器识别出了你的爬虫,阻止了它的下载行为 那么,我们如何绕过这个识别呢? 只要我们把爬虫伪装成人就可以了 正常我们是通过浏览器访问网站的,浏览器在向网站发送get请求的时候,会同时发送一个请求头 这个request headers 我们只要在get的时候,发送和浏览器一样的请求头就可以了。 我们需要的主要是三个参数 refeter表示请求的来源,我是从哪个链接来到这个链接的 User-Agent是浏览器的标识 X-Requested-With是让服务器识别是Ajax请求还是普通的请求 将这个三个参数,写进一个字典即可 headers = { 'X-Requested-With': 'XMLHttpRequest', 'User-Agent': 'Mozilla/5.0 (Windows NT 10.0; Win64; x64) AppleWebKit/537.36 (KHTML, like Gecko) Chrome/80.0.3987.106 Safari/537.36', 'Referer': 'http://image.baidu.com/search/index?tn=baiduimage&ps=1&ct=201326592&lm=-1&cl=2&nc=1&ie=utf-8&word=%E7%8C%AB'} 然后,在两个函数的get中引headers
这时,我们在运行,就可以发现我们成功下载下来图片了 还没完,别急着走!
在编写的过程中,我们每个get里都要引用headers,能不能少写一点代码?
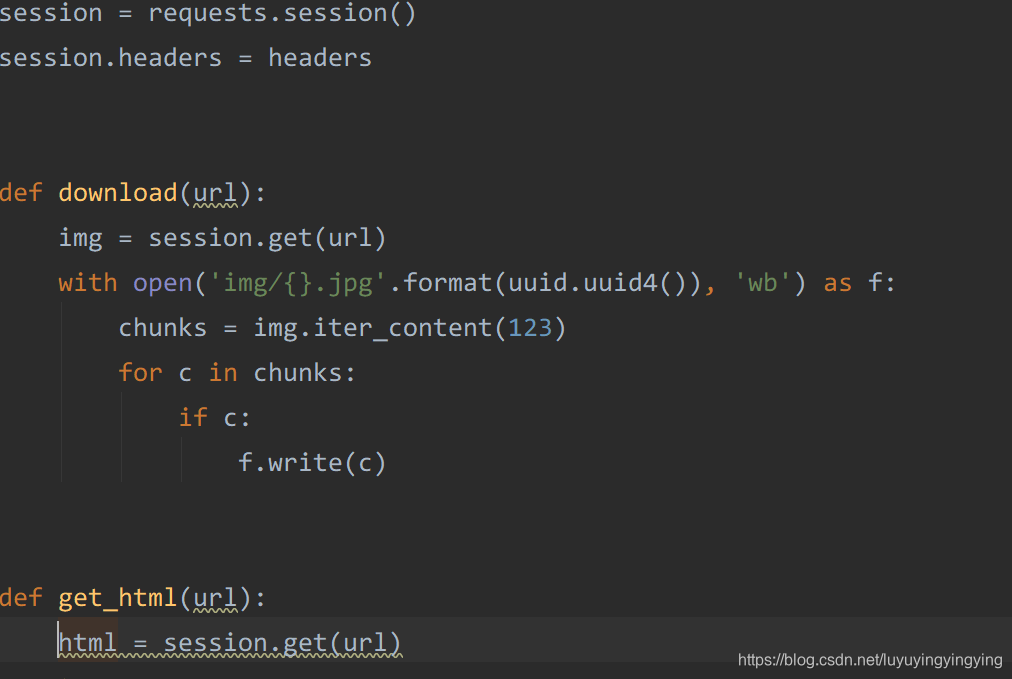
能! requests中有一个session(),它可以帮我们保存headers 它还有两个好处,那就是维持会话,以及自动保存cookies 所以,我们改写一下代码session = requests.session()session.headers = headers
然后,把后面函数中的requests换成session,并把headers引用删掉
在获取页面的时候,有可能它的data下面没有数据,这时候就会报错导致程序停止运行,所以我们加一个try def get_html(url): html = session.get(url) try: result = json.loads(html.text)['data'] for i in result: if i: print(i['thumbURL']) download(i['thumbURL']) except Exception as e: print(e)
运行
requests中除了可以加请求头,还可以加代理ip 代理的获取可以百度搜“快代理”和“西刺代理” 同样将代理以字典的形式写下来,然后在session里引用即可 proxy = { 'http': 'http://106.52.185.57:8080', 'https': 'https://106.52.185.57:8080'} 不过,在使用代理的过程中,如果代理失效的话,就会造成无法访问,从而使程序卡在这,所以,需要写一个超时跳过
在前面加上session.timeout = 3
表示超时3秒就自动放弃
完整代码
import requestsimport jsonimport uuidheaders = { 'X-Requested-With': 'XMLHttpRequest', 'User-Agent': 'Mozilla/5.0 (Windows NT 10.0; Win64; x64) AppleWebKit/537.36 (KHTML, like Gecko) Chrome/80.0.3987.106 Safari/537.36', 'Referer': 'http://image.baidu.com/search/index?tn=baiduimage&ps=1&ct=201326592&lm=-1&cl=2&nc=1&ie=utf-8&word=%E7%8C%AB'}session = requests.session()session.headers = headersdef download(url): img = session.get(url) with open('img/{}.jpg'.format(uuid.uuid4()), 'wb') as f: chunks = img.iter_content(123) for c in chunks: if c: f.write(c)def get_html(url): html = session.get(url) try: result = json.loads(html.text)['data'] for i in result: if i: print(i['thumbURL']) download(i['thumbURL']) except Exception as e: print(e)if __name__ == '__main__': url = ['http://image.baidu.com/search/acjson?tn=resultjson_com&ipn=rj&ct=201326592&is=&fp=result&queryWord=%E7%8C' \ '%AB&cl=2&lm=-1&ie=utf-8&oe=utf-8&adpicid=&st=&z=&ic=&hd=&latest=©right=&word=%E7%8C%AB&s=&se=&tab' \ '=&width=&height=&face=&istype=&qc=&nc=1&fr=&expermode=&force=&pn={}&rn=30&gsm=1e&1581725024787= '.format(i) for i in range(30, 100, 30)] for i in url: get_html(i) 发表评论
最新留言
做的很好,不错不错
[***.243.131.199]2025年03月28日 18时58分15秒
关于作者

喝酒易醉,品茶养心,人生如梦,品茶悟道,何以解忧?唯有杜康!
-- 愿君每日到此一游!
推荐文章
全局锁和表锁 :给表加个字段怎么有这么多阻碍?
2021-05-07
事务到底是隔离的还是不隔离的?
2021-05-07
@Import注解---导入资源
2021-05-07
解决ubuntu在虚拟机(VMware)环境下不能联网的问题
2021-05-07
二分查找与插入排序的结合使用
2021-05-07
892 三维形体的表面积(分析)
2021-05-07
40. 组合总和 II(dfs、set去重)
2021-05-07
16 最接近的三数之和(排序、双指针)
2021-05-07
279 完全平方数(bfs)
2021-05-07
410 分割数组的最大值(二分查找、动态规划)
2021-05-07
875 爱吃香蕉的珂珂(二分查找)
2021-05-07
450 删除二叉搜索树中的节点(递归删除节点)
2021-05-07
桌面图标的自动排列图标
2021-05-07
第十一届蓝桥杯python组第二场省赛-数字三角形
2021-05-07
数字三角形的无返回值的深度优先搜索解法
2021-05-07
完全背包问题的简化思路
2021-05-07
Jquery添加元素
2021-05-07
Jquery使用需要下载的文件
2021-05-07
Spring中如何传递参数的问题
2021-05-07
BST中某一层的所有节点(宽度优先搜索)
2021-05-07
白红宇的个人博客 - 记录点点滴滴的事 - 您是第 457221846 位访客
访问时间: 2025-04-16 07:55:51
访问IP: 3.147.103.157
Copyright © 2020 - 2025 css8.cn 京ICP备2021015314号-1
手机版