本文共 7814 字,大约阅读时间需要 26 分钟。
Flink-dataSource的种类和基本使用
前言:
对于一个flink任务,我们拿java的API层面来解释:
一个任务基本上我们分为3种
| 名称 | 作用 |
|---|---|
| dataSource | 表示flink的数据来源 |
| dataStream | 表示一个数据处理的过程,一个dataSource一旦经过某种转换,就成为了dataStream的一部分,比如fliter,flatMap等等操作(和spark的RDD相似) |
| sink | 相当于spark的action动作,就是真正触发flink任务的一个动作。 |
那么本文讲的主要是Flink的数据源头:dataSource的相关讲解。
并行的dataSource
并行的dataSource,指的是并行度为1的dataSource。
而并行度可以通过这个方法进行查看:
dataSource.getParallelism();无界集并行dataSource
socketTextStream()
从socket当中去获取文本数据的一种方法、
为了更加直观,没有使用lambda表达式。略显繁琐
public class StreamWordCount { public static void main(String[] args) throws Exception { // 1.创建一个flink stream 序执行的环境 StreamExecutionEnvironment environment = StreamExecutionEnvironment.getExecutionEnvironment(); // 2.通过这个环境创建一个抽象的的数据集dataStream // DataStreamSource<String> dataStream = environment.socketTextStream("192.168.237.130", 8888); DataStreamSource<String> dataStream = environment.socketTextStream(args[0], Integer.parseInt(args[1])); // 3.调用dataStream上的方法 ,如:transformation(可以不调用) 和sink(必须调用,类似于spark的action,提交动作)。 // 调用transformation会将一个dataStream转换为一个新的dataStream SingleOutputStreamOperator<String> dataStream2 = dataStream.flatMap(new FlatMapFunction<String, String>() { @Override public void flatMap(String line, Collector<String> out) throws Exception { // 将一行单词进行切分 String[] words = line.split(" "); for (String word : words) { // 切分后输出 out.collect(word); } } }); // 4.将单词和数字1进行组合,返回一个dataStream SingleOutputStreamOperator<Tuple2<String, Integer>> dataStream3 = dataStream2.map(new MapFunction<String, Tuple2<String, Integer>>() { @Override public Tuple2<String, Integer> map(String word) throws Exception { return Tuple2.of(word, 1); } }); // 5.进行分组聚合,根据单词进行keyBy,然后把对应的第一个数据进行累加。这里的数字是下标,对应的Tuple2<String,Integer> SingleOutputStreamOperator<Tuple2<String, Integer>> dataStream4 = dataStream3.keyBy(0).sum(1); // 到这里transformation结束 // 6.调用sink并启动 dataStream4.print(); environment.execute("StreamWordCount"); }}通过socketTextStream这种方式获取的数据集可以为无界的。
因为只要有数据从对应的socket端口中流过,那么flink就可以进行实时的运算。
有界集并行dataSource
有界的dataSource也就是,一旦任务创建,他的数据集是有限的,不会有新的数据产生,也就是说,flink不用一直执行或者等待新的数据,只要把有限的数据执行完了,程序也就停止了。
fromCollection()
用于存放数组数据的,这里为了简便,用List
顾名思义,从Collection,也就是集合当中获取数据,但是请大家注意,一般这个方法和下面的fromElements是用来测试和验证的。
为什么这么说,解释下:比如我们要做一个flink的WordCount的小demo,那么我们可能习惯的用第一种方式,也就是socketTextStream来获取数据,但是注意,这里的数据我们是需要手动从客户端当中去输入的,比较麻烦,那么如果用fromCollection这种方式,我们就可以在一开始就定义好一定的数据,比较方便。
public class SourceDemo1 { public static void main(String[] args) throws Exception { // 创建实时计算的一个执行环境 StreamExecutionEnvironment environment = StreamExecutionEnvironment.getExecutionEnvironment(); // 将客户端的集合并行化成一个抽象的数据集,通常这个方法是用作测试的,即模拟flink的数据。 // 就不需要通过socket去传递数据了 // 但是 fromElements是一个有界的数据流,一旦数据处理完,就会退出。 DataStream<Integer> nums = environment.fromCollection(Arrays.asList(1, 2, 3, 4, 5, 6, 7, 8, 9)); // 这里结果是1,并行度为1,就代表只有一个subTask来产生数据。 System.out.println("=========" + nums.getParallelism() + "========="); DataStream<Integer> sum = nums.filter(new FilterFunction<Integer>() { @Override public boolean filter(Integer value) throws Exception { return value % 2 == 0; } }); sum.print(); environment.execute("SourceDemo1"); }}fromElements()
指定存放相应的元素作为数据源。
public class SourceDemo1 { public static void main(String[] args) throws Exception { // 创建实时计算的一个执行环境 StreamExecutionEnvironment environment = StreamExecutionEnvironment.getExecutionEnvironment(); // 创建抽象的数据集【创建原始的抽象数据集的方法,Source】 DataStream<Integer> nums = environment.fromElements(1, 2, 3, 4, 5, 6, 7, 8, 9); // 这里结果是1,并行度为1,就代表只有一个subTask来产生数据。 System.out.println("=========" + nums.getParallelism() + "========="); DataStream<Integer> sum = nums.filter(new FilterFunction<Integer>() { @Override public boolean filter(Integer value) throws Exception { return value % 2 == 0; } }); sum.print(); environment.execute("SourceDemo1"); }}到这里为止,以上的3种dataSource的并行度都为1,接下来介绍并行度不是1的dataSource
非并行的dataSource
非并行的dataSource指的是并行度>1的dataSource
fromParallelCollection()
public class SourceDemo2 { public static void main(String[] args) throws Exception { // 创建实时计算的一个执行环境 StreamExecutionEnvironment environment = StreamExecutionEnvironment.getExecutionEnvironment(); // 创建抽象的数据集【创建原始的抽象数据集的方法,Source】 DataStreamSource<Long> nums = environment.fromParallelCollection(new NumberSequenceIterator(1, 10), Long.class); System.out.println("=========" + nums.getParallelism() + "========="); // DataStream<Integer> nums = environment.fromElements(1, 2, 3, 4, 5, 6, 7, 8, 9); SingleOutputStreamOperator<Long> sum = nums.filter(new FilterFunction<Long>() { @Override public boolean filter(Long value) throws Exception { return value % 2 == 0; } }); sum.print(); environment.execute("SourceDemo2"); }}注意:fromParallelCollection需要指定类型为Long
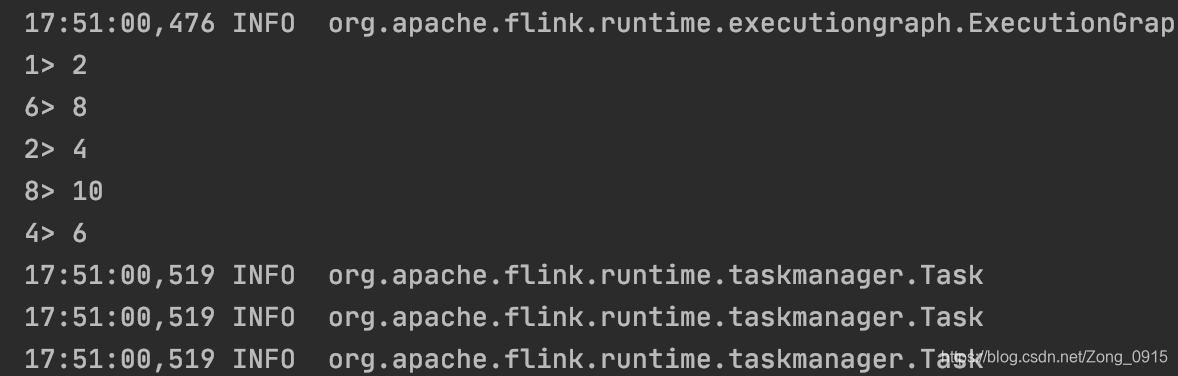
最终打印的部分结果如下:
输出的并行度为8

输出的数据
顺便提一下,这里的输出的格式问题:
- 第一列代表的是subTask的编号+1
- 第二列代表的是输出的结果(我们demo里面输出的是偶数)
generateSequence()
只需要把这一部分改为:
DataStreamSource<Long> nums = environment.generateSequence(1,100);即可,那么代表数据源为1到100的整型。
readTextFile()
从文件当中去获取数据,也是属于有界集的dataSource
代码部分:
public class TextFileSource { public static void main(String[] args) throws Exception { StreamExecutionEnvironment environment = StreamExecutionEnvironment.getExecutionEnvironment(); DataStreamSource<String> dataStreamSource = environment.readTextFile(args[0]); // 获取并行度 int parallelism = dataStreamSource.getParallelism(); System.out.println("-------------->:" + parallelism); SingleOutputStreamOperator<Tuple2<String, Integer>> words = dataStreamSource.flatMap(new FlatMapFunction<String, Tuple2<String, Integer>>() { @Override public void flatMap(String line, Collector<Tuple2<String, Integer>> out) throws Exception { String[] words = line.split(" "); for (String word : words) { out.collect(Tuple2.of(word, 1)); } } }); System.out.println("===============>:" + words.getParallelism()); SingleOutputStreamOperator<Tuple2<String, Integer>> sum = words.keyBy(0).sum(1); sum.print(); environment.execute("TextFileSource"); }}设置部分:
点击设置:
加上你文件的地址:
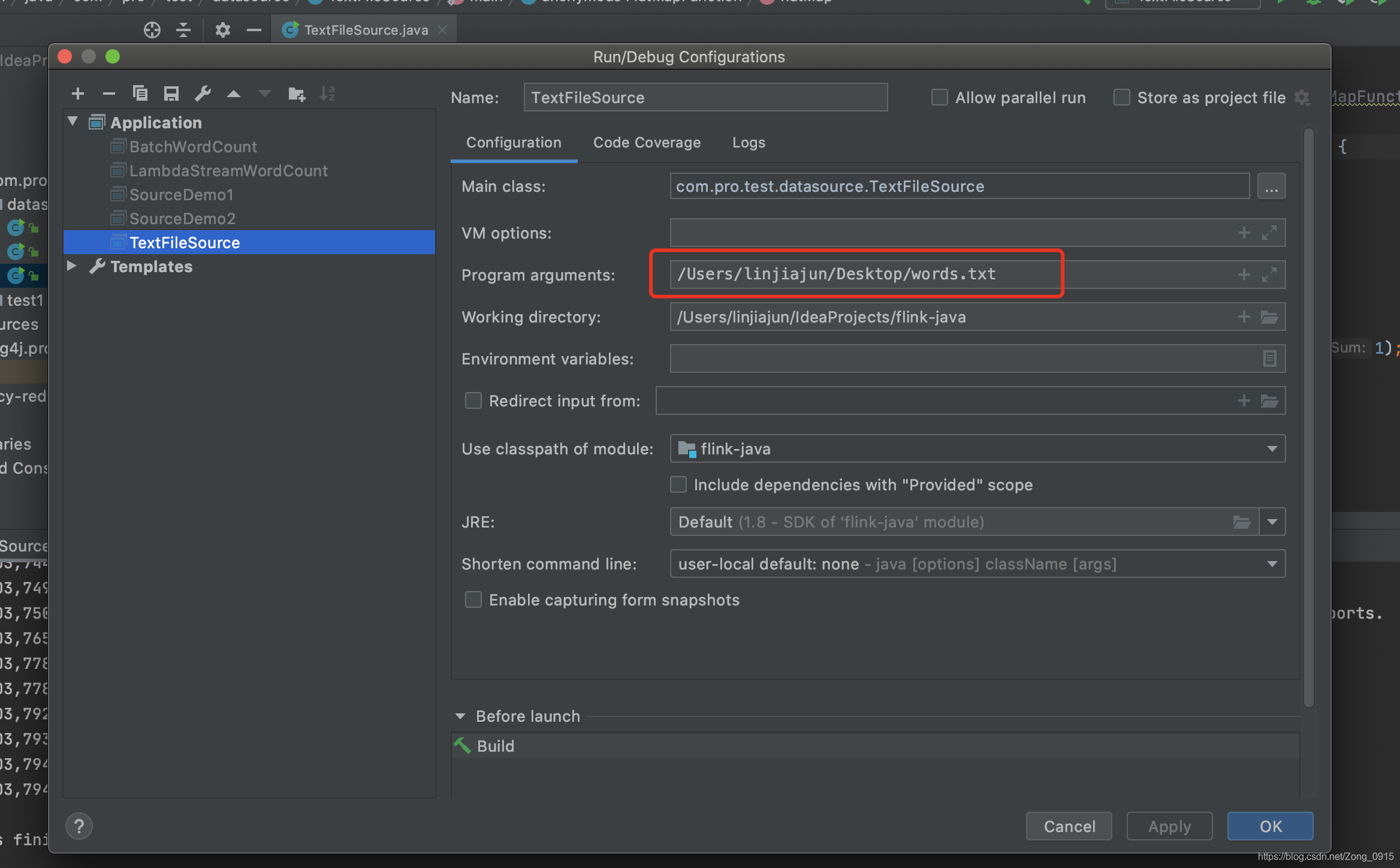
我这里的地址是桌面的一个叫words.txt的文件

注意:一定要配置完后,再执行代码,否则报错
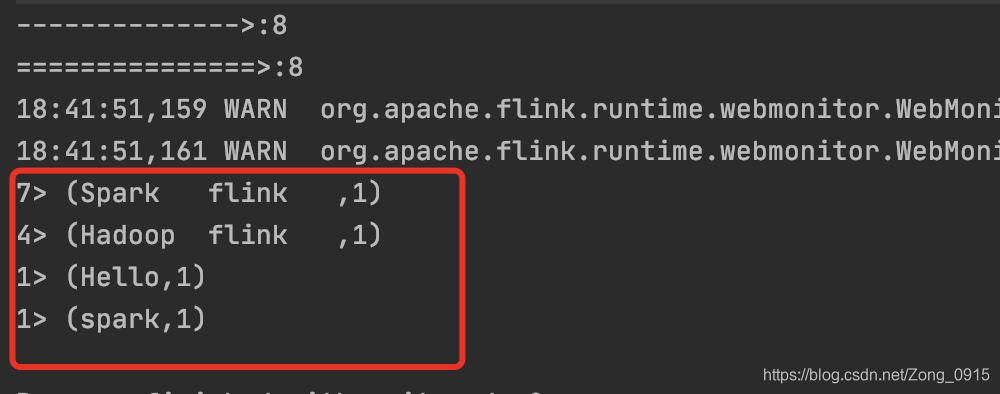
输出结果:
小结
dataSource分为有界集和无界集:
所以flink也可以做离线计算,也可以做实时计算
-
如果数据是有界集,一般用的执行环境为ExecutionEnvironment,数据量是定死的,flink做的是离线计算。(哪怕用的是实时的StreamExecutionEnvironment,但是数据一旦计算完毕,程序就会停止,所以相当于还是做得离线计算,就是批计算)
-
如果数据是无限集,一般用的执行环境为StreamExecutionEnvironment,Flink也就是做实时的流计算。
-
dataSource根据环境environment的不同方法,可以分为并行dataSource和非并行dataSource。
-
并行的dataSource也就是 并行度>1的,通俗来讲就是允许多个线程(多个subTask,subTask为真正执行的一个单位)去同时分配的执行这个任务。而非并行的dataSource也就是并行度为1的,只有1个线程去执行。
| - | 并行 | 非并行 | 是否可以作为无界集(用于实时的流处理) |
|---|---|---|---|
| socketTextStream() | Y | ----- | Y |
| fromCollection() | Y | ----- | N(一般用于测试) |
| fromElements | Y | ----- | N |
| fromParallelCollection | ----- | Y | N |
| generateSequence | ----- | Y | N |
| readTextFile | ----- | Y | Y |
这张表格的数据不一定准确(是否可以作为无界集),因为严格来说,只要数据源源不断的进入,比如在你程序结束前就有新的数据添加了,那么就是一个流处理。流处理的时间也有长有短,因此也不能随意下结论。
这里提供一个参考。
比如readTextFile,假如从Hdfs当中读取文件,而另一方面又有类似于spark,hadoop,ES等地方,不断的往Hdfs当中存放数据,那么Flink也是做的流处理。如果像本文当中的demo,那么就是一个离线处理了。所以大家要合理的思考这个事情。
发表评论
最新留言
关于作者
