python之模块
发布日期:2021-05-04 19:07:26
浏览次数:17
分类:原创文章
本文共 7024 字,大约阅读时间需要 23 分钟。
python之模块
文章目录
一、模块介绍
1.什么是模块
- 模块就是一系列功能的集合体
2.模块的四种形式
- 使用python写的.py文件,例如:文件名
pop.py,模块名为’pop’ - 盛放有多个
py文件的文件夹也是一个功能的集合体, 相当于一种超级模块, 称之为包 - 已被编译为共享库或DLL的C或C++扩展
- 使用
C编写并链接到 Python 解释器的内置模块
3.模块的三种来源
- 自带的模块
- 内置模块
- 标准库
- 第三方模块
- 可以通过 pip 工具下载的别人写的一些优秀的模块
- 例 :
pip3 install requests
- 自定义模块
4.为何要用模块
- 使用自带或第三方模块 : 写好的功能拿来就用, 提升开发效率
- 使用自定义模块 : 减少代码冗余, 让程序的组织结构更清晰
4.导入模块
引用模块内内容时,关于名称空间需要注意的问题
**模块的核心:**名称空间的嵌套关系是在定义阶段就确定的,与调用位置无关
示例
- 以下讲解部分都以此代码示例
spam.py文件
print("i am app") # 只要执行此文件就会打印 "i am spam"x = 1000def aaa(): print("i am spam.aaa")def bbb(): print("i am spam.bbb") aaa()def change(): global x x = 0run.py执行文件
import app # 导入模块先执行一次被导入模块文件, 会打印 "i am app"import app # 之后的导入都是直接引用第一次导入的结果, 不会重复执行文件x = 2000 # 当前执行文件下的变量 "x"app.aaa() # 使用模块的 "aaa" 功能, 打印 "i am app.aaa"app.bbb() # 使用模块的 "bbb" 功能, 打印 "i am app.bbb" 并调用模块的 "aaa" 打印 "i am app.aaa"app.change() # 使用了模块的 "change" 功能,改变的是定义阶段就规定好了的去 "app" 名称空间找变量名 "x"print(x) # 所以这里打印的还是 "run.py" 的 "x" : 2000print(app.x) # 而 "app.py" 里面的 "x" : 0二、import模块的使用
1.首次导入模块发生的三件事
- 创建一个模块的名称空间
- 执行模块对应文件, 将执行文件产生的名字存放于这个名称空间中
- 在当前执行文件中拿到一个模块名, 该模块名指向被导入模块的名称空间
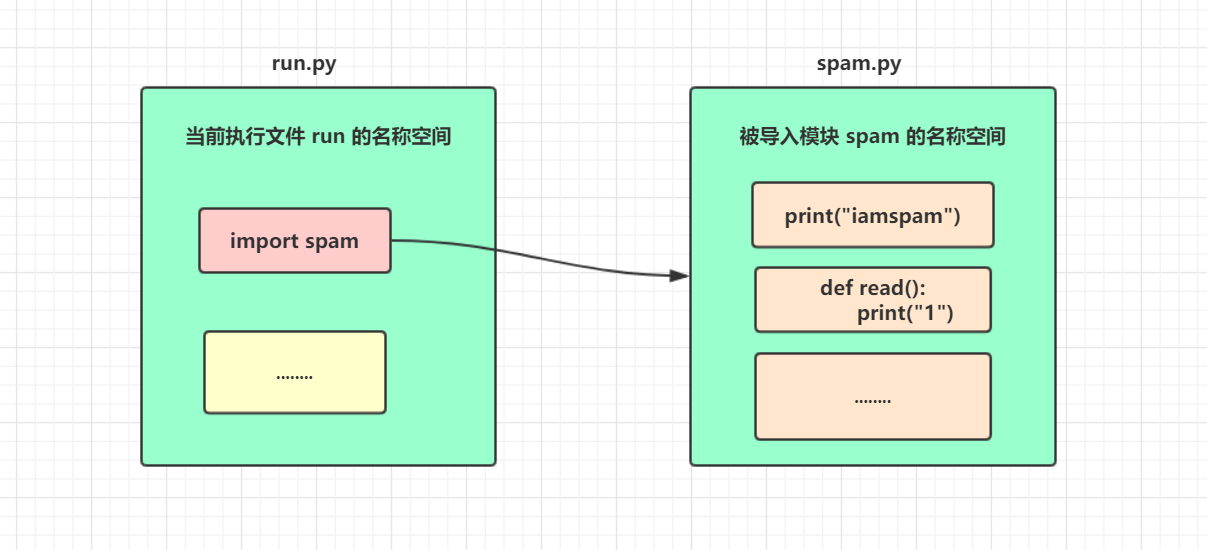
2.import模块的使用
- 强调 : 只有首次导入才会执行被导入模块文件, 并创建一个名称空间
- 之后的导入都是直接引用首次导入的结果
- 模块中功能的执行始终以模块自己的名称空间为准
#run.py文件内容import appimport appimport appimport appimport appprint(app) # <module 'app' from 'F:\\python_16\\day 31\\app.py'>app.aaa()'''输出内容i am app<module 'app' from 'F:\\python_16\\day 31\\app.py'>i am app.aaa'''2.1引用模块:如何引用?
文件foo.py文件内容
x=9999def get(): print(x)def change(): x=666 print(x)- 强调一: 指名道姓地问某一个模块要名字对应的值,不会与当前名称空间的名字发生冲突。
# run.py文件内容print(foo.x)print(foo.get)print(foo.change)'''输出内容9999<function get at 0x000001DEE086B4C0><function change at 0x000001DEE097F040>'''强调二: 无论是查看还是修改操作的都是模块本身, 与调用位置无关。(提示: 名称空间的嵌套关系是在定义阶段就确定的。)-
强调二: 无论是查看还是修改操作的都是模块本身, 与调用位置无关。(提示: 名称空间的嵌套关系是在定义阶段就确定的。)
#run.py文件内容import foox = 33333333foo.get()print(x)foo.change()print(x)'''输出内容99993333333366633333333'''
2.2总结:import 的优缺点
- 优点:指名道姓的引用某个模块的名字, 不会有冲突
- 缺点:需要加前缀, 引用次数多的时候就比较麻烦
2.3为模块取别名
as一般用于你的模块名比较长的情况下
import app as ssimport taoxiaoxin as kangkangimport abcdefghijkmnopqrstuvwxyz as super_man2.4导入多个模块
# 不推荐使用import os, sys, time# 推荐使用(清晰明了)import osimport sysimport time# 导入模块规范先写: Python内置模块在写: 第三方模块最后写: 自定义模块import osimport sysimport 第三方import spam2.5可以在函数体内导入模块
def func(): import foo三、模块使用之from…import 语句用法
1.首次导入模块发生的三件事
- 创建一个模块的名称空间
- 执行对应文件, 将产生的名字存放于刚创建的名称空间中 (前两个步骤与 import 一样)
- 在当前名称空间中拿到模块中的名字, 可以直接使用, 不用加任何前缀
2.from…import 语句用法
- 同
import一样,执行模块中的功能,始终以模块的名称空间为准
from app import aaa, bbb, changeprint(aaa)aaa()bbb() #可以直接调用change() #不需要写前缀3.from…import 的优缺点
- 优点:不用加前缀,直接引用模块中的名字,代码更精简
- 缺点: 容易与当前执行文件名称空间中的重复名字发生冲突
4.为模块取别名
- 注意:一般用于名字过长的情况下
# 注意: 一般用于名字过长的情况下from qwertyuiopasdfghjklzxcvbnm as super_man# 使用不推荐一行导入多个功能的方式的as示例(了解)from aaa.foo import x as ok, get as ok1, change as ok25.导入多个模块功能
from...improt * # "*" 代表所有from spam import *aaa()bbb()change()-
可以使用
__all__功能规定只能使用的模块# 比如在 "spam.py" 文件中加入__all__=["aaa","change"]# 那么在另一个文件中导入这个文件就只能使用这两个规定的名字
四、其他导入语法(as)
我们还可以在当前位置为导入的模块起一个别名
import foo as f #为导入的模块foo在当前位置起别名f,以后再使用时就用这个别名ff.xf.get()还可以为导入的一个名字起别名
from foo import get as get_xget_x()通常在被导入的名字过长时采用起别名的方式来精简代码,另外为被导入的名字起别名可以很好地避免与当前名字发生冲突,还有很重要的一点就是:可以保持调用方式的一致性,例如我们有两个模块json和pickle同时实现了load方法,作用是从一个打开的文件中解析出结构化的数据,但解析的格式不同,可以用下述代码有选择性地加载不同的模块
if data_format == 'json': import json as serialize #如果数据格式是json,那么导入json模块并命名为serializeelif data_format == 'pickle': import pickle as serialize #如果数据格式是pickle,那么导入pickle模块并命名为serializedata=serialize.load(fn) #最终调用的方式是一致的五、补充说明
在python 中模块也与函数对象一样。模块可以赋值, 模块可以当做参数, 可以当做返回值, 模块可以充当容器类型的元素。
模块名的书写规范:
- 自定义的模块名应该采用纯小写加下划线的风格
模块名应该遵循小写形式,标准库从python2过渡到python3做出了很多这类调整,比如ConfigParser、Queue、SocketServer全更新为纯小写形式。六、一个py文件有两种用途
-
一个python文件有两种用途
- 脚本 : 一个文件就是整个程序, 用来被执行
- 模块 : 文件中存放着一堆功能, 用来被导入使用
-
执行py文件与导入py文件的区别
- 执行py文件: 程序执行结束后名称空间被回收
- 导入py文件: 当不再被引用时名称空间被回收(提示: python中对于模块级别的引用做了优化, 如果是模块级别的名称空间在没有被引用的情况下, 并不久立刻回收)
-
python内置变量
__name__:为了区分同一个文件的不同用途, 每个py文件都内置了
__name__变量, 该变量在py文件被当做脚本执行时赋值为__main__, 在被当做模块导入时赋值为模块名.-
__name__作用:- 当作项目的执行文件入口时使用. 声明该文件是被执行的, 不是被导入的.
- 测试该文件的功能的时候使用
-
伪代码实例:
if __name__ == '__main__': 被当做脚本运行时的代码else: 被当做模块导入时运行的代码
-
六、循环导入问题
什么是循环导入问题?
- 模块循环/嵌套导入抛出异常的根本原因是由于在python中模块被导入一次之后,就不会重新导入,只会在第一次导入时执行模块内代码。
导入异常演示
-
文件: run.py, m1.py, m2.py
# "run.py"文件内容import m1m1.f1()# "m1.py"文件内容print('正在导入m1')from m2 import yx='m1'# "m2.py"print('正在导入m2')from m1 import xy='m2''''1.测试一 : 执行"run.py"执行"run.py",导入"m1", 并运行其内部代码, 打印"m1"内容"正在导入m1"接着开始导入"m2"并运行其内部代码, 打印内容"正在导入m2""m2"中又导入"m1"由于"m1"已经被导入过了,所以不会重新导入于是直接去'm1'中获取"x",然而"x"此时还没来的急定义在"m1"中,所以报错2.测试二 : 执行"m1.py"执行"m1.py",打印"正在导入m1",开始导入"m2"模块进而执行"m2.py"内部代码打印"正在导入m2",导入"m1"模块,此时"m1"是第一次被导入,打印"正在导入m1"紧接着执行"from m1 import y",由于"m2"已经被导入过了,所以直接向"m2"获取"y"然而"y"此时并没有来得及定义在"m2"中, 所以报错'''
解决方法
- 我们的项目中应该尽量的避免出现循环 / 嵌套调用
- 如果有多个模块都需要使用共同的功能, 应该将其放入到一个共享文件里去
- 如果程序已经出现了循环 / 嵌套调用, 解决方法如下👇👇👇
1.方法一 : 将导入语句放入最后# "m1.py"文件print('正在导入m1')x='m1'from m2 import y# "m2.py"文件print('正在导入m2')y='m2'from m1 import x2.方法二 : 将导入语句放入函数中# "m1.py"文件print('正在导入m1')def f1(): from m2 import y print(y)x='m1'# "m2.py"文件print('正在导入m2')def f2(): from m1 import x print(x)y='m2'七、搜索模块的优先级与路径
模块的查找优先级
-
内存中已经加载的模块
-
内置模块
-
sys.path 路径中包含的模块
-
补充说明:
如果你这个sys.path所有的文件夹下没有你当前导入模块的文件,那么你可以往sys.path中添加你要导入的模块对于的文件所在的文件夹路径。(注意: 是文件夹) 添加方式: sys.path.append(r'路径') 如果路径是在windows中一定要在路径前加一个小r. 这里之所以用append,不用insert。因为默认的路径是要到你当前执行文件的文件夹下查找而不是应该用你去指定文件夹下去查找, 我们要准守这种规范。
-
**注意:**模块的导入查找的起始点就是当前执行文件所在的目录
内存优先级示例
import timeimport m1 # 导入 m1m1.f1() # 已经读到内存里面time.sleep(15) # 在15秒之内删除 m1.pyimport m1 # 这一行还可以调用m1.f1() # 没有影响内置模块优先级测试
- 新建一个自定义
time.py文件 - 在run.py里面调用自定义的模块(需要特别注意的是:我们自定义的模块名不应该与系统内置模块重名)
# "time.py"文件内容print("这是自定义模块")# "run..py"文件内容import time # 首次导入print(time.time()) # 1607586947.3936024# 执行该文件, 发现并没有打印 "这是自定义模块", 而是触发了内置模块"time"的功能sys.path 环境变量介绍
-
查看sys环境变量
import sysprint(sys.path)'''['F:\\python_16\\day 13', 'F:\\python_16', 'F:\\PyCharm\\plugins\\python\\helpers\\pycharm_display', 'F:\\Python38\\python38.zip', 'F:\\Python38\\DLLs', 'F:\\Python38\\lib', 'F:\\Python38', 'F:\\Python38\\lib\\site-packages', 'F:\\PyCharm\\plugins\\python\\helpers\\pycharm_matplotlib_backend']'''#解释说明'''# 可以发现是一个列表 (代表着可以使用 "append" 功能向里面添加路径)# 第一个路径是当前执行文件所在的目录# 第二个是整个项目的路径, "PyCharm" 的优化 (在别的编辑器上没有,可以忽略)# 第四个是 "zip" 格式压缩包, 其实它也是一种文件夹 (想想他里面放的也是一堆文件)# 其他的一些都是第三方库或者自定义下载的模块'''
ps : 添加文件路径到 sys 环境变量
import syssys.path.append("[文件路径]")#示例:import syssys.path.append("F:\python_16\day 13")print(sys.path[-1]) # F:\python_16\day 13八、编写一个模块的规范
"""我们在编写py文件时,需要时刻提醒自己,该文件既是给自己用的,也有可能会被其他人使用,因而代码的可读性与易维护性显得十分重要,为此我们在编写一个模块时最好按照统一的规范去编写,如下"""# !/usr/bin/env python # 通常只在类unix环境有效,作用是可以使用脚本名来执行,而无需直接调用解释器。# -*- coding: 与存入硬盘字符编码一致 -*-"The module is used to..." # 模块的文档描述import sys # 导入模块x=1 # 定义全局变量,如果非必须,则最好使用局部变量,这样可以提高代码的易维护性,并且可以节省内存提高性能class Foo: # 定义类,并写好类的注释 'Class Foo is used to...' passdef test(): # 定义函数,并写好函数的注释 'Function test is used to…' passif __name__ == '__main__': # 主程序 test() #在被当做脚本执行时,执行此处的代码发表评论
最新留言
做的很好,不错不错
[***.243.131.199]2025年04月08日 20时01分22秒
关于作者

喝酒易醉,品茶养心,人生如梦,品茶悟道,何以解忧?唯有杜康!
-- 愿君每日到此一游!
推荐文章
最小生成树 (kruskal)
2019-03-04
数据结构与算法总结(3)
2019-03-04
Java基础语法
2019-03-04
404服务器错误的讲解
2019-03-04
原创-开发问题指南
2019-03-04
python学习--Django学习4、数据库的增删改查、django后台管理系统
2019-03-04
Django开发车辆违章系统、模糊查询、分页查询
2019-03-04
centos7.5 装Python3.7报错(解决办法)
2019-03-04
Java常用设计模式之单例模式
2019-03-04
线性扫描--求数组中三个数最大乘积
2019-03-04
爬虫之 xpath的节点关系
2019-03-04
爬虫之 lxml模块的安装与使用示例
2019-03-04
Python创建目录文件夹
2019-03-04
正则表达式的概述
2019-03-04
Mongodb数据库介绍
2019-03-04
深度学习简介
2019-03-04
回文排列
2019-03-04
Linux之文件权限命令
2019-03-04
Linux之远程登录、远程拷贝命令 ssh scp
2019-03-04
python多线程的使用
2019-03-04
白红宇的个人博客 - 记录点点滴滴的事 - 您是第 454267906 位访客