本文共 5536 字,大约阅读时间需要 18 分钟。
python之json模块
文章目录
引入
1.eval( ) 函数
- 在 这一张中我们介绍过了 eval( ) 函数, 他可以将字符串转成Python对象
- 不过局限性比较大, 只能运用于普通的数据类型, 遇到特殊的数据类型就不管用 了
- eval( ) 的处理重点 : 执行一个字符串表达式, 并返回表达式的值
2.eval 函数存取数据示例
#通过文件将字典转成字符串存入(序列化)dic = { 'name':'jack','age':18}with open('db.txt','w',encoding='utf-8')as f : f.write(str(dic)) #通过"eval"函数将拿出来的字符串转成数据结构(反序列化)with open('db.txt','r',encoding='utf-8')as f: data = f.read() dic = eval(data) print(dic) # {'name': 'jack', 'age': 18} print(type(dic)) # 3.eval 的局限性
x="[null,true,false,1]"print(eval(x)) # 报错,无法解析null类型
一、什么是序列化
1.序列化
- 把某个语言的变量转成 json 格式字符串
- 内存中的数据结构**----->转成一种中间格式(字符串)----->**存到文件中
2.反序列化
- 把 json 格式字符串转成某个语言的变量
- 文件**----->读取中间格式(字符串)----->**eval( ) 转成内存中数据结构
3.json 的标准格式字符串
- {“name” : “淘小欣”, “age” : 18, “local” : true, “xx” : null}
- json格式字符串符号必须是双引号
二.为什么要序列化
序列化两种用途:
1.持久保持状态
- 一个软件或程序的运行就是在处理一系列状态的变化, 编程语言中, "状态"会以各种各样有结构的数据类型(或变量)保存在内存中
- 而内存是无法永久保存数据的, 当断电或者是重启程序, 内存中那些有结构的数据都会被清空
- 那么序列化就是在你机器在断电或重启之前将当前内存中的数据都保存到文件中去,下次执行程序可以直接载入之前的数据, 然后继续执行 (就相当于单机游戏存档)
存取数据 (格式标准), 一个程序写入, 另一个程序读取 (这两个程序可以是使用不同的语言写的)
2.跨平台数据交互
- 序列化之后, 不仅可以将序列化后的内容存入磁盘, 也可以通过网络传输到别的机器上
- 如果发送和接收方都约定好使用同一种序列化的格式, 那么便屏蔽了平台和语言所带来的的差异性, 实现了跨平台数据交互
- 反过来, 把数据(变量)内容从序列化的对象重新读到内存中, 这就称之为反序列化
例如 : 后端给前端的数据就是 "json" 格式字符串
三、json能序列化的类型
- json 模块可以序列化:字典,列表,布尔
- json 数据类型和 python 数据类型对应关系表
| Json类型 | Python类型 |
|---|---|
| {} | dict |
| [] | list |
| “string” | str |
| 1.73 | int或float |
| true/false | True/False |
| null | None |
-
json格式序列化后与原数据类型的区别:
原数据格式 JSON True true False false None null ‘abc’ “abc”
四、json序列化与反序列化的使用
1.json序列化与反序列化基本用法
import json# 1. 序列化: 注意!序列化以后。返回的类型是字符串类型。res = json.dumps([1, 1.1, True, False, None, { 'name': 'jack'}])print(res, type(res)) # [1, 1.1, true, false, null, {"name": "jack"}] # 2. 反序列化: 序列化以后。拿回到了原来的类型。res = json.loads(res)print(res, type(res)) # [1, 1.1, True, False, None, {'name': 'jack'}] 2.json序列化的结果写入文件与读取json字符串格式进行反序列化操作
序列化的结果写入文件
- dump()和dumps()
import json# 一. 序列化的结果写入文件# 1. 方法一: json.dumpsinfo = [1, 1.1, True, False, None, { 'name': 'jack'}]res = json.dumps(info) # 提示: 序列化以后返回的是字符串类型,所以可以写入写入文件。with open('a.json', 'wt', encoding='utf-8') as f: f.write(res)# 2. 方法二: json.dump, 写入文件推荐使用这种方式info = [1, 1.1, True, False, None, { 'name': 'jack'}]with open('a.json', 'wt', encoding='utf-8') as f: json.dump(info, f) #自带f.write(),无需调用f.write()功能,将传进去的info序列化为json格式后写入到文件对象f中 从文件读取json格式的字符串进行反序列化操作
- load()和loads()
# 1. 方式一: json.loadswith open('a.json', 'rt', encoding='utf-8') as f: res = json.loads(f.read()) print(res, type(res)) # [1, 1.1, True, False, None, {'name': 'jack'}] # 2. 方式二: json.load, 文件读json格式的字符串,推荐使用这种方式。with open('a.json', 'rt', encoding='utf-8') as f: print(json.load(f)) #自带f.read() 序列化和反序列化总结
-
json 模块可以序列化:字典,列表,布尔
-
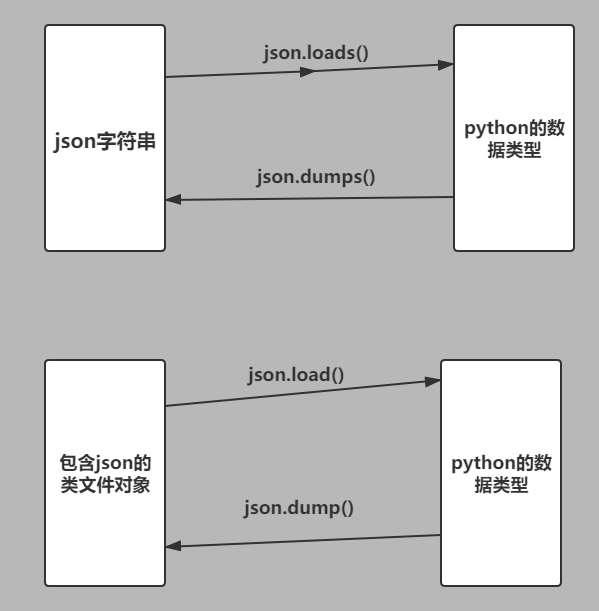
json.dumps()是一般序列化,json.loads()是一般反序列化 -
load和loads都是实现反序列化,dumps和dump都是实现序列化 -
load和dump都是针对的文件对象,使用这两种默认自带读写功能,不需要调用.read()或.write()功能 -
load和读取文件内容将其反序列化,返回反序列化后的内容 -
dump将传进去的值序列化为json格式的后写入保存到文件对象中
3.使用json的4点注意须知

import json# 须知一: json兼容的是所有语言通用的数据类型。不能识别某一语言的独有类型。而Python中的独有类型就含有集合, 所以json不能识别。json.dumps({ 1, 2, 3}) # TypeError: Object of type set is not JSON serializable# 须知二: json格式中的字符串必须使用双引号。json 不认单引号. json.loads("['logging_test', 'config_test']") # json.decoder.JSONDecodeError: Expecting value: line 1 column 2 (char 1)# 须知三. 无论数据是怎样创建的,只要满足json格式,就可以json.loads出来,不一定非要dumps的数据才能loads(上面如图所示。展示json格式是怎么样表达的)# 须知四. json针对中文时的序列化与反序列化(针对中文的序列化会把它转成一种特定的json编码格式, 并不能与英文字符串一样能直观的看到。)res = json.dumps('我是中文')print(res, type(res)) # "\u6211\u662f\u4e2d\u6587" res = json.loads(res)print(res, type(res)) # 我是中文 五、使用json序列化bytes类型
- 演示
import jsondic = { "name": "淘小欣", "age": 22}res = json.dumps(dic)print(res) # {"name": "\u6d3e\u5927\u661f", "age": 22} - 加入
ensure_ascii=False功能
dic = { "name": "淘小欣", "age": 22}res = json.dumps(dic,ensure_ascii=False)print(res) # {"name": "淘小欣", "age": 22} - 问题总结
并没有使用上的变化, 存的是什么, 取出来的还是什么, 只不过人家内部帮你转成"uncode"格式保存
ps : java中,出于性能的考虑,有很多包来完成序列化和反序列化:谷歌的gson 阿里开源fastjson 等等
补充:
# 了解: python2当中str就是bytes类型. 在python解释器2.7与3.6之后都可以json.loads(bytes类型), python3中字符串其实等同于Unicode编码格式。但是在除了python3.5, json内部对这种的表达形式做了优化, 让在python3中也可以使用,但唯独3.5不可以>>> import json>>> json.loads(b'{"a":111}')Traceback (most recent call last): File " ", line 1, in File "/Users/linhaifeng/anaconda3/lib/python3.5/json/__init__.py", line 312, in loads s.__class__.__name__))TypeError: the JSON object must be str, not 'bytes' 六、猴子补丁
1.什么是猴子补丁
- 在运行时动态的修改模块, 类, 函数, 通常是添加功能或修正缺陷
- 猴子补丁在代码运行内存中发挥作用, 不会修改源代码, 因此只在运行时有效
猴子补丁(Monkey Patch)
这个词原来为Guerrilla Patch,杂牌军、游击队,说明这部分不是原装的,在英文里guerilla发音和gorllia(猩猩)相似,再后来就写了monkey(猴子)
还有一种解释是说由于这种方式将原来的代码弄乱了(messing with it),在英文里叫monkeying about(顽皮的),所以叫做Monkey Patch
2.猴子补丁的功能演示
一切皆对象, 拥有模块, 类, 函数运行时替换的功能
一个函数对象赋值给另一个函数对象
将函数原本执行的功能替换掉了
class aaa: def bbb(self): print("i am bbb") def ccc(self): print("i am ccc")def ddd(): print("i am ddd")AAA = aaa()AAA.bbb = AAA.cccAAA.bbb() # i am cccAAA.ccc = dddAAA.ccc() # i am ddd 3.猴子补丁的应用场景
如果我们基于 json 模块写了大量的代码, 然后发现 ujson 比它快10倍, 并且用法一样
我们肯定不会想到把所有的 json.dumps或 json.loads 全换成 ujson.dumps或 ujson.loads
我们可能会想到 模块取别名 import json as ujson, 但这样每个模块都需要重新导入一下
以上方法的维护成本都非常高, 此时我们就可以使用到猴子补丁了, 只需要在入口文件加上就行
import jsonimport ujsondef monkey_patch_json(): json.__name__ = 'ujson' json.dumps = ujson.dumps json.loads = ujson.loads monket_patch_json()
4.猴子补丁优缺点总结
之所以在入口处加, 是因为模块在导入一次之后, 后续的导入变直接引用第一次导入的结果
其实这种场景也比较多, 比如我们引用团队通用库里的一个模块, 又想丰富模块的功能, 除了继承之外也可以考虑用Monkey Patch
优点 : 采用猴子补丁后, 如果发现 ujson 不符合预期, 那也可以快速撤回补丁
缺点 : 因为Monkey Patch破坏了封装, 带来了搞乱源代码的风险
发表评论
最新留言
关于作者
