深度模型剪枝问题
BN层:去均值,再除以标准差,再引入两个可训练的参数:
发布日期:2021-05-14 15:19:54
浏览次数:23
分类:精选文章
本文共 2038 字,大约阅读时间需要 6 分钟。
深 度 模 型 剪 枝 问 题 深度模型剪枝问题 深度模型剪枝问题
Abstract:
The deployment of deep convolutional neural networks (CNNs) in many real world applications is largely hindered by their high computational cost. In this paper, we propose a novel learning scheme for CNNs to simultaneously 1) reduce the model size; 2) decrease the run-time memory footprint; and 3) lower the number of computing operations, without compromising accuracy. This is achieved by enforcing channel-level sparsity in the network in a simple but effective way. Different from many existing approaches, the proposed method directly applies to modern CNN architectures, introduces minimum overhead to the training process, and requires no special software/hardware accelerators for the resulting models. We call our approach network slimming, which takes wide and large networks as input models, but during training insignificant channels are automatically identified and pruned afterwards, yielding thin and compact models with comparable accuracy. We empirically demonstrate the effectiveness of our approach with several state-of-the-art CNN models, including VGGNet, ResNet and DenseNet, on various image classification datasets. For VGGNet, a multi-pass version of network slimming gives a 20x reduction in model size and a 5x reduction in computing operations.
剪枝的整体流程:训练-剪枝-再训练

pruneI(剪枝)
对特征图进行排序,再进行删选,选择好的特征图,即加载自己选择的特征图,就是剪枝
原理是什么呢?
卷积后能得到多个特征图,这些图不一定都重要
训练模型的时候可以加入一些策略,让权重参数体现出主次之分
如何分清权重参数的重要性
Network slimming,就是利用BN层中的缩放因子γ
BN层:去均值,再除以标准差,再引入两个可训练的参数:γ和β
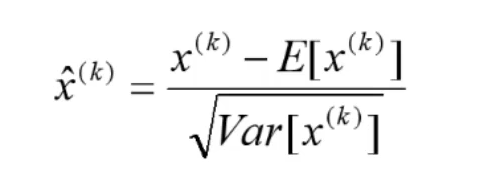
在模型训练的时候,特别是深层模型,如果每一次输入的数据的分布都在变化,很可能会导致模型越来越难收敛,而且会过拟合,为什么会过拟合呢?其实直观上还是很容易理解的,都在变化,不加约束,那所涉及的范围就广了,本来是条直线就能解决的问题,现在变成了曲线,这样模型就过拟合了,所以加入BN层就是对每层的学习结果进行限制
还有为什么说BN层能缓解梯度弥散,或者梯度消失
看下面这张图:

BN层将输出压缩到[-1,1]之间,就是让有明显的梯度值,从而达到了缓解梯度弥散,或者梯度消失的问题
所以BN层一般加在Conv和relu层之间,就是让卷积的输出的结果控制在[0,1]之间,来缓解梯度消失的问题
BN把越来越偏离的分布给他拉回来,重新规范化到均值为0方差为1的标准正态分布 ,这样能够使得激活函数在数值层面更敏感,训练更快。
BN另一方面还需要保证一些非线性,对规范化后的结果再进行变换
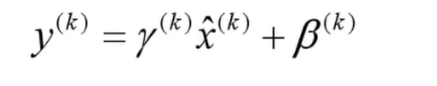
这两个参数是训练得到的
L1和L2正则化
论文中提出:训练时使用L1正则化能对参数进行稀疏作用
L1:稀疏与特征选择;
L2:平滑特征
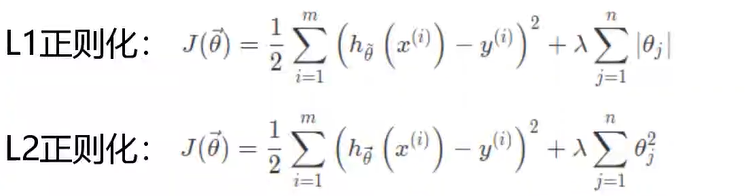
论文核心点
- 以BN中的
γ为切入点,即v越小,其对应的特征图越不重要 - 为了使得能有特征选择的作用,引入
L1正则来控制γ
发表评论
最新留言
逛到本站,mark一下
[***.202.152.39]2025年05月03日 14时11分16秒
关于作者

喝酒易醉,品茶养心,人生如梦,品茶悟道,何以解忧?唯有杜康!
-- 愿君每日到此一游!
推荐文章
7、回归和特征选择
2021-05-14
pycharm使用(新建工程、字体修改、调试)
2021-05-14
什么是Numpy、Numpy教程
2021-05-14
Python学习笔记——元组
2021-05-14
异常声音检测
2021-05-14
PCB学习笔记——AD17如何添加新的封装
2021-05-14
numpy版本问题
2021-05-14
无法打开文件“opencv_world330d.lib”的解决办法
2021-05-14
maven项目通过Eclipse上传到svn上面,再导入到本地出现指定的类找不到的问题
2021-05-14
maven 项目部署到tomcat下 没有class文件
2021-05-14
算法训练 未名湖边的烦恼(递归,递推)
2021-05-14
算法训练 完数(循环,数学知识)
2021-05-14
什么是接口
2021-05-14
2020版nodejs12.18.3安装配置教程
2021-05-14
iview组件库中,Form组件里的Input,无法正确绑定on-enter事件
2021-05-14
记录-基于springboot+vue.js实现的超大文件分片极速上传及流式下载
2021-05-14
JavaScript高级程序设计第四版学习记录-第九章代理与反射
2021-05-14
白红宇的个人博客 - 记录点点滴滴的事 - 您是第 461251499 位访客
访问时间: 2025-05-05 06:30:29
访问IP: 3.148.235.247
Copyright © 2020 - 2025 css8.cn 京ICP备2021015314号-1
手机版