本文共 2712 字,大约阅读时间需要 9 分钟。
完全分布式基于Ubuntu 16.04(桌面版)伪分布式的基础上进行搭建的。
若还没有响应环境,请移步到
一、完全分布式环境搭建
1.利用配置好的伪分布式系统克隆三台主机master、slave1、slave2

2.修改每台主机的主机名 vi /etc/hostname
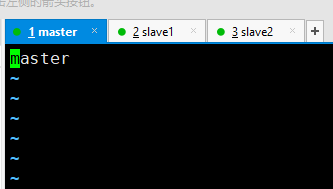
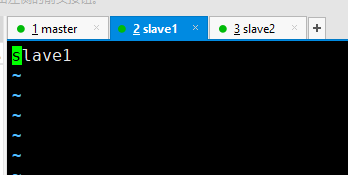
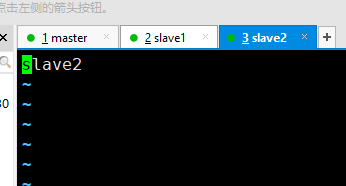
3.修改hosts 文件,配置主机映射,使每台主机之间可以相互拼通,三台主机做相同配置。

ping slave1
ping slave2

4.修改之后重启系统或者重启网络服务
/etc/init.d/networking restart
5.给三台主机配置免密钥登录。
在三台主机的根目录下创建一个文件夹passwd用来保存密钥:
mkdir /root/passwd (三台主机都要创建,用于保存公钥)
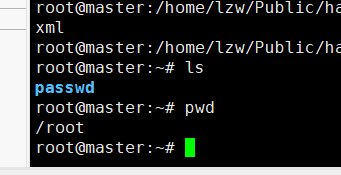
6.三台主机执行命令:
ssh-keygen –t rsa 生成密钥
查看密钥 cat /root/.ssh/id_rsa.pub

7.将当前主机的公钥分发给其他两个节点
scp /root/.ssh/id_rsa.pub root@slave1:/root/passwd
@前面是账号,后面是主机名, : 后面跟路径

8.重复以上操作,将公钥分发给其他两台主机。注意要保存在不同的文件夹下,不要覆盖原文件。
将本机的密钥传到授权Keys(三台主机做相同操作)
cd /root/.ssh/
cat id_rsa.pub >> authorized_keys
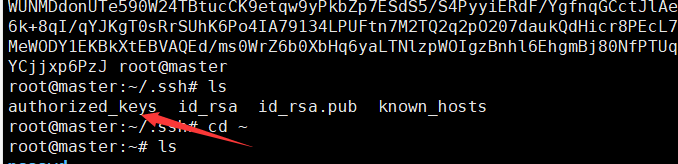
9.查看密钥,并将传来的密钥授权到Keys里面(三台主机都要将密钥授权到/root/.ssh/ authorized_keys中)
cat id_rsa.pub >> /root/.ssh/authorized_keys

10.配置完成后查看密钥,确保每个主机的/root/.ssh/ authorized_keys 中有三台主机的密钥。

11.免密登录测试,连接其他两台主机不需要输入密钥即为免密配置成功。

12.修改hdfs-site.xml配置文件,配置副本数3,指定SecondarNameNode在Slvae1从节点上。



13.修改hadoop下的 core-site.xml(三台配置一样)

14.修改slaves文件,将从节点的主机写入,三台主机都要做同样的配置。
15.配置yarn-site.xml文件,修改主机名或者IP地址(三台配置一样)。
16.启动所有服务 start-all.sh
查看服务进程



17.使用网页登录查看信息


至此,学习使用的完全分布式环境搭建完成。
二、温度统计
1.创建项目,编写代码实现温度统计功能。
以Windows为例(也可在Ubuntu中创建项目编写代码)。
打开IDEA 创建项目,导入hadoop开发相关jar包。

2.编写代码:
Temperature.java
将Temperature序列化,重写compareTo(),wirte(),readFields(),toString()方法,并生成setter(),getter()方法

TempMapper.java
指定Mapper输出格式

TempPartitioner.java
指定分区

TempMain.java

3.将项目打包,使用Xftp工具上传到master

4.创建源文件data.txt

2019-10-01,14:21:02,34c
2019-10-01,19:21:02,38c
2019-10-02,14:01:02,36c
2019-01-01,11:21:02,32c
2019-10-01,12:21:02,37c
2019-12-01,12:21:02,23c
2019-10-02,12:21:02,41c
2019-10-03,12:21:02,27c
2019-07-01,12:21:02,45c
2019-07-02,12:21:02,46c
2019-07-03,12:21:03,47c
2019-06-01,12:21:02,38c
2019-06-02,12:21:02,39c
2019-06-03,12:21:03,30c
2019-11-01,12:21:02,38c
2019-11-02,12:21:02,39c
2019-08-03,12:21:03,30c
2019-11-01,12:21:02,38c
2019-08-02,12:21:02,39c
2019-08-03,12:21:03,30c
2019-12-01,12:21:02,18c
2019-12-02,12:21:02,9c
2019-12-03,12:21:03,3c
2019-05-01,12:21:02,18c
2019-05-02,12:21:02,19c
2019-05-03,12:21:03,10c
2019-03-01,12:21:02,16c
2019-03-02,12:21:02,12c
2019-03-03,12:21:03,20c
2019-04-01,12:21:02,28c
2019-04-02,12:21:02,29c
2019-04-03,12:21:03,20c
2019-01-01,12:21:02,8c
2019-01-02,12:21:02,9c
2019-01-03,12:21:03,4c
2019-09-01,12:21:02,38c
2019-09-02,12:21:02,39c
2019-09-03,12:21:03,30c
2019-02-01,12:21:02,12c
2019-02-02,12:21:02,14c
2019-02-03,12:21:03,10c
5.在HDFS上面创建两个目录分别保存输入和输出文件
hdfs dfs –mkdir /input
hdfs dfs –mkdir /outfile
上传数据源文件 hdfs dfs –put data.txt /input/data.txt

运行程序
hadoop jar sort_temperature.jar /input/data.txt /outfile/temperature
注: hadoop jar jar包路径及包名 HDFS上的输入文件路径 HDFS上的输出文件路径(必须是不存在的,会自动创建,若存在则会报错)

查看结果 hdfs dfs -cat /outfile/temperature/part-r-00007


至此,温度统计小程序就实现啦,欢迎大家一起交流学习。
项目地址:
发表评论
最新留言
关于作者
