大数据学习之wordcount
发布日期:2021-05-07 13:15:33
浏览次数:34
分类:原创文章
本文共 551 字,大约阅读时间需要 1 分钟。
环境:Ubutun 16.04 + Java + HDFS +Hadoop
工具:VM 15.0 + IDEA +XShell 6+ Xftp 6
一、了解MapReduce模型:







二、代码编写,实现单词统计功能
1.导入MapReduce开发相关的jar包

2.打开IDEA开发工具, 将jar包构建到项目中

3.创建项目
4.代码编写
WordCountMapper.java

WordCountReduce.java

WordCountMain.java

5.使用IDEA将项目打jar包




6.创建data.txt文件,请输入内容:

启动服务 :
start-all.sh

7.上传文件到HDFS中:
hdfs dfs -put data.txt /
注:hdfs dfs -put 上传文件的路径 HDFS上的路径
 \
\
在HDFS上创建输出文件outfile的存放位置:
hdfs dfs -mkdir /outfile
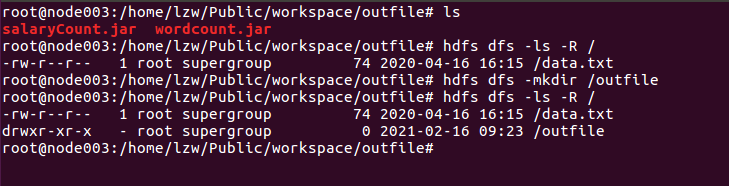
8. 将jar包上传并运行:
hadoop jar wordcount.jar /data.txt /out
hadoop jar jar包名 hdfs上的输入文件路径 hdfs上的输出文件路径
注:输出文件路径必须是不存在的,否则会报错。

9.查看统计结果:

项目地址:
发表评论
最新留言
第一次来,支持一个
[***.219.124.196]2025年03月26日 01时06分49秒
关于作者

喝酒易醉,品茶养心,人生如梦,品茶悟道,何以解忧?唯有杜康!
-- 愿君每日到此一游!
推荐文章
MySQL不会丢失数据的秘密,就藏在它的 7种日志里
2019-03-06
Python开发之序列化与反序列化:pickle、json模块使用详解
2019-03-06
回顾-生成 vs 判别模型-和图
2019-03-06
采坑 - 字符串的 "" 与 pd.isnull()
2019-03-06
无序列表 - 链表
2019-03-06
SQL 查询强化 - 数据准备
2019-03-06
SQL 强化练习 (四)
2019-03-06
SQL 强化练习 (八)
2019-03-06
Excel 拼接为 SQL 并打包 exe
2019-03-06
Pandas数据分析从放弃到入门
2019-03-06
Matplotlib绘制漫威英雄战力图,带你飞起来!
2019-03-06
机器学习是什么
2019-03-06
《小王子》里一些后知后觉的道理
2019-03-06
《自私的基因》总结
2019-03-06
《山海经》总结
2019-03-06
《非暴力沟通》总结
2019-03-06
《你当像鸟飞往你的山》总结
2019-03-06
《我是猫》总结
2019-03-06
《抗糖化书》总结
2019-03-06
apache虚拟主机配置
2019-03-06
白红宇的个人博客 - 记录点点滴滴的事 - 您是第 459515299 位访客
访问时间: 2025-04-19 10:28:26
访问IP: 3.144.252.138
Copyright © 2020 - 2025 css8.cn 京ICP备2021015314号-1
手机版