本文共 3084 字,大约阅读时间需要 10 分钟。
一. 安装JDK
由于之前的集群安装的是jdk1.7的版本, 所以这里操作相对会麻烦一点
-
安装jdk1.8版本
 注意:要修改族和组
注意:要修改族和组 -
修改配置文件
因为之前安装过jdk1.7,如果还是把$PATH,写在前面,不会生效
export JAVA_HOME=/usr/java/jdk1.8.0_181export PATH=$JAVA_HOME/bin:$PATH
-
分发给其他虚拟机
-
之前安装jdk时在” /usr/bin”目录下有一个java的连接:

-
进入他指向的连接地址:
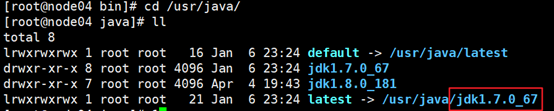
-
执行:
ln -sf /usr/java/jdk1.8.0_181/bin/java /usr/bin/java
-
修改后进入”/usr/bin”查看:

-
修改这一步的原因是:
spark集群会默认从这个路径下查询jdk的版本 -
修改hadoop的配置文件
/opt/hjf/hadoop/etc/hadoop/hadoop-env.sh
修改为现在的版本号:
# export JAVA_HOME=/usr/java/jdk1.7.0_67export JAVA_HOME=/usr/java/jdk1.8.0_181

至此, jdk版本更改完成, 接下来正式安装spark
一. Spark安装
node01\node02\node03三台安装spark集群
node04只用于任务提交
1. 将spark解压大指定路径下:

2. 进入:/opt/hjf/spark/conf目录下:
-
将slaves.template修改为: slaves
cp slaves.template slaves

-
指定worker节点的主机:
node02node03
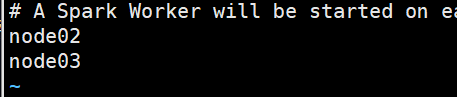
-
将spark-env.sh.template,修改为spark-env.sh
cp spark-env.sh.template spark-env.sh

-
配置spark-env.sh
export SPARK_MASTER_HOST=node01 # 指定master节点export SPARK_MASTER_PORT=7077 # 指定提交任务的端口export SPARK_WORKER_CORES=2 # 指定worker的核数export SPARK_WORKER_MEMORY=3g # 指定worker分配的内存资源
3. 分发给node02和node03:
三. Spark启动
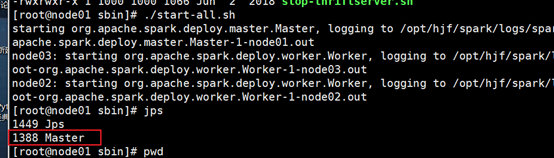
1. 进入/opt/hjf/spark/sbin,执行:
-
./start-all.sh
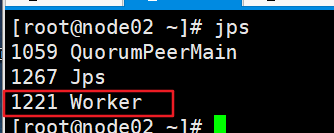
2. 查看jps
- node01
- node02:
- node03:
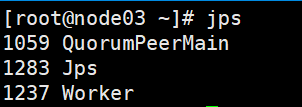
3. 查看Web UI

四. 执行
-
执行PI
./spark-submit --master spark://node01:7077 --class org.apache.spark.examples.SparkPi ../examples/jars/spark-examples_2.11-2.3.1.jar 100
-
运行结果

五. 配日志服务器
1. 进入/opt/hjf/spark/conf下:
-
复制spark-defaults.conf.template并命名为: spark-defaults.conf
cp spark-defaults.conf.template spark-defaults.conf

-
修改spark-defaults.conf文件:
# 开启日志服务:spark.eventLog.enabled true# 配置日志存放路径spark.eventLog.dir hdfs://node01:8020/spark/data/logs# 配置日志恢复路径spark.history.fs.logDirectory hdfs://node01:8020/spark/data/logs

-
注意: 配置文件中的节点必须为HDFS中状态为active的节点名称
里有提示
spark.history.fs.logDirectory
2. 启动日志服务器
-
进入:”/opt/hjf/spark/sbin”
./start-history-server.sh

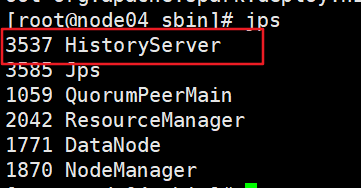
3. 查看日志服务器WebUI
主机名,为配置日志服务器主机名
4. 此时就可以保存日志
-
./spark-shell --master spark://node01:7077 --name aaa


六. Master HA配置
1. 修改”spark-env.sh”配置文件
-
参考说明:
spark.deploy.recoveryMode:恢复模式,选择使用ZOOKEEPERspark.deploy.zookeeper.url:指定zookeeper集群spark.deploy.zookeeper.dir:恢复路径
-
修改”spark-env.sh”配置文件
各个参数前用”-D”开头, 参数间用空格隔开
export SPARK_DAEMON_JAVA_OPTS="-Dspark.deploy.recoveryMode=ZOOKEEPER -Dspark.deploy.zookeeper.url=node02:2181,node03:2181,node04:2181 -Dspark.deploy.zookeeper.dir=/MasterHA"

2. 分发到其他几台机器
3. 设置主备节点
-
把node01当做Master,把node02当做备用
所以node02修改”/opt/hjf/spark/conf/ spark-env.sh”配置文件:export SPARK_MASTER_HOST=node02
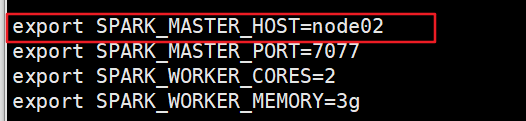
4. 启动:
-
分别在node01和node02主机上启动启动
spark:start-all.sh

-
kill掉node01 的master节点后,会自动将node02的STANDBY状态升级为 ALIVE


-
如果没有跳转成功, 则需要检查zookeeper中是否添加成功
- 进入 /opt/hjf/zookeeper/bin目录
- ./zkCli.sh
- ls / :查看是否有之前设置的名称,如果不存在,则说明之前的配置有误

-
运行: 需要指定主节点和备用节点
./spark-submit --master spark://node01:7077,node02:7077 –class org.apache.spark.examples.SparkPi ../examples/jars/spark-examples_2.11-2.3.1.jar 1000
七. spark on hive配置
-
先将hive客户端中的hive-site.xml复制到spark/conf目录下

-
修改复制后的hive-site.xml文件:
原文件中的其他配置内容都可以删掉,只需保留这一部分hive.metastore.uris thrift://node03:9083 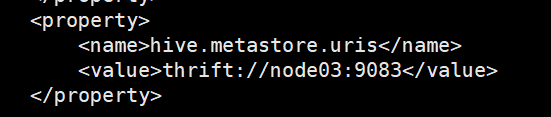
-
启动:
- 启动hive服务器
hive --service metastore
- 启动hive客户端
hive
- 启动spark-shell
./spark-shell --master spark://node01:7077,node02:7077
- 启动hive服务器
发表评论
最新留言
关于作者
