pyspark笔记



 在Python中,DataFrame.collect()将分布式数据作为本地数据收集到驱动端。请注意,当数据集太大,无法装入驱动端时,这会抛出内存不足错误,因为它从执行器收集所有数据到驱动端。
在Python中,DataFrame.collect()将分布式数据作为本地数据收集到驱动端。请注意,当数据集太大,无法装入驱动端时,这会抛出内存不足错误,因为它从执行器收集所有数据到驱动端。 
 这些列可用于从DataFrame中选择列。例如,DataFrame.select()接受返回另一个DataFrame的Column实例。
这些列可用于从DataFrame中选择列。例如,DataFrame.select()接受返回另一个DataFrame的Column实例。  访问新的列
访问新的列  DataFrame.filter()选择子集
DataFrame.filter()选择子集 
 也可以应用函数
也可以应用函数
发布日期:2021-05-06 11:08:47
浏览次数:12
分类:技术文章
本文共 4352 字,大约阅读时间需要 14 分钟。
PySpark是Apache Spark在Python中的接口。它不仅允许您使用Python api编写Spark应用程序,而且还提供了用于在分布式环境中交互分析数据的PySpark shell。PySpark支持Spark的大部分特性,如Spark SQL、DataFrame、Streaming、MLlib(机器学习)和Spark Core。
- Spark SQL and DataFrame Spark SQL是用于结构化数据处理的Spark模块。它提供了一种称为DataFrame的编程抽象,还可以充当分布式SQL查询引擎。
- Streaming 运行在Spark之上,Apache Spark中的流特性支持跨流数据和历史数据的强大交互和分析应用程序,同时继承了Spark的易用性和容错特性。
- MLlib MLlib是一个可扩展的机器学习库,构建在Spark之上,它提供了一组统一的高级api,帮助用户创建和调优实用的机器学习管道。
- Spark Core Spark Core是Spark平台的底层通用执行引擎,所有其他功能都构建在其之上。它提供RDD(弹性分布式数据集)和内存计算能力。
快速开始
对pyspark中的DataFrame API 快速简介:
PySpark DataFrames are lazily evaluated. They are implemented on top of RDDs. When Spark transforms data, it does not immediately compute the transformation but plans how to compute later. When actions such as collect() are explicitly called, the computation starts.create a PySpark DataFrame from a list of rows
import findsparkfindspark.init()from pyspark.sql import SparkSessionfrom datetime import datetime, dateimport pandas as pdfrom pyspark.sql import Rowspark = SparkSession.builder.getOrCreate()df = spark.createDataFrame( [ Row(a=1, b=2., c='string1', d=date(2000, 1, 1), e=datetime(2000, 1, 1, 12, 0)), Row(a=2, b=3., c='string2', d=date(2000, 2, 1), e=datetime(2000, 1, 2, 12, 0)), Row(a=4, b=5., c='string3', d=date(2000, 3, 1), e=datetime(2000, 1, 3, 12, 0)) ])df.show()df.printSchema()
记得加上
import findspark findspark.init() Create a PySpark DataFrame with an explicit schema.
df = spark.createDataFrame([ (1, 2., 'string1', date(2000, 1, 1), datetime(2000, 1, 1, 12, 0)), (2, 3., 'string2', date(2000, 2, 1), datetime(2000, 1, 2, 12, 0)), (3, 4., 'string3', date(2000, 3, 1), datetime(2000, 1, 3, 12, 0))], schema='a long, b double, c string, d date, e timestamp')df
Create a PySpark DataFrame from a pandas DataFrame
pandas_df = pd.DataFrame({ 'a': [1, 2, 3], 'b': [2., 3., 4.], 'c': ['string1', 'string2', 'string3'], 'd': [date(2000, 1, 1), date(2000, 2, 1), date(2000, 3, 1)], 'e': [datetime(2000, 1, 1, 12, 0), datetime(2000, 1, 2, 12, 0), datetime(2000, 1, 3, 12, 0)]})df = spark.createDataFrame(pandas_df)df Create a PySpark DataFrame from an RDD consisting of a list of tuples.
rdd = spark.sparkContext.parallelize([ (1, 2., 'string1', date(2000, 1, 1), datetime(2000, 1, 1, 12, 0)), (2, 3., 'string2', date(2000, 2, 1), datetime(2000, 1, 2, 12, 0)), (3, 4., 'string3', date(2000, 3, 1), datetime(2000, 1, 3, 12, 0))])df = spark.createDataFrame(rdd, schema=['a', 'b', 'c', 'd', 'e'])df
结果都一样,如下
查看数据


在Python中,DataFrame.collect()将分布式数据作为本地数据收集到驱动端。请注意,当数据集太大,无法装入驱动端时,这会抛出内存不足错误,因为它从执行器收集所有数据到驱动端。 df.collect()'''[Row(a=1, b=2.0, c='string1', d=datetime.date(2000, 1, 1), e=datetime.datetime(2000, 1, 1, 12, 0)), Row(a=2, b=3.0, c='string2', d=datetime.date(2000, 2, 1), e=datetime.datetime(2000, 1, 2, 12, 0)), Row(a=3, b=4.0, c='string3', d=datetime.date(2000, 3, 1), e=datetime.datetime(2000, 1, 3, 12, 0))]'''
PySpark DataFrame还提供了转换回一个pandas DataFrame来利用pandas api。请注意,toPandas还将所有数据收集到驱动端,当数据太大而无法容纳到驱动端时,这些数据很容易导致内存不足错误。
选择和访问数据
PySpark DataFrame是延迟计算的,简单地选择一个列不会触发计算,但它会返回一个column实例。
这些列可用于从DataFrame中选择列。例如,DataFrame.select()接受返回另一个DataFrame的Column实例。 访问新的列 DataFrame.filter()选择子集 使用函数

分组数据
df = spark.createDataFrame([ ['red', 'banana', 1, 10], ['blue', 'banana', 2, 20], ['red', 'carrot', 3, 30], ['blue', 'grape', 4, 40], ['red', 'carrot', 5, 50], ['black', 'carrot', 6, 60], ['red', 'banana', 7, 70], ['red', 'grape', 8, 80]], schema=['color', 'fruit', 'v1', 'v2'])df.show()

也可以应用函数 def plus_mean(pandas_df): return pandas_df.assign(v1=pandas_df.v1 - pandas_df.v1.mean())df.groupby('color').applyInPandas(plus_mean, schema=df.schema).show() 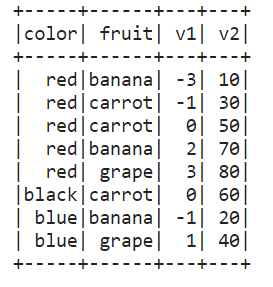
df1 = spark.createDataFrame( [(20000101, 1, 1.0), (20000101, 2, 2.0), (20000102, 1, 3.0), (20000102, 2, 4.0)], ('time', 'id', 'v1'))df2 = spark.createDataFrame( [(20000101, 1, 'x'), (20000101, 2, 'y')], ('time', 'id', 'v2'))def asof_join(l, r): return pd.merge_asof(l, r, on='time', by='id')df1.groupby('id').cogroup(df2.groupby('id')).applyInPandas( asof_join, schema='time int, id int, v1 double, v2 string').show() 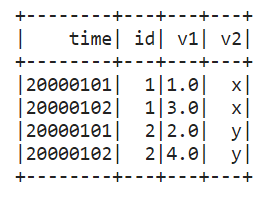
获取、保存数据

使用SQL
DataFrame和Spark SQL共享相同的执行引擎,因此它们可以无缝地互换使用。例如,你可以注册DataFrame作为一个表,然后像下面这样轻松地运行SQL:
df.createOrReplaceTempView("tableA")spark.sql("SELECT count(*) from tableA").show() ±-------+
|count(1)| ±-------+ | 8| ±-------+
发表评论
最新留言
路过,博主的博客真漂亮。。
[***.116.15.85]2025年03月10日 08时20分11秒
关于作者

喝酒易醉,品茶养心,人生如梦,品茶悟道,何以解忧?唯有杜康!
-- 愿君每日到此一游!
推荐文章
Retrofit学习
2019-03-03
Android卡顿优化--界面秒开
2019-03-03
Android网络优化--工具
2019-03-03
Android网络优化--精准获取流量消耗
2019-03-03
Android进程的启动流程
2019-03-03
异步任务--AsyncTask
2019-03-03
《硬件架构的艺术》学习笔记(3.1)---跨时钟域设计
2019-03-03
Filecoin官方发布:并不存在“双花”问题!
2019-03-03
VTK:图表之ShortestPath
2019-03-03
VTK:IO之DumpXMLFile
2019-03-03
VTK:IO之JPEGReader
2019-03-03
VTK:IO之MetaImageReader
2019-03-03
VTK:IO之WriteVTI
2019-03-03
VTK:图片之Actor2D
2019-03-03
VTK:图片之ImageCorrelation
2019-03-03
VTK:图片之ImageExport
2019-03-03
VTK:图片之ImageGridSource
2019-03-03
VTK:图片之ImageMathematics
2019-03-03
VTK:图片之ImageOrientation
2019-03-03
VTK:图片之ImageStack
2019-03-03
白红宇的个人博客 - 记录点点滴滴的事 - 您是第 453426336 位访客