机器学习面试(二)

发布日期:2021-05-06 11:07:48
浏览次数:28
分类:精选文章
本文共 504 字,大约阅读时间需要 1 分钟。
- Batch Normalization 使用顺序
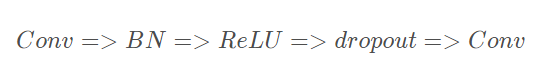 训练 把数据分为若干组,按组来更新参数,一组中的数据共同决定了本次梯度的方向,下降时候减少了随机性。假设神经网络某层一个batch的输入为X=[x1,x2,…xn],其中xi代表一个样本,n为batch_size。 首先需要求得mini-batch里面的元素的均值:
训练 把数据分为若干组,按组来更新参数,一组中的数据共同决定了本次梯度的方向,下降时候减少了随机性。假设神经网络某层一个batch的输入为X=[x1,x2,…xn],其中xi代表一个样本,n为batch_size。 首先需要求得mini-batch里面的元素的均值:  接下来,求取mini-batch的方差:
接下来,求取mini-batch的方差: 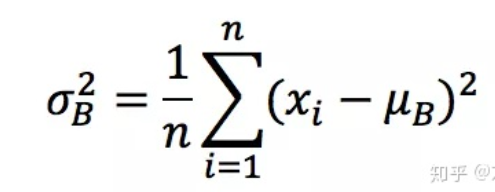 这样就可以对每个元素进行归一化。
这样就可以对每个元素进行归一化。  最后进行尺度缩放和偏移操作,这样可以变换回原始的分布,实现恒等变换,这样的目的是为了补偿网络的非线性表达能力,因为经过标准化之后,偏移量丢失。
最后进行尺度缩放和偏移操作,这样可以变换回原始的分布,实现恒等变换,这样的目的是为了补偿网络的非线性表达能力,因为经过标准化之后,偏移量丢失。 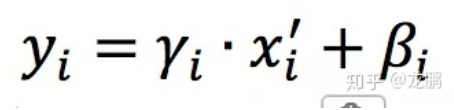 BN的好处
BN的好处 
- 孤立森林
异常检测算法,又称为“离群点检测”,一般异常数据有两个特点:
1.异常数据跟样本中大多数据不太一样 2.异常数据在整体数据样本中占比比较小这些特性使得SVM,逻辑回归等分算法在此背景下不是用。
孤立森林:假设我们用随机一个超平面来切割数据空间,切一次可分为两个子空间。之后我们再继续用一个随机超平面来切割每个子空间,循环下去,直到每个子空间只有一个数据点为止。 直观上看密度很低的点很容易很早的就停止到一个子空间中了,密度很高的簇可以被分割多次。
发表评论
最新留言
路过按个爪印,很不错,赞一个!
[***.219.124.196]2025年04月13日 16时48分42秒
关于作者

喝酒易醉,品茶养心,人生如梦,品茶悟道,何以解忧?唯有杜康!
-- 愿君每日到此一游!
推荐文章
Cassandra数据建模
2019-03-06
Elasticsearch Web管理工具
2019-03-06
在create-react-app创建的项目下允许函数绑定运算符
2019-03-06
评论表聚集索引引起的评论超时问题
2019-03-06
Internet Explorer 10 专题上线
2019-03-06
云计算之路-阿里云上:0:25~0:40网络存储故障造成网站不能正常访问
2019-03-06
网站故障公告1:使用阿里云RDS之后一个让人欲哭无泪的下午
2019-03-06
上周热点回顾(6.3-6.9)
2019-03-06
上周热点回顾(8.12-8.18)
2019-03-06
【故障公告】升级阿里云 RDS SQL Server 实例故障经过
2019-03-06
蹒跚来迟:新版博客后台上线公测
2019-03-06
上周热点回顾(9.16-9.22)
2019-03-06
上周热点回顾(11.4-11.10)
2019-03-06
[网站公告]11月26日00:00-04:00阿里云RDS升级
2019-03-06
[网站公告]又拍云API故障造成图片无法上传(已恢复)
2019-03-06
上周热点回顾(12.16-12.22)
2019-03-06
云计算之路-阿里云上:“黑色30秒”走了,“黑色1秒”来了,真相也许大白了
2019-03-06
云计算之路-阿里云上:奇怪的CPU 100%问题
2019-03-06
云计算之路-阿里云上:2014年6月12日12点IIS请求到达量突降
2019-03-06
上周热点回顾(6.9-6.15)
2019-03-06
白红宇的个人博客 - 记录点点滴滴的事 - 您是第 459557833 位访客