hadoop yarn日志报错以及如何启动聚合日志
发布日期:2022-02-09 20:39:11
浏览次数:8
分类:技术文章
本文共 1701 字,大约阅读时间需要 5 分钟。
我们在hadoop集群一般需要在工作台查看日志,但是工作台查看日志一般会出现以下情况:

上面的原因是由于yarn的日志监控功能默认是处于关闭状态的,需要我们进行开启,开启步骤如下:
一、在yarn-site.xml文件中添加日志监控支持
该配置中添加下面的配置:
yarn.log-aggregation-enable true yarn.log-aggregation.retain-seconds 640800 yarn.log.server.url http://master:19888/jobhistory/logs/ yarn.nodemanager.remote-app-log-dir /usr/container/logs yarn.nodemanager.resource.memory-mb 4096 yarn.scheduler.minimum-allocation-mb 2048 yarn.scheduler.maximum-allocation-mb 4096 yarn.nodemanager.vmem-pmem-ratio 5
二、在mapred-site.xml文件中添加日志服务的配置
该配置文件中添加如下配置:若是有了的话,无需再次添加
mapreduce.framework.name yarn mapreduce.jobhistory.address master:10020 mapreduce.jobhistory.webapp.address master:19888
三、将修改后的配置文件拷贝到集群中的其他机器(单机版hadoop可以跳过该步骤)
快捷一点可以使用 scp 命令将配置文件拷贝覆盖到其他机器
四、重新启动集群的Hdfs和Yarn服务
./start-all.sh
五、 开启日志监控服务进程
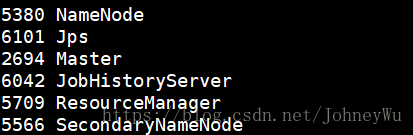
在nodenode机器上执行 sbin/mr-jobhistory-daemon.sh start historyserver 命令,执行完成后使用jps命令查看是否启动成功,若启动成功则会显示出JobHistoryServer服务
转载地址:https://blog.csdn.net/JohneyWu/article/details/81673955 如侵犯您的版权,请留言回复原文章的地址,我们会给您删除此文章,给您带来不便请您谅解!
发表评论
最新留言
感谢大佬
[***.8.128.20]2024年04月02日 03时44分22秒
关于作者

喝酒易醉,品茶养心,人生如梦,品茶悟道,何以解忧?唯有杜康!
-- 愿君每日到此一游!
推荐文章
Unity使用RenderTexture实现裁切3D模型
2019-04-27
美术和程序吵架,原来是资源序列化格式设置不统一
2019-04-27
Unity iOS接SDK,定制UnityAppController
2019-04-27
Unity iOS接SDK前先要了解的知识(Objective-C)
2019-04-27
记一次iOS闪退问题的定位:NSLog闪退
2019-04-27
Unity打开照相机与打开本地相册然后在Unity中显示照片(Android与iOS)
2019-04-27
无需接入SDK即可在Unity中获取经纬度(Android/iOS),告诉我你的坐标
2019-04-27
Unity获取系统信息SystemInfo(CPU、显卡、操作系统等信息)
2019-04-27
Unity中获取物体的尺寸(size)的三种方法
2019-04-27
Unity中的关节组件和绳子效果的实现
2019-04-27
Unity可视化编程插件: Bolt,可以像UE4的蓝图那样啦
2019-04-27
Android的.dex、.odex与.oat文件扫盲
2019-04-27
Unity移动应用如何在Bugly上查看崩溃堆栈
2019-04-27
unity3D 在屏幕边框创建碰撞框
2019-04-27
xml中常用的转义符
2019-04-27
关于MSDK的几个难点
2019-04-27
使用UnityEditor做工具
2019-04-27
Visual Studio我常用的快捷键
2019-04-27
白红宇的个人博客 - 记录点点滴滴的事 - 您是第 308170776 位访客
访问时间: 2024-04-26 23:10:46
访问IP: 18.221.222.47
Copyright © 2020 - 2023 blog.css8.cn 京ICP备2021015314号-1
手机版