神经网络的双曲线正切激活函数
发布日期:2021-07-01 05:06:16
浏览次数:2
分类:技术文章
本文共 1511 字,大约阅读时间需要 5 分钟。
在数学中,双曲函数类似于常见的(也叫圆函数的)三角函数。基本双曲函数是双曲正弦“sinh”,双曲余弦“cosh”,从它们导出双曲正切“tanh”等。也类似于三角函数的推导。反函数是反双曲正弦“arsinh”(也叫做“arcsinh”或“asinh”)依此类推。

y=tanh x,定义域:R,值域:(-1,1),奇函数,函数图像为过原点并且穿越Ⅰ、Ⅲ象限的严格单调递增曲线,其图像被限制在两水平渐近线y=1和y=-1之间。
它的导数如下:
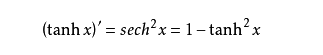
它的曲线图:
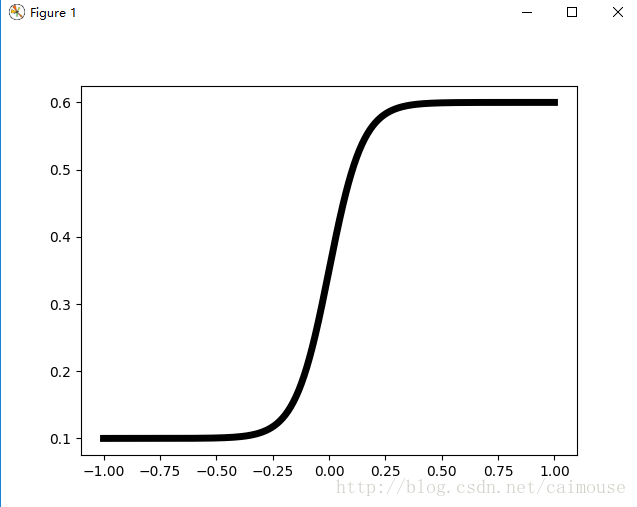
源码:
#python 3.5.3/TensorFlow 1.0/win 10 #2017-03-27 蔡军生 http://blog.csdn.net/caimouse #import pylabimport numpy as npN = 500delta = 0.6X = -1 + 2. * np.arange(N) / (N - 1)pylab.plot(X, (1.4 + np.tanh(4. * X / delta)) / 4, 'k-',linewidth = 5)pylab.show()
它的意义:
第一个问题:为什么引入非线性激励函数?
如果不用激励函数(其实相当于激励函数是f(x) = x),在这种情况下你每一层输出都是上层输入的线性函数,很容易验证,无论你神经网络有多少层,输出都是输入的线性组合,与没有隐藏层效果相当,这种情况就是最原始的感知机(Perceptron)了。正因为上面的原因,我们决定引入非线性函数作为激励函数,这样深层神经网络就有意义了(不再是输入的线性组合,可以逼近任意函数)。最早的想法是sigmoid函数或者tanh函数,输出有界,很容易充当下一层输入(以及一些人的生物解释balabala)。第二个问题:为什么引入Relu呢?第一,采用sigmoid等函数,算激活函数时(指数运算),计算量大,反向传播求误差梯度时,求导涉及除法,计算量相对大,而采用Relu激活函数,整个过程的计算量节省很多。第二,对于深层网络,sigmoid函数反向传播时,很容易就会出现梯度消失的情况(在sigmoid接近饱和区时,变换太缓慢,导数趋于0,这种情况会造成信息丢失,参见 @Haofeng Li 答案的第三点),从而无法完成深层网络的训练。第三,Relu会使一部分神经元的输出为0,这样就造成了网络的稀疏性,并且减少了参数的相互依存关系,缓解了过拟合问题的发生(以及一些人的生物解释balabala)。当然现在也有一些对relu的改进,比如prelu,random relu等,在不同的数据集上会有一些训练速度上或者准确率上的改进,具体的大家可以找相关的paper看。多加一句,现在主流的做法,会在做完relu之后,加一步batch normalization,尽可能保证每一层网络的输入具有相同的分布[1]。而最新的paper[2],他们在加入bypass connection之后,发现改变batch normalization的位置会有更好的效果。大家有兴趣可以看下。1. TensorFlow API攻略
2. TensorFlow入门基本教程
3. C++标准模板库从入门到精通
4.跟老菜鸟学C++
5. 跟老菜鸟学python
6. 在VC2015里学会使用tinyxml库
7. 在Windows下SVN的版本管理与实战
8.Visual Studio 2015开发C++程序的基本使用
9.在VC2015里使用protobuf协议
10.在VC2015里学会使用MySQL数据库
转载地址:https://mysoft.blog.csdn.net/article/details/67630435 如侵犯您的版权,请留言回复原文章的地址,我们会给您删除此文章,给您带来不便请您谅解!
发表评论
最新留言
网站不错 人气很旺了 加油
[***.192.178.218]2024年04月25日 10时33分11秒
关于作者

喝酒易醉,品茶养心,人生如梦,品茶悟道,何以解忧?唯有杜康!
-- 愿君每日到此一游!
推荐文章
XSS漏洞解析(一)
2019-05-03
Springboot使用详解
2019-05-03
java并发编程(十五)-LockSupport工具类
2019-05-03
leetcode算法 111. 二叉树的最小深度
2019-05-03
李洪强iOS开发之-cocopods安装
2019-05-03
界面反应非常慢
2019-05-04
实现string toHex(int)把一个十进制转换成十六进制。(完全用算法实现)
2019-05-04
大家觉得这篇文章如何?
2019-05-04
关于CString总结
2019-05-04
覃仙球- 时装品牌Chilly Chin创始人 | 到「在行」来约见我
2019-05-04
阿里CDN核心技术解密 - 林枫水湾湾 - 博客园
2019-05-04
struts2.5.10.1
2019-05-04
活动反作弊服务_防羊毛党_防作弊评论_防刷单_防作弊投票_网易易盾
2019-05-04
浅谈web指纹识别技术 - FreeBuf.COM | 关注黑客与极客
2019-05-04
信息架构设计:产品结构的基石与支柱 - 推酷
2019-05-04
技术漫谈 | 使用docker-compose进行python开发 - 推酷
2019-05-04
我眼中的领域驱动设计 - richiezhang - 博客园
2019-05-04
白红宇的个人博客 - 记录点点滴滴的事 - 您是第 312061056 位访客
访问时间: 2024-05-08 18:13:59
访问IP: 18.226.4.239
Copyright © 2020 - 2023 blog.css8.cn 京ICP备2021015314号-1
手机版