Feature Engineering 特征工程 3. Feature Generation
learn from
发布日期:2021-07-01 03:25:55
浏览次数:2
分类:技术文章
本文共 3514 字,大约阅读时间需要 11 分钟。
文章目录
上一篇:
下一篇:从原始数据创建新特征是改进模型的最佳方法之一
例如,数据有很长连续时间的,我们可以把最近一周的提取出来作为一个新的特征1. 组合特征
最简单方法之一是组合特征
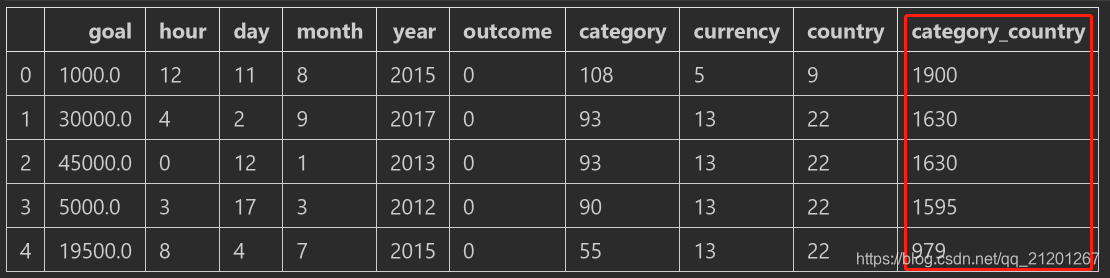
例如,如果一条记录的国家/地区为"CA",类别为"Music",则可以创建一个新值" CA_Music" 可以从所有分类特征中构建组合特征,也可以使用三个或更多特征进行交互,但是效果往往会变坏 interactions = ks['category']+'_'+ks['country'],像python一样直接相加interactions.head(10)
0 Poetry_GB1 Narrative Film_US2 Narrative Film_US3 Music_US4 Film & Video_US5 Restaurants_US6 Food_US7 Drinks_US8 Product Design_US9 Documentary_USdtype: object
- 将新特征
assign进数据
label_enc = LabelEncoder()data_interaction = X.assign(category_country= label_enc.fit_transform(interactions))data_interaction.head()
2. 过去7天的数据
launched = pd.Series(ks.index, index=ks.launched, name="count_7_days").sort_index()# 数据值为索引, 新的索引为建立的时间,新特征名称, 按索引(时间)排序launched.head(20)
launched1970-01-01 01:00:00 945791970-01-01 01:00:00 3190021970-01-01 01:00:00 2479131970-01-01 01:00:00 481471970-01-01 01:00:00 753971970-01-01 01:00:00 28421970-01-01 01:00:00 2737792009-04-21 21:02:48 1692682009-04-23 00:07:53 3220002009-04-24 21:52:03 1385722009-04-25 17:36:21 3253912009-04-27 14:10:39 1226622009-04-28 13:55:41 2137112009-04-29 02:04:21 3456062009-04-29 02:58:50 2352552009-04-29 04:37:37 989542009-04-29 05:26:32 3422262009-04-29 06:43:44 2750912009-04-29 13:52:03 2841152009-04-29 22:08:13 32898Name: count_7_days, dtype: int64
发现最顶上的7个数据是错误的(时间一样),本节里暂时不去考虑
.rolling('7d'),设置一个窗口
count_7_days = launched.rolling('7d').count()-1 # -1表示不包含当前日期print(count_7_days.head(20)) launched1970-01-01 01:00:00 0.01970-01-01 01:00:00 1.01970-01-01 01:00:00 2.01970-01-01 01:00:00 3.01970-01-01 01:00:00 4.01970-01-01 01:00:00 5.01970-01-01 01:00:00 6.02009-04-21 21:02:48 0.02009-04-23 00:07:53 1.02009-04-24 21:52:03 2.02009-04-25 17:36:21 3.02009-04-27 14:10:39 4.02009-04-28 13:55:41 5.02009-04-29 02:04:21 5.02009-04-29 02:58:50 6.02009-04-29 04:37:37 7.02009-04-29 05:26:32 8.02009-04-29 06:43:44 9.02009-04-29 13:52:03 10.02009-04-29 22:08:13 11.0Name: count_7_days, dtype: float64
%matplotlib inlineimport matplotlib.pyplot as pltplt.rcParams['font.sans-serif'] = 'SimHei'plt.plot(count_7_days[7:]);plt.title("最近7天的数据")plt.show() 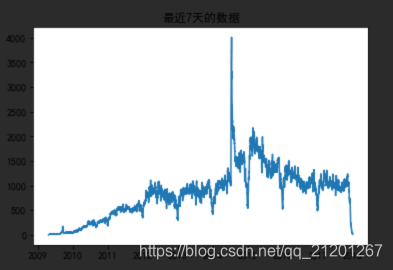
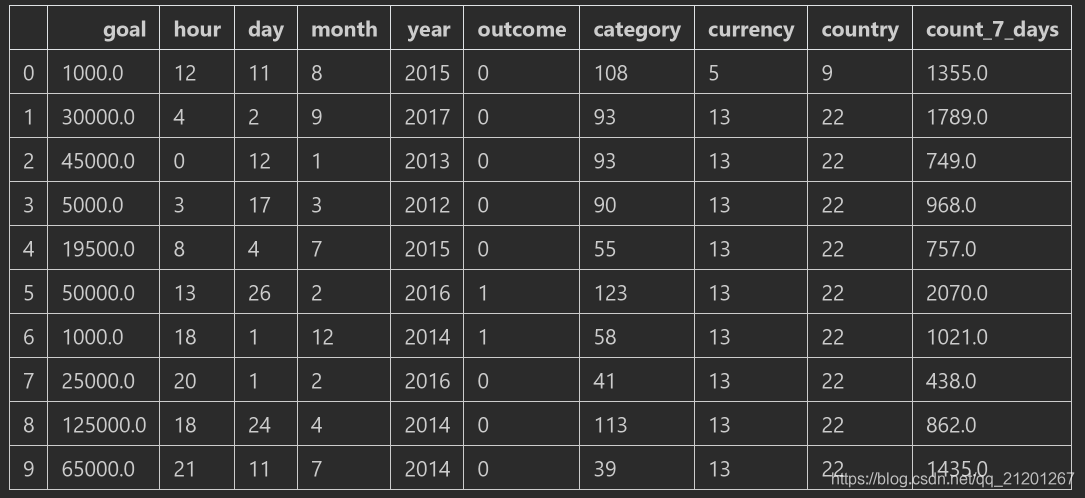
- 把新特征数据,
reindex后,跟原数据合并
count_7_days.index = launched.valuescount_7_days = count_7_days.reindex(ks.index)count_7_days.head(10)
0 1487.01 2020.02 279.03 984.04 752.05 522.06 708.07 1566.08 1048.09 975.0Name: count_7_days, dtype: float64
X.join(count_7_days).head(10),join合并
3. 上一个相同类型的项目的时间
比如,电影之类的上映,如果同类型的扎堆了,可能被对手抢占了份额
def time_since_last_project(series): return series.diff().dt.total_seconds()/3600df = ks[['category','launched']].sort_values('launched')# 按时间排序timedeltas = df.groupby('category').transform(time_since_last_project)# 按分类分组,然后调用函数进行转换,算得上一个同类的时间跟自己的间隔是多少小时timedeltas.head(20) 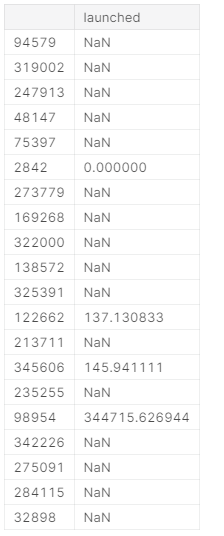
- NaN 表示该类型是第一次出现,填上均值或者中位数
- 然后跟其他数据合并之前需要把index调整成一致
timedeltas = timedeltas.fillna(timedeltas.median()).reindex(X.index)timedeltas.head(20)
4. 转换数值特征
Transforming numerical features,一些模型在数据分布是正态分布的时候,工作的很好,所以可以对数据进行开方、取对数转换
plt.hist(ks.goal, range=(0, 100000), bins=50);plt.title('Goal'); 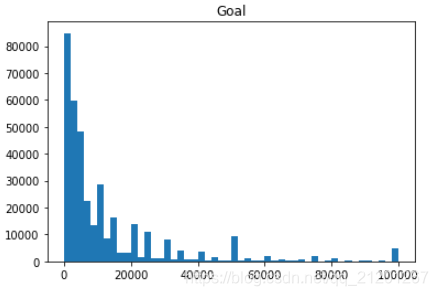
plt.hist(np.sqrt(ks.goal), range=(0, 400), bins=50);plt.title('Sqrt(Goal)'); 
plt.hist(np.log(ks.goal), range=(0, 25), bins=50);plt.title('Log(Goal)'); 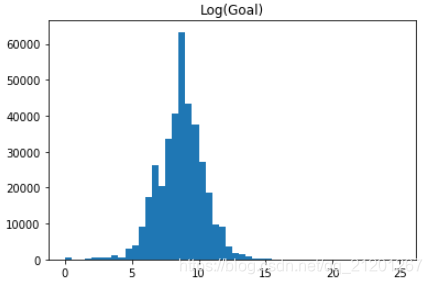
- log 转换对基于树的模型没有什么用,但是对线性模型或者神经网络有用
- 我们需要转成新的特征,然后做一些测试,选择效果最好的转换方法。
上一篇:
下一篇:转载地址:https://michael.blog.csdn.net/article/details/106231673 如侵犯您的版权,请留言回复原文章的地址,我们会给您删除此文章,给您带来不便请您谅解!
发表评论
最新留言
很好
[***.229.124.182]2024年04月28日 02时26分04秒
关于作者

喝酒易醉,品茶养心,人生如梦,品茶悟道,何以解忧?唯有杜康!
-- 愿君每日到此一游!
推荐文章
消息中间件和JMS介绍(一)
2019-05-03
消息中间件-activemq入门(二)
2019-05-03
消息中间件-activemq消息机制和持久化介绍(三)
2019-05-03
消息中间件-activemq实战之整合Spring(四)
2019-05-03
Mybatis Generator最完整配置详解
2019-05-03
光棍节程序员闯关秀过关全攻略(附带小工具)
2019-05-03
Asp.Net MVC4入门指南(1): 入门介绍
2019-05-03
分享ISTQB培训体验
2019-05-03
Asp.Net MVC4入门指南(3):添加一个视图
2019-05-03
我看TechEd 2012之技术热点
2019-05-03
QCon所见和所得:杭州QCon热门技术话题分享
2019-05-03
古城钟楼微博:葡萄城程序员演练技术的产物
2019-05-03
Asp.Net MVC4入门指南(4):添加一个模型
2019-05-03
Asp.Net MVC4入门指南(5):从控制器访问数据模型
2019-05-03
我看TechEd 2012之App时代降临
2019-05-03
WinRT开发语言的功能和效率
2019-05-03
Asp.Net MVC4入门指南(6):验证编辑方法和编辑视图
2019-05-03
Asp.Net MVC4入门指南(8):给数据模型添加校验器
2019-05-03
Asp.Net MVC4入门指南(7):给电影表和模型添加新字段
2019-05-03
白红宇的个人博客 - 记录点点滴滴的事 - 您是第 311859810 位访客
访问时间: 2024-05-08 01:28:28
访问IP: 18.222.125.171
Copyright © 2020 - 2023 blog.css8.cn 京ICP备2021015314号-1
手机版