Spark入门(七)Spark SQL thriftserver/beeline启动方式
发布日期:2021-07-01 01:15:36
浏览次数:3
分类:技术文章
本文共 1051 字,大约阅读时间需要 3 分钟。
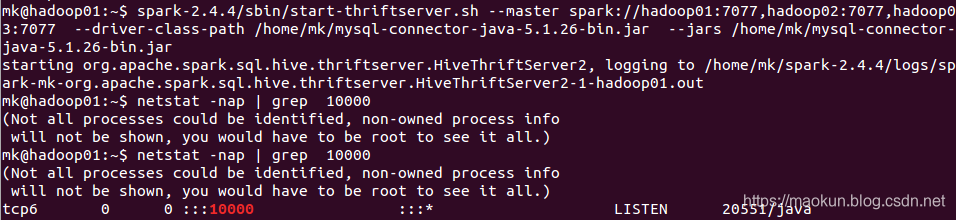
一、启动thrift服务
启动thriftServer,默认端口为10000,。
--jars 添加worker类库
--driver-class-path 驱动类库
--master spark集群地址
--total-executor-cores 启动的核数,默认是所有核数
--executor-memory 每个work分配的内存,默认是work的所有内存
--hiveconf hive.server2.thrift.port 启动端口
spark-2.4.4/sbin/start-thriftserver.sh --master spark://hadoop01:7077,hadoop02:7077,hadoop03:7077 --driver-class-path /home/mk/mysql-connector-java-5.1.26-bin.jar --jars /home/mk/mysql-connector-java-5.1.26-bin.jar --total-executor-cores 2 --executor-memory 1gnetstat -nap | grep 10000
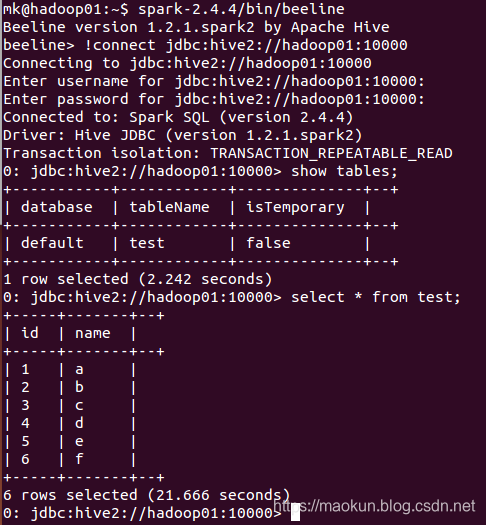
二、启动beeline
spark-2.4.4/bin/beeline#连接!connect jdbc:hive2://hadoop01:10000show tables;select * from test;#退出!quit

三、总结
thriftserver/beeline和普通的spark-shell/spark-sql区别
(1)对于derby存储元数据
1、spark-shell、spark-sql是启动一个spark application,只能服务于唯一的客户端,同一路径启动多客户端会报错; 2、thriftservers是启动一个spark application提供接口服务,为多客户端进行服务。解决了数据共享的问题,多个客户端可以共享数据问题;(2)对于其他非本地的数据库存储元数据
1、spark-shell、spark-sql是启动一个spark application,服务于一个的客户端。可以启动多个spark-shell、spark-sql,客户端之间的操作互相不干扰。
2、thriftservers是启动一个spark application提供接口服务,为多客户端进行服务。如有客户端的操作过多,会干扰到其他客户端的进一步操作。转载地址:https://maokun.blog.csdn.net/article/details/104128223 如侵犯您的版权,请留言回复原文章的地址,我们会给您删除此文章,给您带来不便请您谅解!
发表评论
最新留言
很好
[***.229.124.182]2024年04月10日 06时46分36秒
关于作者

喝酒易醉,品茶养心,人生如梦,品茶悟道,何以解忧?唯有杜康!
-- 愿君每日到此一游!
推荐文章
使用 Minidumps 和 Visual Studio .NET 进行崩溃后调试
2019-05-01
Debug 和 Release 编译方式的本质区别
2019-05-01
struts返回xml数据例子
2019-05-01
内存对齐详解
2019-05-01
秋招总结(一)-C++归纳
2019-05-01
秋招总结(三)-操作系统归纳
2019-05-01
进程间通信
2019-05-01
带缓冲I/O 和不带缓冲I/O的区别与联系
2019-05-01
LINUX CP命令详解
2019-05-01
source insight快捷键及使用技巧
2019-05-01
映 射 ALT 键
2019-05-01
vim使用快捷键F4生成文件头注释、F5生成main函数模板、F6生成.h文件框架模板
2019-05-01
idea 热部署 jrebel 详细配置
2019-05-01
特殊符号大全!
2019-05-01
csdn如何自定义博客栏目
2019-05-01
CSDN博客专栏申请方法
2019-05-01
CSDN博客页面自定义左侧博客栏目
2019-05-01
分布式缓存系统Memcached简介与实践
2019-05-01
IntelliJ IDEA中怎么恢复本地代码
2019-05-01
白红宇的个人博客 - 记录点点滴滴的事 - 您是第 311594508 位访客
访问时间: 2024-05-07 04:37:00
访问IP: 3.137.187.233
Copyright © 2020 - 2023 blog.css8.cn 京ICP备2021015314号-1
手机版