Spark入门(六)Spark SQL shell启动方式(元数据存储在mysql)
发布日期:2021-07-01 01:15:35
浏览次数:2
分类:技术文章
本文共 1891 字,大约阅读时间需要 6 分钟。
一、hive配置文件
在spak/conf目录添加hive-site.xml配置,设置mysql作为元数据存储的数据库
javax.jdo.option.ConnectionURL jdbc:mysql://192.168.150.1:3306/spark_metadata_db?createDatabaseIfNotExist=true&characterEncoding=UTF-8 JDBC connect string for a JDBC metastore javax.jdo.option.ConnectionDriverName com.mysql.jdbc.Driver Driver class name for a JDBC metastore javax.jdo.option.ConnectionUserName root Username to use against metastore database javax.jdo.option.ConnectionPassword admin password to use against metastore database hive.cli.print.header true hive.cli.print.current.db true
二、启动spark-sql shell
--driver-class-path 是spark元数据存储的驱动类路径,这里使用mysql作为metastore,故使用mysql-connector-java-5.1.26-bin.jar
--jars 是executer执行器的额外添加类的路径,这里使用mysql的test表进行操作,故使用mysql-connector-java-5.1.26-bin.jar
--total-executor-cores 启动的核数,默认是所有核数
--executor-memory 每个work分配的内存,默认是work的所有内存
cd ~/software/spark-2.4.4-bin-hadoop2.6bin/spark-sql --master spark://hadoop01:7077,hadoop02:7077,hadoop03:7077 --driver-class-path /home/mk/mysql-connector-java-5.1.26-bin.jar --jars /home/mk/mysql-connector-java-5.1.26-bin.jar --total-executor-cores 2 --executor-memory 1g

启动shell前:
启动shell后:

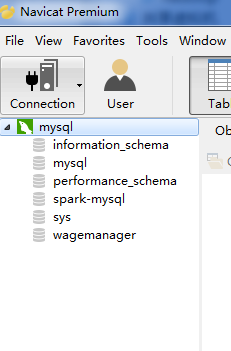
mysql数据库里面创建了spark_metadata_db
三、执行sql
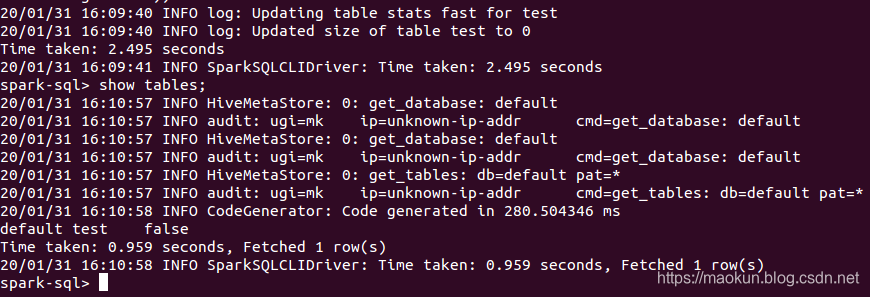
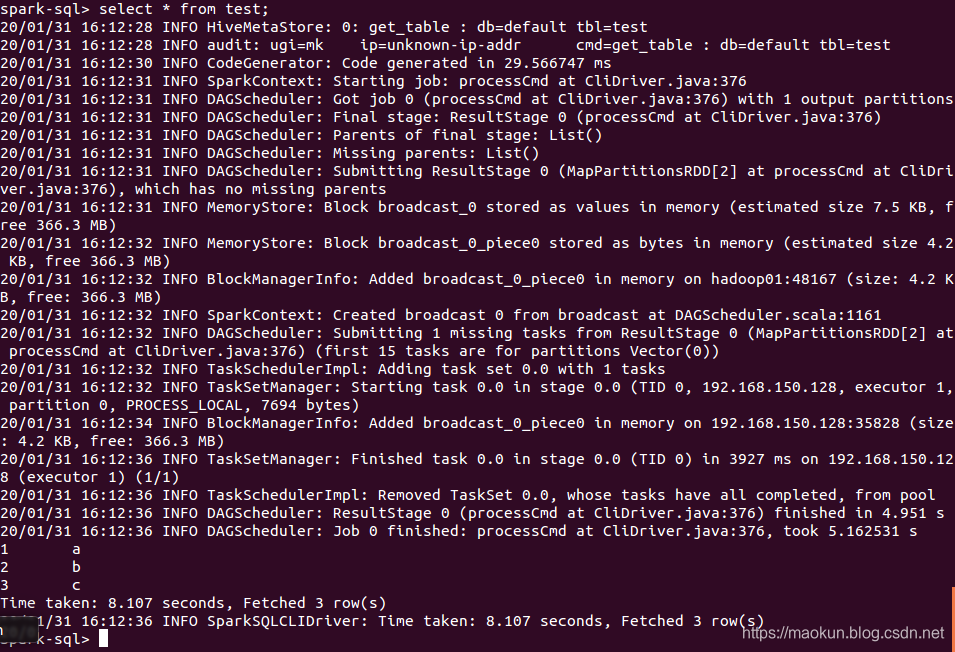
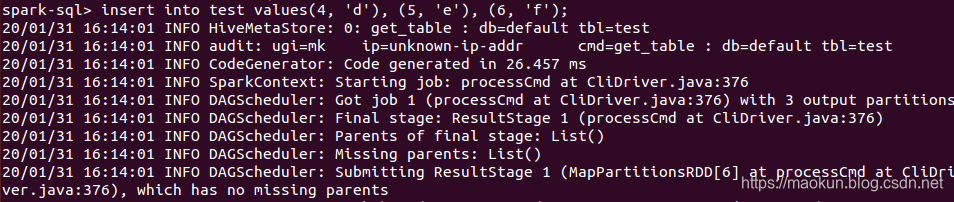
show tables;create table test(id int, name string) USING org.apache.spark.sql.jdbc options(url 'jdbc:mysql://192.168.150.1:3306/spark-mysql?user=root&password=admin', dbtable 'test_a');show tables;select * from test;insert into test values(4, 'd'), (5, 'e'), (6, 'f');select * from test;


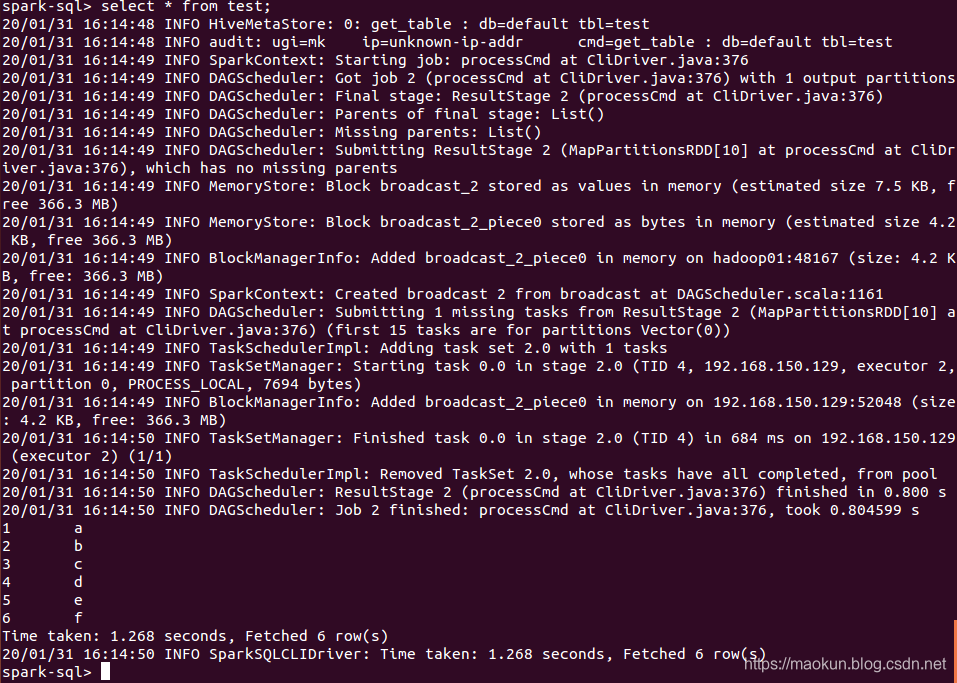
转载地址:https://maokun.blog.csdn.net/article/details/104125008 如侵犯您的版权,请留言回复原文章的地址,我们会给您删除此文章,给您带来不便请您谅解!
发表评论
最新留言
表示我来过!
[***.240.166.169]2024年04月28日 19时09分19秒
关于作者

喝酒易醉,品茶养心,人生如梦,品茶悟道,何以解忧?唯有杜康!
-- 愿君每日到此一游!
推荐文章
锁的释放流程-ReentrantLock.unlock
2019-05-01
锁的释放流程-ReentrantLock.tryRelease
2019-05-01
生产者消费者的实际使用
2019-05-01
序列化的高阶认识-绕开 transient 机制的办法
2019-05-01
分布式架构下常见序列化技术-了解序列化的发展
2019-05-01
Java判断字符串是否为数字(浮点类型也包括)
2019-05-01
Err:11 https://developer.download.nvidia.cn/compute/cuda/repos/ubuntu2004/x86_64 Packages 404 No
2019-05-01
ubuntu opencv-python 安装很慢问题
2019-05-01
cudnn cuda-11.0
2019-05-01
MySQL5.7版本修改了my.ini配置文件后mysql服务无法启动问题
2019-05-01
【大数据开发】Java基础 -总结21-Hashmap和HashTable的区别
2019-05-01
Azkaban体系结构
2019-05-01
机器学习之重头戏-特征预处理
2019-05-01
synchronized底层实现及锁的升级、降级
2019-05-01
PermGen space-永久区内存溢出
2019-05-01
Maven继承和聚合
2019-05-01
nexus发布工程版本问题总结
2019-05-01
windows无法找到发送到桌面快捷方式
2019-05-01
白红宇的个人博客 - 记录点点滴滴的事 - 您是第 311500821 位访客
访问时间: 2024-05-06 21:33:19
访问IP: 3.144.161.116
Copyright © 2020 - 2023 blog.css8.cn 京ICP备2021015314号-1
手机版