实战爬虫:python爬虫学习笔记之爬取搜狗|微信文章——动态网页爬取
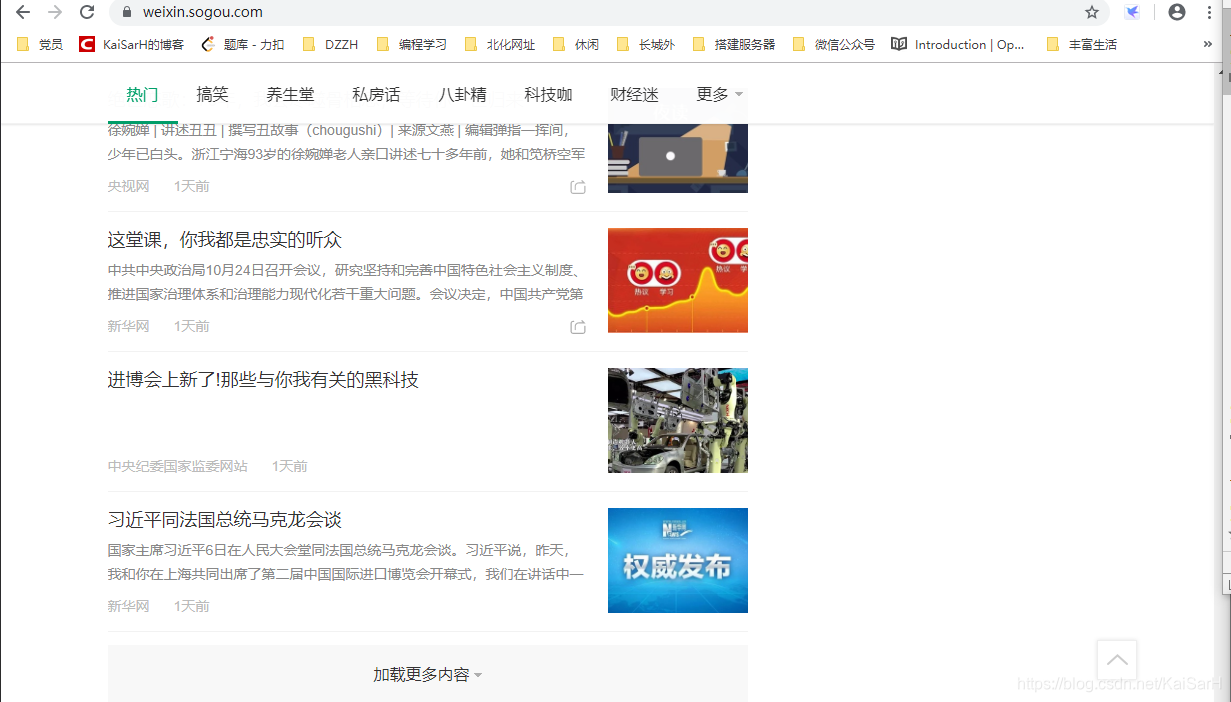 如图,在首页中,下拉会显示加载更多内容那个。在URL未改变的情况加网页发生了变化,由此可知是动态网页。 目标:爬取热门栏目前十页内容。 首先,分析网址,当我们第一次点击加载更多内容时,Network显示,会请求1.html
如图,在首页中,下拉会显示加载更多内容那个。在URL未改变的情况加网页发生了变化,由此可知是动态网页。 目标:爬取热门栏目前十页内容。 首先,分析网址,当我们第一次点击加载更多内容时,Network显示,会请求1.html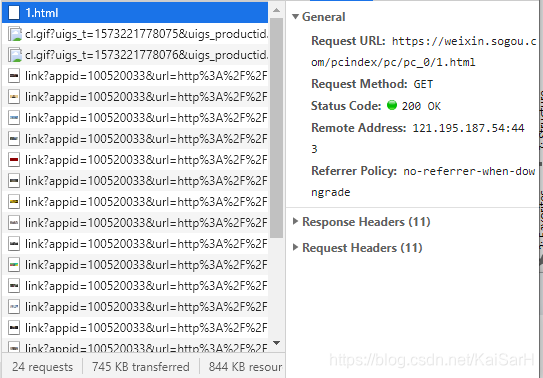 其URL为:https://weixin.sogou.com/pcindex/pc/pc_0/1.html 当我们继续第二次点击加载更多内容时,Network显示,会请求2.html
其URL为:https://weixin.sogou.com/pcindex/pc/pc_0/1.html 当我们继续第二次点击加载更多内容时,Network显示,会请求2.html 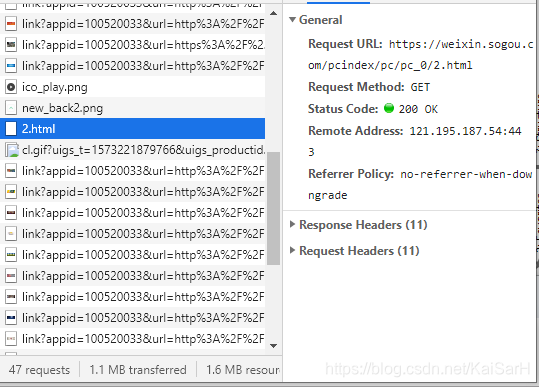 其URL为:https://weixin.sogou.com/pcindex/pc/pc_0/2.html 继续点击,请求3.html
其URL为:https://weixin.sogou.com/pcindex/pc/pc_0/2.html 继续点击,请求3.html  其URL为:https://weixin.sogou.com/pcindex/pc/pc_0/3.html 由此类推,搜狗|微信首页的加载更多内容是通过请求不同的url来进行加载的。 我们如果爬取前十页内容,只需要根据规律构造URL,进行爬取即可。
其URL为:https://weixin.sogou.com/pcindex/pc/pc_0/3.html 由此类推,搜狗|微信首页的加载更多内容是通过请求不同的url来进行加载的。 我们如果爬取前十页内容,只需要根据规律构造URL,进行爬取即可。 

发布日期:2021-06-30 15:42:16
浏览次数:2
分类:技术文章
本文共 2786 字,大约阅读时间需要 9 分钟。
本文是我在使用网易云课堂学习日月光华老师讲的“Python爬虫零基础入门到进阶实战”课程所做的笔记,如果大家觉得不错,可以去看一下老师的视频课,讲的还是很棒的。
1. 动态网页
所谓动态网页,是跟静态网页相对应的一种网页编程技术。静态网页随着HTML代码的生成,页面的内容和显示效果就基本上不会发生变化了——除非修改页面代码,而动态网页则不然,页面代码虽然没有变化,但是显示的内容却是可以随着时间、环境或者数据库操作的结果而发生该百年的。
动态网页一般使用叫做AJAX的快速动态创建网页技术,通过在后台与服务器进行少量数据交换,AJAX可以使网页实现异步更新。这意味着可以在不重新加载整个网页的情况下,对王爷的某部分内容进行更新。2. 判断一个网页是不是动态网页
- 是否在URL不变或者未刷新的情况下,能够加载新的信息。
- 网页的源代码结构与显示不同
3. 动态网页的爬取办法
- 分析网页请求,查找真实请求的URL
- 使用Selenium模拟浏览器行为
4. 实例:爬取搜狗|微信文章

如图,在首页中,下拉会显示加载更多内容那个。在URL未改变的情况加网页发生了变化,由此可知是动态网页。 目标:爬取热门栏目前十页内容。 首先,分析网址,当我们第一次点击加载更多内容时,Network显示,会请求1.html 其URL为:https://weixin.sogou.com/pcindex/pc/pc_0/1.html 当我们继续第二次点击加载更多内容时,Network显示,会请求2.html 其URL为:https://weixin.sogou.com/pcindex/pc/pc_0/2.html 继续点击,请求3.html 其URL为:https://weixin.sogou.com/pcindex/pc/pc_0/3.html 由此类推,搜狗|微信首页的加载更多内容是通过请求不同的url来进行加载的。 我们如果爬取前十页内容,只需要根据规律构造URL,进行爬取即可。 import requestsfrom lxml import etree# 引入random是为了可以随机的从代理IP中抽取一个IPimport random# punctuation为标点符号集,为了删除文章题目中的标点符号from string import punctuationimport reimport timedef download(url): """ 下载网址内容,返回选择器 :param url: 网址 :return: 对应网址选择器 """ headers = { 'User-Agent': 'Mozilla/5.0 (Windows NT 10.0; Win64; x64) AppleWebKit/537.36 (KHTML, like Gecko) Chrome/78.0.3904.70 Safari/537.36'} # 定义代理IP列表 time.sleep(2) proxies = [ { "HTTPS": "https://117.69.201.218:24907"}, { "HTTPS": "https://117.57.91.57:46149"}, { "HTTPS": "https://117.91.133.18:9999"}, { "HTTPS": "https://183.129.207.78:18118"} ] # random.choice 从列表中随机选取一个 r = requests.get(url, proxies=random.choice(proxies), headers=headers) # r = requests.get(url, headers=headers) # 设置编码方式 r.encoding = 'utf-8' return etree.HTML(r.text)def spider_detail(article_url): """ 爬取某一篇文章的标题和内容,并写文件 :param article_url: 文章URL """ selector = download(article_url) title = selector.xpath('//h2[@class="rich_media_title"]/text()')[0].strip() content = selector.xpath('string(//*[@class="rich_media_content "])').strip() data_write(content, title)def data_write(content, title): """ 保存文章的题目和内容 # 在字符串前面加上一个r表示原生字符串 # 不转义字符不需要再次被转义 # 即字符串均为显示内容,无任何转义内容 :param content: 内容 :param title: 题目 """ title = re.sub(r'[{}]+'.format(punctuation), '', title) with open('./wenzhang/' + title + '.txt', 'wt', encoding='utf-8') as f: f.write(content) print('正在下载:', title)def spider(num): for i in range(1, num+1): url = 'https://weixin.sogou.com/pcindex/pc/pc_0/{}.html'.format(i) selector = download(url) all_article = selector.xpath('/html/body/li') for article in all_article: article_url = article.xpath('div[2]/h3/a/@href')[0] spider_detail(article_url)page_count = input("请输入您想爬取的页数:")spider(page_count) 运行结果:
转载地址:https://kaisarh.blog.csdn.net/article/details/102980421 如侵犯您的版权,请留言回复原文章的地址,我们会给您删除此文章,给您带来不便请您谅解!
发表评论
最新留言
哈哈,博客排版真的漂亮呢~
[***.90.31.176]2024年04月16日 14时38分11秒
关于作者

喝酒易醉,品茶养心,人生如梦,品茶悟道,何以解忧?唯有杜康!
-- 愿君每日到此一游!
推荐文章
喜欢玩王者荣耀的有福了,用 Python 获取英雄皮肤壁纸
2019-05-01
一名数据分析师的SQL学习历程
2019-05-01
图解《金字塔原理》,7步掌握其精华!
2019-05-01
数据分析入门选择Python还是SQL?七个常用操作对比!
2019-05-01
最后一台,i7+6核电脑
2019-05-01
redis五种基本数据类型
2019-05-01
springboot整合redis框架
2019-05-01
以不同业务,redis分库概念
2019-05-01
使用redis实现订阅功能
2019-05-01
Redis主从配置
2019-05-01
Redis哨兵机制
2019-05-01
哨兵机制服务器环境准备
2019-05-01
携程Apollo动态配置日志级别
2019-05-01
SpringBoot整合Redis事务
2019-05-01
项目整合一级缓存和二级缓存
2019-05-01
自定义注解和aop抽取重复代码
2019-05-01
互联网API开放平台安全设计-基于OAuth2.0协议方式
2019-05-01
URL特殊字符转码
2019-05-01
对称加密整个过程
2019-05-01
java内存模型
2019-05-01
白红宇的个人博客 - 记录点点滴滴的事 - 您是第 311302839 位访客
访问时间: 2024-05-06 06:57:23
访问IP: 3.149.26.246
Copyright © 2020 - 2023 blog.css8.cn 京ICP备2021015314号-1
手机版