爬虫:学习笔记之常见反爬虫策略及应对技巧
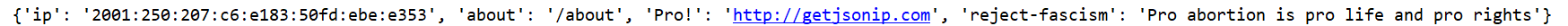
发布日期:2021-06-30 15:42:15
浏览次数:2
分类:技术文章
本文共 1133 字,大约阅读时间需要 3 分钟。
本文是我在使用网易云课堂学习日月光华老师讲的“Python爬虫零基础入门到进阶实战”课程所做的笔记,如果大家觉得不错,可以去看一下老师的视频课,讲的还是很棒的。
常见反爬虫策略: 一、通过Headers反爬虫 二、基于用户行为反爬虫 三、动态页面反爬虫 四、Else 应对反爬虫的方法: 1、设置Headers 2、使用IP代理或加大请求间隔时间 3、使用Selenium框架1. 通过识别用户代理(Headers) 反爬虫
应对:设置Headers(User-Agent)。基本所有的爬虫都要设置Headers,不然很容易被反爬虫识别。
2. 基于用户行为反爬虫
检测用户行为,比如短时间快速爬取
应对:使用或加大请求间隔时间,如果请求间隔时间固定,有可能也会被检查出来。2.1 代理IP
所谓代理IP,就是代理用户去取得网络信息的IP地址。代理IP可以帮助爬虫掩藏真实身份,突破IP访问限制,隐藏爬虫的真实IP,从而避免被网站反爬虫禁止。
2.2 Requests中使用代理IP的方法
在get方法中加入proxies属性。
代理IP组成的字典{ 请求方式:代理IP地址 } ps:字典小知识:字典用键值对存储数据,如果多个key名相同,那么最后一个有效。 因此,如果代理IP地址很多,可以每一个代理IP设置为一个字典,最后所有的代理IP设置为一个列表,从列表中随机获取。import requestsproxies = { # :后面为端口 "http": "http://27.152.90.179:9999", "https": "1.197.16.144:9999",}requests.get("http://example.org",proxies=proxies) 2.3 如何获得代理IP
- 使用免费代理IP 从实用性、稳定性以及安全性来考虑,不推荐使用免费的代理IP。
- 购买代理IP
2.4 代理IP使用
import requestsproxies = { # :后面为端口 'http': 'http://123.169.101.109:9999',}print(requests.get('https://jsonip.com', proxies=proxies).json()) 执行结果:
3. 动态网页面反爬虫
动态网页很多东西由JavaScript生成,通过Ajax请求得到数据。
应对:使用Selenium框架,该框架可以模拟人的操作,打开浏览器。用浏览器请求。4. Eles
比如:使用cookies反爬虫。
应对:第一次访问后设置cookies,后续访问设置cookie。转载地址:https://kaisarh.blog.csdn.net/article/details/102978749 如侵犯您的版权,请留言回复原文章的地址,我们会给您删除此文章,给您带来不便请您谅解!
发表评论
最新留言
关注你微信了!
[***.104.42.241]2024年04月14日 13时08分01秒
关于作者

喝酒易醉,品茶养心,人生如梦,品茶悟道,何以解忧?唯有杜康!
-- 愿君每日到此一游!
推荐文章
COMP7404 Machine Learing——ROC
2019-04-30
MATLAB与CUDA
2019-04-30
Linux png转jpg (convert命令)
2019-04-30
Ubuntu更新后终端中字体的颜色全是白色
2019-04-30
vscode git
2019-04-30
基于MATLAB的二进制数字调制与解调信号的仿真——2PSK
2019-04-30
基于MATLAB的模拟调制信号与解调的仿真——DSB
2019-04-30
HDU - 1166 敌兵布阵 (树状数组模板题/线段树模板题)
2019-04-30
CodeForces - 761C Dasha and Password (思维 暴力)
2019-04-30
CodeForces - 456C Boredom (dp)
2019-04-30
CodeForces - 675A Infinite Sequence(简单数论 细节)
2019-04-30
CodeForces - 1042B Vitamins (思维)
2019-04-30
ACM 2013 长沙区域赛 Collision (几何)
2019-04-30
ACM 2014 鞍山区域赛 E - Hatsune Miku (dp)
2019-04-30
反向传播&梯度下降 的直观理解程序(numpy)
2019-04-30
CodeForces - 931B World Cup (思维 模拟)
2019-04-30
ACM 2017 北京区域赛 J-Pangu and Stones(区间dp)
2019-04-30
java常用类 String面试题
2019-04-30
白红宇的个人博客 - 记录点点滴滴的事 - 您是第 311304165 位访客
访问时间: 2024-05-06 07:08:01
访问IP: 3.135.197.201
Copyright © 2020 - 2023 blog.css8.cn 京ICP备2021015314号-1
手机版