8 提升方法
发布日期:2021-06-29 18:40:48
浏览次数:2
分类:技术文章
本文共 4563 字,大约阅读时间需要 15 分钟。
文章目录
- boosting:常用的统计学习法,广泛有效
- 分类问题中,它改变训练样本权重,学习多个分类器
- 并将这些分类器线性组合
- 先介绍提升方法的思路和代表性的提升算法Adaboost
- 然后通过训练误差分析它为什么能提高学习精度
- 从前向分步加法模型角度解释Adaboost
- 最后提升方法更具体实例,boostingtree
- Adaboost 95年由Freund和Schapire
- 提升树是00由Friedman等
8.1提升方法 Adaboost算法
8.1.1提升方法的基本思路
- 提升方法基于:
- 对一个复杂任务,
- 将多个专家的判断进行适当的综合所得出的判断,
- 要比其中任何一个专家单独的判断好
- Kearns和 Valiant提出strongly learnable”和“ weakly
- 在概率近似正确( probably approximately correct,PAC)学习的框架中,一个概念(一个类)
- 如果存在一个多项式的学习算法能学习它,且正确率很高
- 这个概念是强可学习的
- 如果存在一个多项式的学习算法能够学习它,正确率仅比随机猜测略好
- 称这个概念是弱可学习的
- Schapire证明
- 在PAC学习的框架下
- 一个概念是强可学习 ⟺ \iff ⟺这个概念是弱可学习的
- 如果已发现“弱学习算法”,能否将它boost为“强学习算法”
- 弱学习算法通常比发现强学习算法容易
- 如何具体实施提升,便成为开发提升方法时要解决的,
- 提升方法的研究很多,
- 最具代表性的是Adaboost算法
- 对分类问题,给定一个训练样本集,求较粗糙的分类规则(弱分类器)要比求精确的分类规则(强分类器)容易多
- 提升方法从弱学习算法出发,
- 反复学习,
- 得到一系列弱分类器(基本分类器),
- 然后组合这些弱分类器,构成强分类器
- 多数提升方法都改变训练数据概率分布(训练数据的权值分布),针对不同训练数据分布调用弱学习算法学习一系列弱分类器
- 对提升方法,有两问题
- 每轮如何改变训练数据的权值或概率分布
- 如何将弱分类器组合成一个强分类器
- Adaboost提高那些被前一轮弱分类器错误分类样本的权值,降低那些被正确分类的权值.
- 那些没正确分类的数据,
- 其权值的加大而受到后一轮的弱分类器的更大关注
- Adaboost采取加权多数表决的方法
- 加大分类误差率小的弱分类器的权值,使其在表决中大作用,
- 减小分类误差率大的弱分类器的权值
- Adaboost的巧妙在于它将这些想法自然有效地实现在一种算法
8.1.2 Adalboost算法
- { − 1 , 1 } \{-1,1\} { −1,1}
- Adaboost
- 从训练数据中学习一系列弱分类器
- 并将这些弱分类器线性组合成为一个强分类器
- 算法8.1
- 输入:训练数据集 N N N个,弱学习算法
- 输出:最终分类器 G ( x ) G(x) G(x)
- (1)
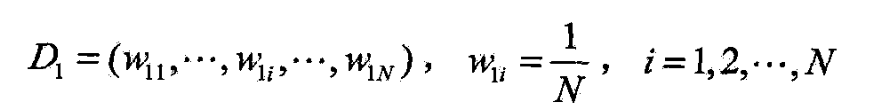
- (2)对 m = 1 , 2 , ⋯ , M m=1,2,\cdots,M m=1,2,⋯,M
- a)用权值分布 D m D_m Dm的训练集学习,得基本分类器
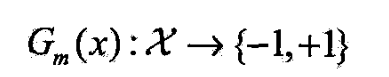
- (b)计算 G m ( x ) G_m(x) Gm(x)在训练集上的分类误差率
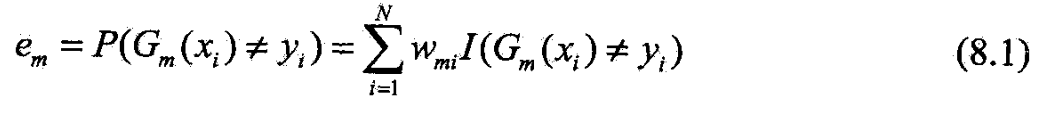
- ©计算 G m ( x ) G_m(x) Gm(x)的系数

-
自然对数
-
(d) 更新训练数据集的权值分布
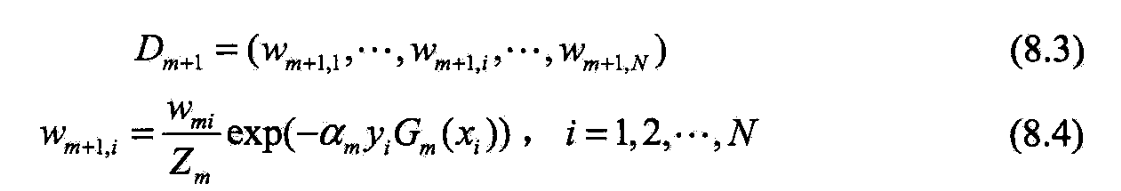
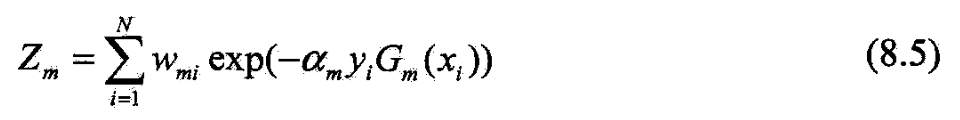
- 它使 D m + 1 D_{m+1} Dm+1成为一个概率分布
- (3)构建基本分类器的线性组合

- 得最终分类器
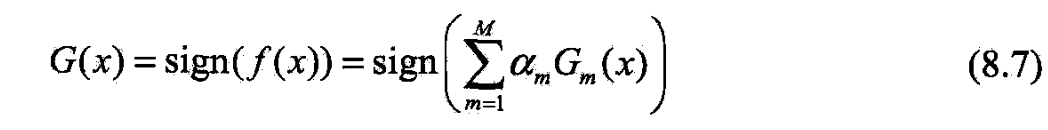
- 步骤(1)保证第1步能够在原始数据上学习基本分类器 G 1 ( x ) G_1(x) G1(x)
- 步骤(2) Adaboost反复学习基本分类器
- 在每轮 m = 1 , 2 , ⋯ , M m=1,2,\cdots,M m=1,2,⋯,M
- (a)用 D m D_m Dm加权的训练数据
- 学习基本分类器 G m ( x ) G_m(x) Gm(x)
- (b) G m ( x ) G_m(x) Gm(x)在加权数据集上的误差率
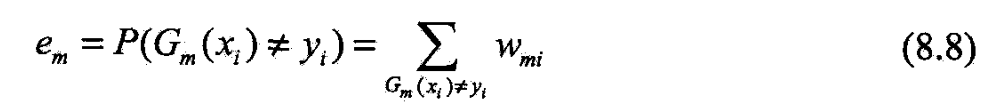
-
w m i w_{mi} wmi:第 m m m轮中第 i i i个实例权值,
- ∑ i = 1 N w m i = 1 \sum_{i=1}^N w_{mi}=1 ∑i=1Nwmi=1
-
G m ( x ) G_m(x) Gm(x)在加权训练数据集上的分类误差率是被 G m ( x ) G_m(x) Gm(x)误分类样本的权值和
-
© G m ( x ) G_m(x) Gm(x)的系数 α m \alpha_m αm,
- 由(8.2),当 e m ≤ 1 2 e_m\le \frac 12 em≤21时, α m ≥ 0 \alpha_m\ge 0 αm≥0,且随 e m e_m em减小增大
- 所以啥
-
(d)更新训练数据的权值分布为下一轮作准备.
- (8.4)写成
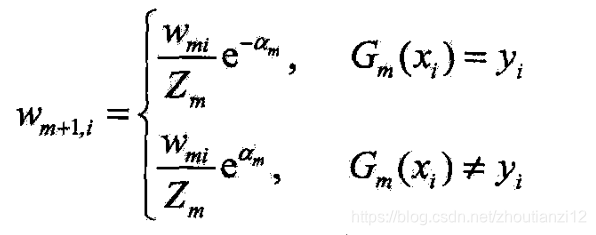
- 被 G m ( x ) G_m(x) Gm(x)误分类样本的权值扩大,而被正确分类的权值缩小,
- 误分类样本的权值被放大
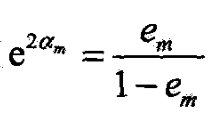
- 不改变所给的训练数据,而不断改变训练数据权值的分布,使训练数据在基本分类器的学习中起不同的作用,
- 这是Adaboost的一个特点.
- 步骤(3)
- 线性组合实现 M M M个基本分类器的加权表决
- 所有系数之和并不为1
- f(x)的符号決定实例x的类
- f(x)的绝对值表示分类的确信度
- 用基本分类器的线性组合构建最终分类器是Adaboost另一特点,
8.1.3 Adaboost的例子
- 例8.1
- 弱分类器由x<v或x>v产生,
- 阙值ν使分类器在训练集上误差率最低
- Adaboos学一个强分类器

- 初始化数据权值分布

- m=1;
- (a)在权值分布为 D 1 D_1 D1的训练数据上,
- 2.5时分类误差率最低,
- 故基本分类器为
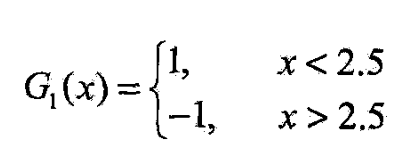
这儿好多没有写啊
8.2 Adaboost算法的训练误差分析
- Adaboost能在学习过程中不断减少
- 训练集上的分类误差率
- 定理8.1
- Adaboost最终分类器的训练误差界为
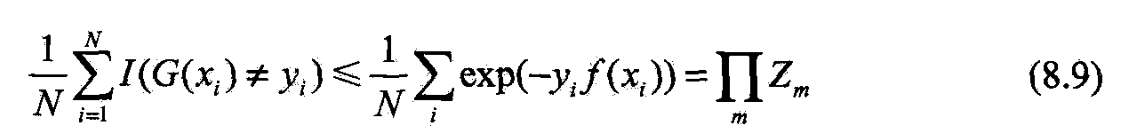
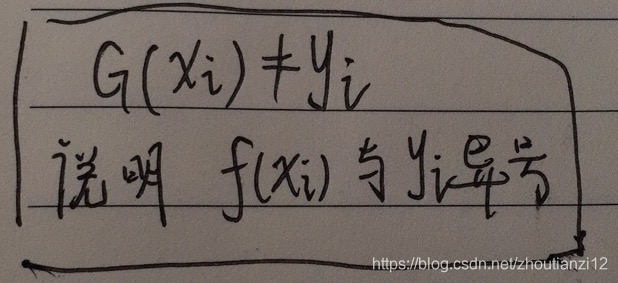
- 后半部分的推导要用到 Z m Z_m Zm的定义(8.5)及式(8.4)的变形

- 可在每一轮选取适当的 G m G_m Gm使 Z m Z_m Zm最小
- 从而使训练误差下降最快
- 对二类分类问题,有如下结果
8.3 Adaboost算法的解释
- 可认为Adaboost是模型为加法模型、
- 损失函数为指数函数、
- 学习算法为前向分步算法
- 时的二类分类学习方法
8.3.1前向分步算法
- 考虑加法模型

- 为基函数,
- 基函数的参数,
- 为基函数的系数.
- 式(8,6)是一个加法模型
- 给定训练数据及损失函数 L ( y , f ( x ) ) L(y,f(x)) L(y,f(x))
- 学习加法模型 f ( x ) f(x) f(x)成为经验风险极小化
- 即损失函数极小化问题
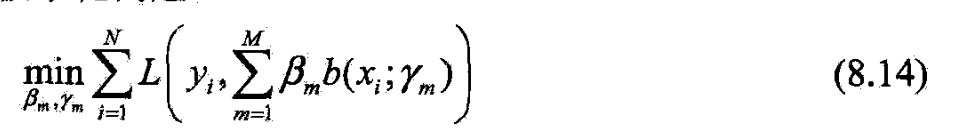
- 前向分步算法求解想法:
- 因为学习的是加法模型,如果能从前向后,每一步只学习一个基函数及其系数,逐步逼近优化目标函数式(8.14),就可简化优化复杂度
- 每步只需优化如下损失函数

- 给定训练数据集
- 损失函数
- 基函数的集合
- 学习加法模型的前向分步算法:
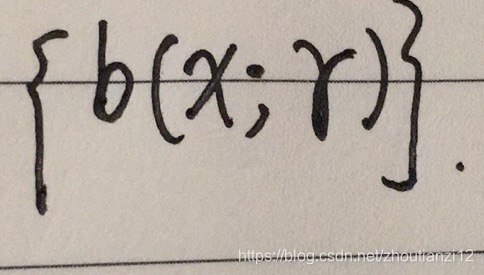
- 初始化 f 0 ( x ) = 0 f_0(x)=0 f0(x)=0
- (2)对 m = 1 , 2 , ⋯ , M m=1,2,\cdots,M m=1,2,⋯,M
- (a)极小化损失函数
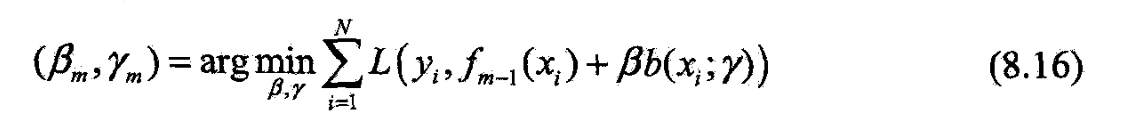
- 得到参数
- (b)更新
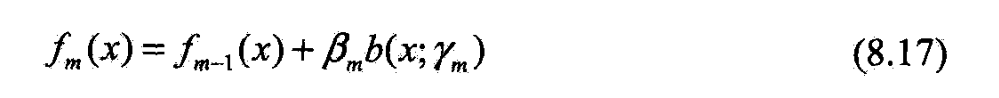
(3)得加法模型

- 前向分步算法将同时求解从m=1到M所有参数Bn,yn的优化问题
- 简化为逐次求解各个Bn,yn的优化问题
8.3.2前向分步算法与 Adaboost
- 定理8.3
- Adaboost是前向分步加法算法的特例.
- 模型由基本分类器组成的加法模型,
- 损失函数是指数函数
- 前向分步算法学习的是加法模型,
- 当基函数为基本分类器时,
- 该加法模型等价于Adaboost最终分类器

- 由基本分类器 G m ( x ) G_m(x) Gm(x)及系数 α m \alpha_m αm组成
- 前向分步算法逐一学习基函数,这一过程与Adaboost逐一学习基本分类器的过程一致.
- 下证前向分步算法的损失函数是指数损失函数
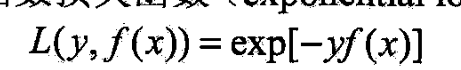
- 时,其学习的具体操作等价于Adaboost学习的具体操作
- 设经 m − 1 m-1 m−1轮送代前向分步算法已得到 f m − 1 ( x ) f_{m-1}(x) fm−1(x)
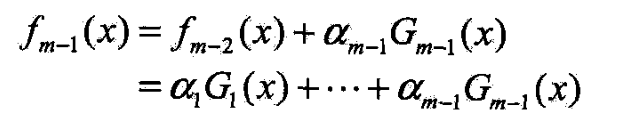
- 第m轮得到 α m \alpha_m αm, G m ( x ) G_m(x) Gm(x)和 f m ( x ) f_m(x) fm(x)
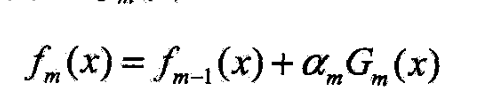
- 目标是使前向分步算法得到的 α m \alpha_m αm, G m ( x ) G_m(x) Gm(x)和 f m ( x ) f_m(x) fm(x)
- 使在训练数据集7上的指数损失最小
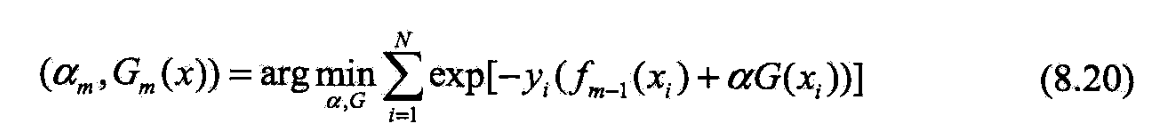
- 式8.20可表示为
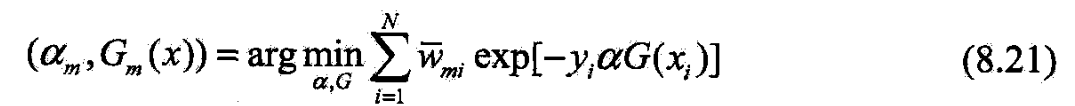
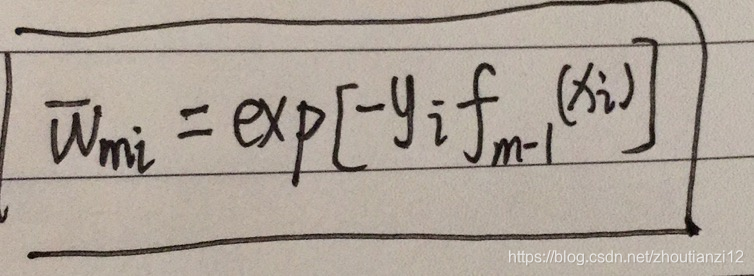
- 既不依赖也不依赖于G,所以与最小化无关
- 但依赖于,随着每一轮迭代而发生改变.
- 现证使(8,21)最小的和G(x)就是Adaboost的cn和Gn(x).
- 求解(8.21)分两步
- 求 G m ∗ ( x ) G_m^*(x) Gm∗(x)
- 对任 α > 0 \alpha>0 α>0,使(8.21)最小的 G ( x ) G(x) G(x)由下式得到
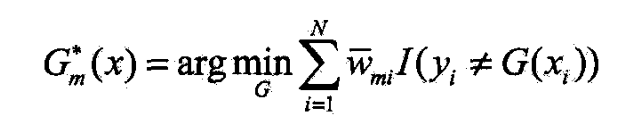
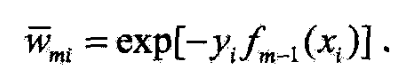
- 此分类器 G m ∗ ( x ) G_m^*(x) Gm∗(x)即为Adaboost的基本分类器 G m ( x ) G_m(x) Gm(x)
- 它使第 m m m轮加权训练数据分类误差率最小的基本分类器
- 之后,求 α m ∗ \alpha_m^* αm∗
- 参照(8.11),(8.21)
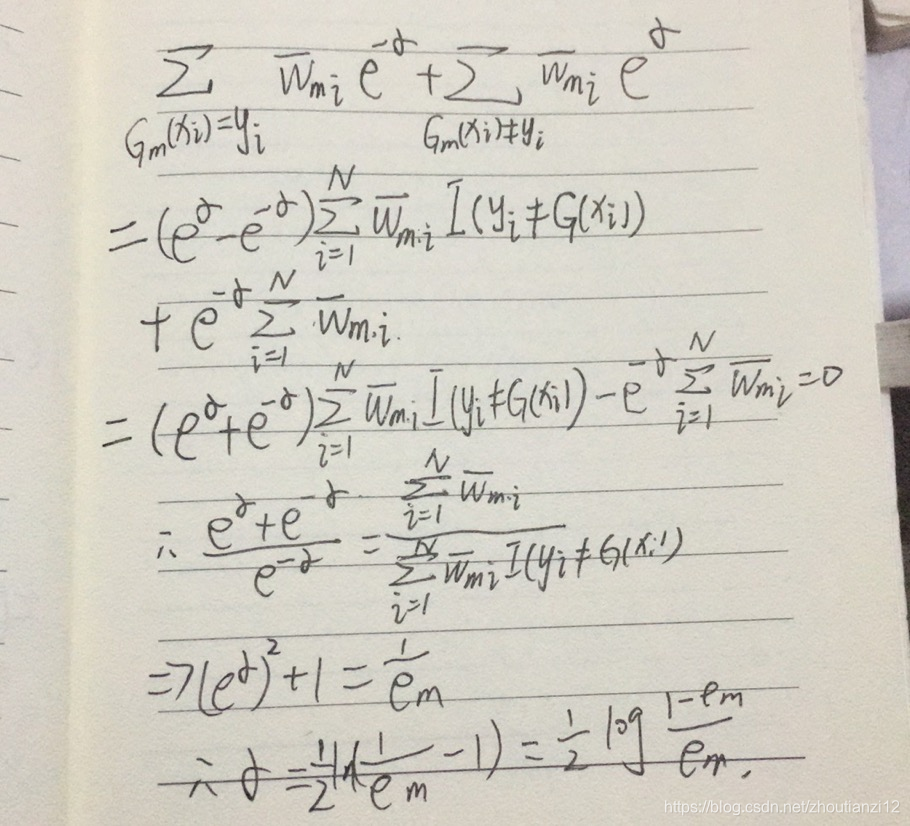
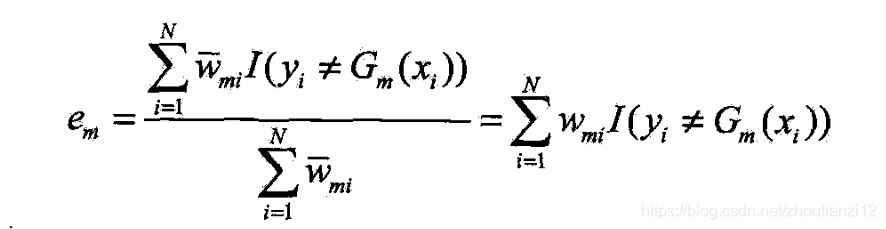
- 每一轮样本权值的更新,由
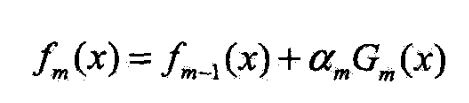
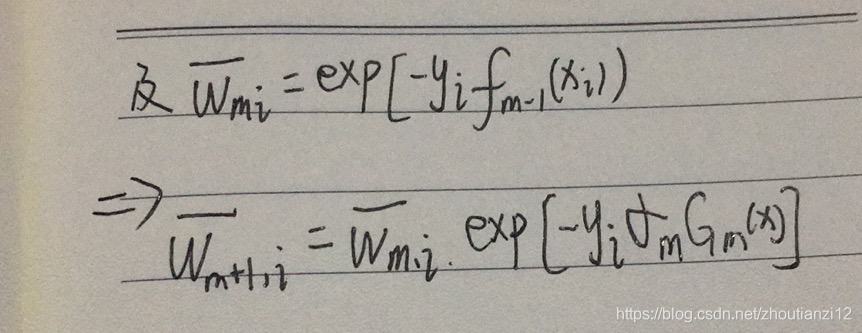
- 这与 Adaboost2(d)步的样本权值的更新,
- 只相差规范化因子,因而等价
8.4提升树
- 以分类树或回归树为基本分类器的提升方法.
- 统计学习中性能最好的方法之一
8.4.1提升树模型
- 提升方法实际采用加法模型(基函数的线性组合)与前向分步算法.
- 以决策树为基函数的提升方法称提升树
- 分类问题决策树是二又分类树,
- 回归问题决策树是二叉回归树,
- 例8.1中看到的基本分类器x< v 或 x> v,
- 可看作是由一个根结点直接连接两个叶结点的简单决策树,
- 即决策树柱( decision stump).
- 提升树模型可表示为决策树的加法模型
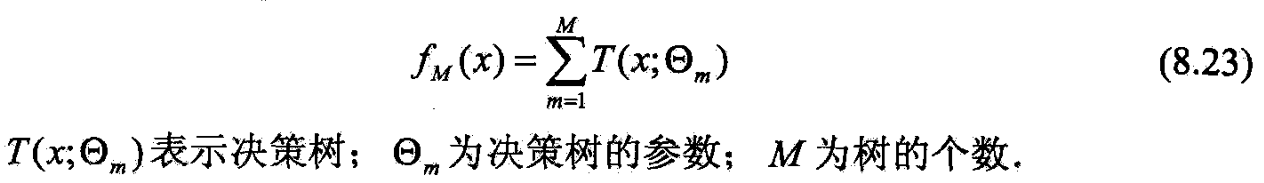
8.4.2提升树算法
- 提升树算法采用前向分步算法.
- 先确定初始提升树 f 0 ( x ) = 0 f_0(x)=0 f0(x)=0
- 第m步的模型是
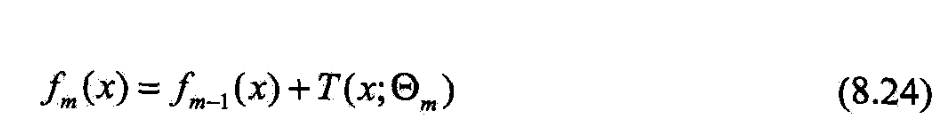
- f m − 1 ( x ) f_{m-1}(x) fm−1(x)为当前模型,
- 经验风险极小化确定下一棵决策树的参数 Θ m \Theta_m Θm
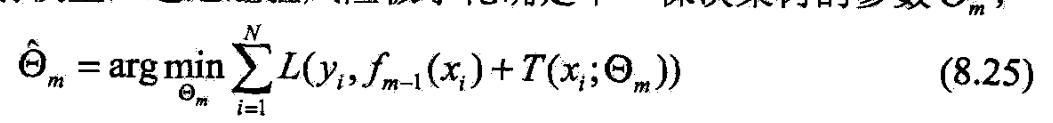
- 树的线性组合可很好拟合训练数据
- 即使数据中的输入与输出之间的关系很复杂也如此,
- 所以提升树是高功能的学习算法.
- 不同问题的提升树学习算法,主要区别在于使用的损失函数.
- 平方误差损失函数的回归问题,
- 指数损失函数的分类问题,
- 一般损失函数的一般决策问题
- 对二分类,提升树算法只将Adaboost中的基本分类器限制为二分类树即可,这时的提升树算法是 Adaboost算法的特殊
- 下叙述回归问题的提升树
转载地址:https://cyj666.blog.csdn.net/article/details/104850667 如侵犯您的版权,请留言回复原文章的地址,我们会给您删除此文章,给您带来不便请您谅解!
发表评论
最新留言
哈哈,博客排版真的漂亮呢~
[***.90.31.176]2024年05月02日 14时26分48秒
关于作者

喝酒易醉,品茶养心,人生如梦,品茶悟道,何以解忧?唯有杜康!
-- 愿君每日到此一游!
推荐文章
asp.net core 类库获取appsettings.json的值
2019-04-30
asp.net core ef Scaffold-DbContext
2019-04-30
从零开始实现ASP.NET Core MVC的插件式开发
2019-04-30
DDD学习一
2019-04-30
asp.net core学习一
2019-04-30
ASP.NET Core in2020
2019-04-30
依赖倒置来反转依赖
2019-04-30
asp.net core mvc/api部署到iis
2019-04-30
asp.net core launchsettings.json
2019-04-30
DDD&TDD
2019-04-30
asp.net core
2019-04-30
visual svn for visual studio 2019
2019-04-30
asp.net core 学习二
2019-04-30
asp.net core NLog 配置
2019-04-30
知识点-Concul
2019-04-30
asp.net core Ocelot
2019-04-30
C#中使用TransactionScope类(分布式事务)
2019-04-30
几种开发方式
2019-04-30
Microsoft SQL Server 2019 安装服务没有及时响应启动或控制请求。
2019-04-30
白红宇的个人博客 - 记录点点滴滴的事 - 您是第 310323996 位访客
访问时间: 2024-05-03 12:46:00
访问IP: 18.191.102.112
Copyright © 2020 - 2023 blog.css8.cn 京ICP备2021015314号-1
手机版