4 朴素贝叶斯法
发布日期:2021-06-29 18:40:47
浏览次数:3
分类:技术文章
本文共 1448 字,大约阅读时间需要 4 分钟。
文章目录
- 朴素贝叶斯法是基于贝叶斯定理与特征条件独立假设的分类 方法
- 对给定的训练数据集,先基于特征条件独立假设学习输入输出的联合 概率分布;
- 然后基于此模型,
- 对给定输入 x x x,用贝叶斯定理求出后验概率最大的输出 y y y.
- 朴素贝叶斯法实现简单,学习与预测的效率都很高,是一种常用的方法
- 本章朴素贝叶斯法,
- 包括朴素贝叶斯法的学习与分类、朴素贝叶斯法的参数估计算法
4.1 朴素贝叶斯法的学习与分类
4.1.1 基本方法
- 输入空间 X ⊆ R n \mathcal{X}\subseteq R^n X⊆Rn
- 输出空间为类标记集合 Y = { c 1 , . . . , c K } \mathcal{Y}=\{c_1,...,c_K\} Y={ c1,...,cK}
- 特征向量 x ∈ X x\in\mathcal{X} x∈X,输出为类标记( class label) y ∈ Y y\in\mathcal{Y} y∈Y
- X X X是输入空间况上的随机向量, Y Y Y是输出空间上的随机变量
- P ( X , Y ) P(X,Y) P(X,Y)是 X X X和 Y Y Y的联合概率分布,
- 训练数据集
T = { ( x 1 , y 1 ) , . . . , ( x N , y N ) } T=\{(x_1,y_1),...,(x_N,y_N)\} T={ (x1,y1),...,(xN,yN)}
- 由 P ( X , Y ) P(X,Y) P(X,Y)独同产生
- 朴素贝叶斯法通过训练数据集学习联合概率分布 P ( X , Y ) P(X,Y) P(X,Y)
- 学习先验概率分布
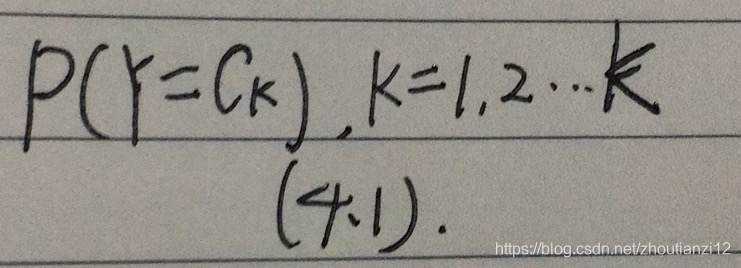
- 条件概率分布
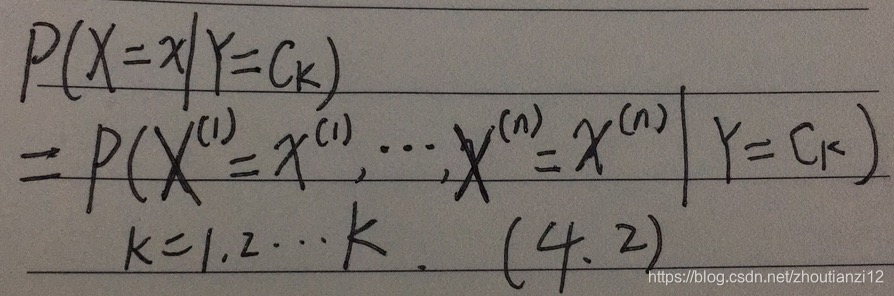
- 于是学到联合概率分布 P ( X , Y ) P(X,Y) P(X,Y)
- 条件概率 P ( X = x ∣ Y = c k ) P(X=x|Y=c_k) P(X=x∣Y=ck)有指数级数量的参数,
- 其估计实际是不可行的
- 设 x ( j ) x^{(j)} x(j)可取值有 S j S_j Sj个, j = 1 , 2 , . . . , n j=1,2,...,n j=1,2,...,n,
- Y Y Y可取 K K K个,
- 那么参数个数 K ∏ j = 1 n S j K\prod_{j=1}^n S_j K∏j=1nSj
- 朴素贝叶斯法对条件概率分布作了条件独立性的假设.
- 这是个较强假设,朴素贝叶斯法由此得名
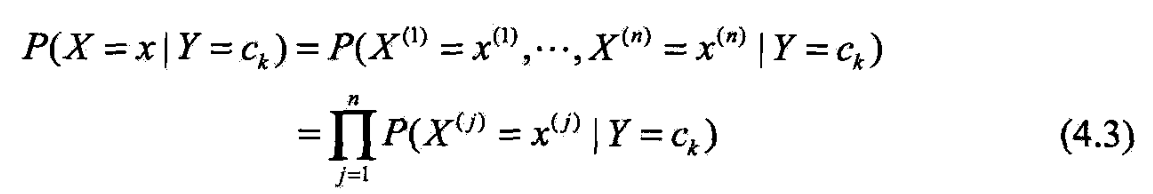
- 朴素贝叶斯法实际上学习到生成数据的机制,属生成模型.
- 条件独立假设:
- 用于分类的特征在类确定的条件下都是条件独立的.
- 这一假设使朴素贝叶斯法变得简单,但牺牲分类准确率
- 朴素贝叶斯法分类时,对输入 x x x,
- 通过学习到的模型计算后验概率分布 P ( Y = c k ∣ X = x ) P(Y=c_k|X=x) P(Y=ck∣X=x)
- 将后验概率最大的类作为 x x x的类输出
- 后验概率根据贝叶斯定理
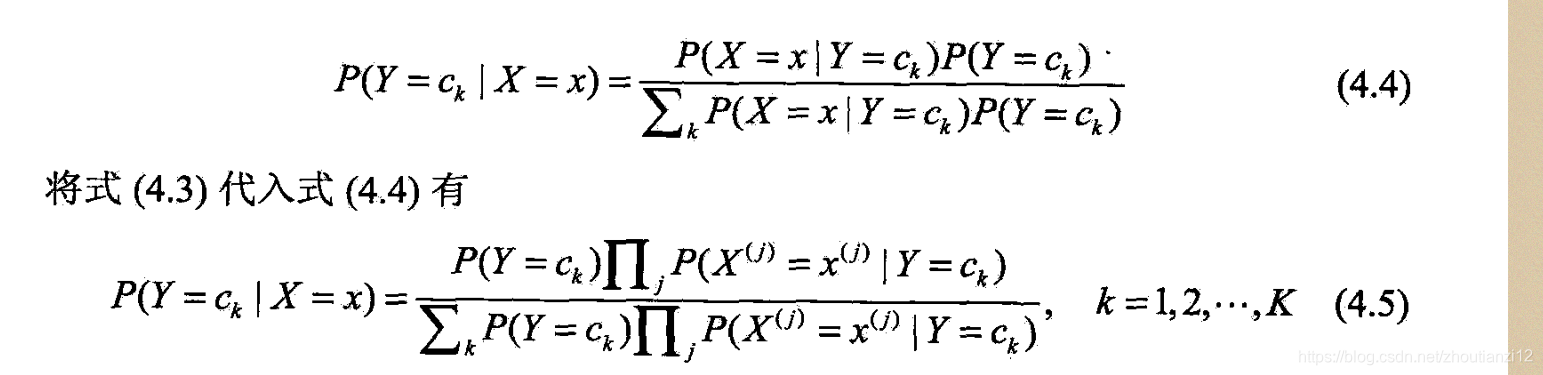
- 于是,朴素贝叶斯分类器可表示为
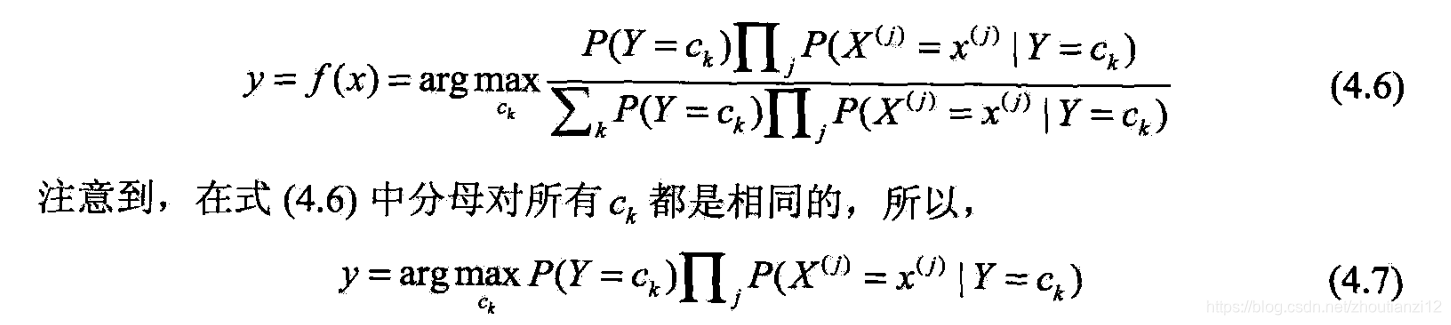
4.1.2后验概率最大化的含义
- 朴素贝叶斯法将实例分到后验概率最大的类中.
- 这等价于期望风险最小化.
- 设0-1损失函数
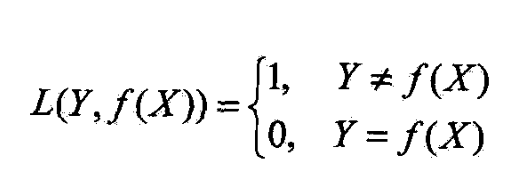
- 这时,期望风险函数为
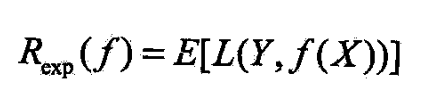
- 期望是对联合分布 P ( X , Y ) P(X,Y) P(X,Y)取的,
- 由此取条件期望
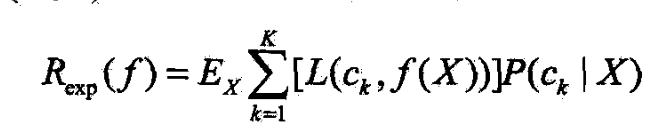
- 为使期望风险最小化,只需对 X = x X=x X=x逐个极小化,
- 由此得到:
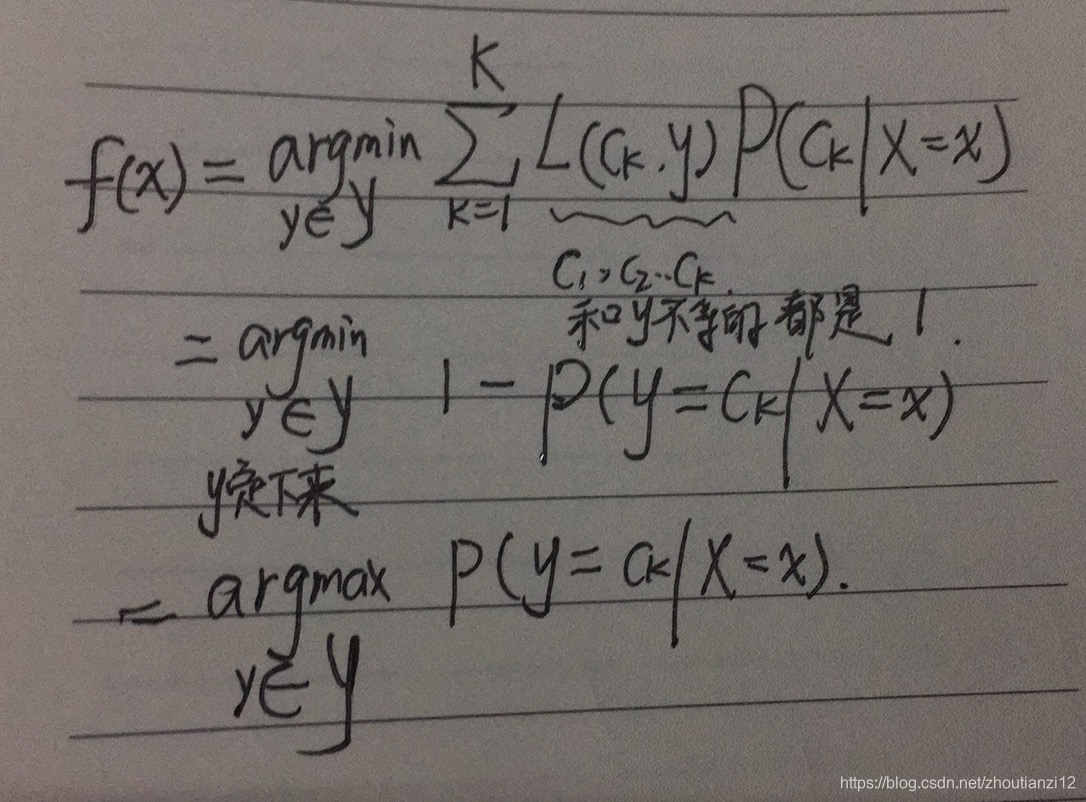
- 根据期望风险最小化准则就得到了后验概率最大化准则
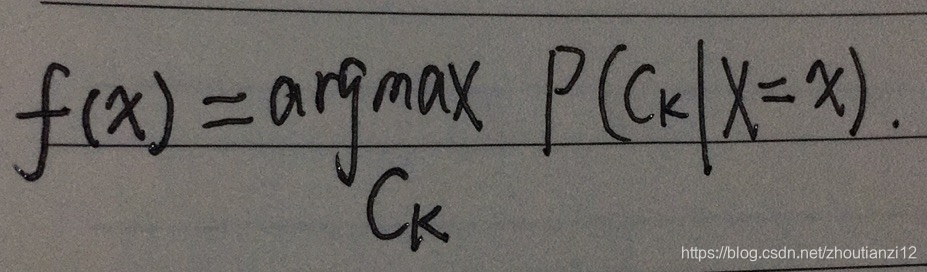
- 即朴素贝叶斯法所采用的原理
here
转载地址:https://cyj666.blog.csdn.net/article/details/104846197 如侵犯您的版权,请留言回复原文章的地址,我们会给您删除此文章,给您带来不便请您谅解!
发表评论
最新留言
网站不错 人气很旺了 加油
[***.192.178.218]2024年04月19日 15时44分50秒
关于作者

喝酒易醉,品茶养心,人生如梦,品茶悟道,何以解忧?唯有杜康!
-- 愿君每日到此一游!
推荐文章
redhat linux中设置网卡静态IP
2019-04-30
Qt时间绰的转换
2019-04-30
Qt中My SQL重用的问题
2019-04-30
数据库的导入和导出
2019-04-30
Linux下MySQL数据库常用基本操作
2019-04-30
Matlab显示多幅图像
2019-04-30
畸变校正技术
2019-04-30
Redhat无法进入登录界面,系统修复命令
2019-04-30
Linux串口加载驱动问题
2019-04-30
嵌入式Linux系统移植-使用crosstool创建自己的交叉编译器
2019-04-30
编译binutil包
2019-04-30
使用Qt作窗口截屏
2019-04-30
grep与命令混合的用法
2019-04-30
Shell编程基础
2019-04-30
linux telnet命令参数及用法详解--telnet连接远程终端命令
2019-04-30
怎样查看rpm安装包的安装路径
2019-04-30
RedHat Linux下FTP服务配置
2019-04-30
shell检查网络出现异常、僵尸进程、内存过低后机器自动重启
2019-04-30
利用shell脚本来监控linux系统的内存
2019-04-30
白红宇的个人博客 - 记录点点滴滴的事 - 您是第 310411206 位访客
访问时间: 2024-05-03 20:18:26
访问IP: 18.118.1.158
Copyright © 2020 - 2023 blog.css8.cn 京ICP备2021015314号-1
手机版