3经典算法











发布日期:2021-06-29 18:40:44
浏览次数:2
分类:技术文章
本文共 3919 字,大约阅读时间需要 13 分钟。
文章目录
- 没有最好的分类器,只有最合适的
- 传统机器学习似乎彻底被深度学习笼罩
- 深度学习是数据驱动的,失去了数据,再精密的深度网络结构也是画饼充饥
- 很多实际问题中,难得到海量且带有精确标注的数据,这时深度学习就没有大显身手,反而许多传统方法可以
1 支持向量机
场景描述
- SVM是众多监督学习方法中十分出色的
-
魔鬼在桌上放了两种颜色的球
-
魔鬼让天使用一根木棍将它们分开。
-
天使不假思索地一摆,便完成,如图3.2。
- 魔鬼又加入更多球
-
随着球增多,有的球不能再被原来的木棍正确分开,如图3.3
- SVM实际上在为天使找到木棒的最佳位置,使两边的球都离分隔它们的木棒足够远,如图3.4。
- 依照SVM为天使选择的木棒位置,魔鬼即使按刚才的方式继续 加入新球,木棒也能很好地将两类不同的球分开,如图3.5。
- 看到天使已经很好地解决了用木棒线性分球的问题,魔鬼又给了天使一个新的挑战,如图3.6。
- 按这种球的摆法,貌似没有一根木棒可以将它们完美分开。
- 但天使一拍東子,便让这些球飞到了空中,然后凭借念力抓起一张纸片,插在了两类球的中间,如图3.7
- 从魔鬼的角度看这,则像是被一条曲线完美的切开
- 如图3.8。
- 球称“数据”,木棍称“分类面”,
- 找到最大间隔的木棒位置的过程称为“优化”,
- 拍桌子让球飞到空中的念力叫“核映射”,
- 在空中分隔球的纸片称为“分类超平面”。
- 1考察SVM模型推导的基础知识;
- 2-4侧重对核函数的理解
空间上线性可分的两类,向SVM的超平面上投影,超平面上的投影仍然线性可分吗?
- 对任意线性可分的两组点,
- 它们在SVM分类的超平面上的投影都是线性不可分的。
- 不妨从二往情况讨论,再推广到高维
- SVM的分类超平面仅由支持向量決定,考虑一个只含支持向量SVM模型场景
- 用反证法
- 设存在ー个SVM分类超平面使所有支持向量在该超平面上的投影依然线性可分,如图3.11。
- 不难发现,图中AB两点连线的中垂线所组成的超平面(绿色 虚线)是相较于绿色实线超平面更优的解,这与之前假设绿色实线超平面为最优的解矛盾。
- 考虑最优解对应的绿色虚线,两组点投影后,并不线性可分
- 目前还有不严谨之处,即我们假设了仅有支持向量的情况,会不会 在超平面的变换过程中支持向量发生改变,原先的非支持向量和支 持向量发生转化呢?
- 下面证明SVM的分类结果仅依赖于支持向量。
- 考虑SVM推导中的KKT条件要求
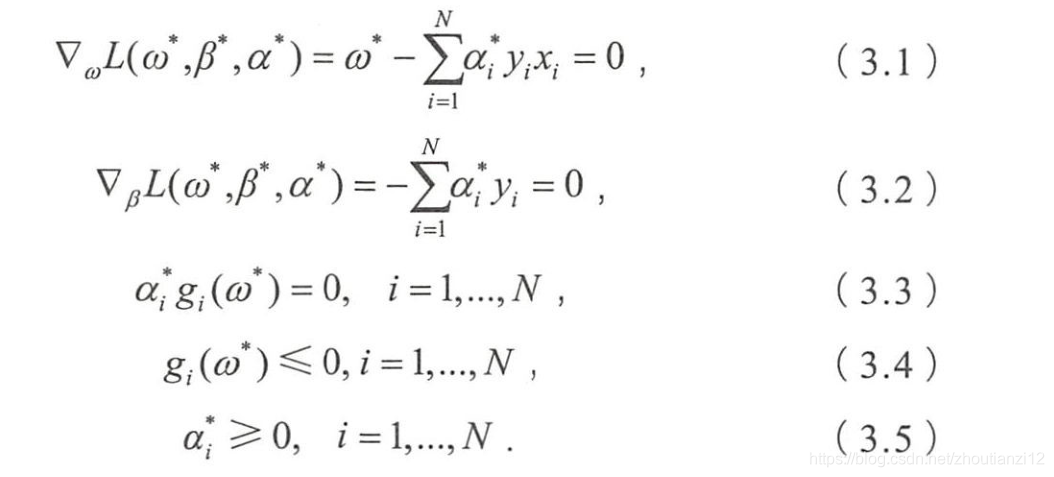
- 结合(3.3)和(3.4)
- 当 g i ( w ∗ ) < 0 g_i(w^*)<0 gi(w∗)<0时,必有 α i ∗ = 0 \alpha_i^*=0 αi∗=0,将这一结果与拉格朗日对偶优化问题的公式比较

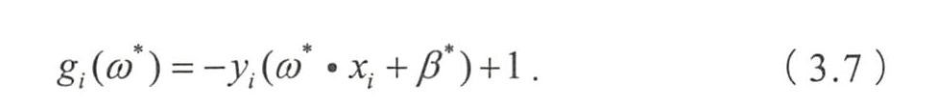
- 除支持向量外,其他系数均为0,
- 因此SVM的分类结果与仅使用支持向量的分类结果一致,
- 说明SVM的分类结果仅依赖于支持向量,
- SVM拥有极高运行效率的关键
- 于是,证明对于任意线性可分的两组点,它们在SVM分类的超平面上的投影都线性不可分
- 也可通过凸优化理论中的超平面分离定理 ( Separating Hyperplane Theorem,SHT)解決
- 对不相交的两凸集,存在一个超平面,将两个凸集分离
- 对二维情况,两凸集间距离最短两点连线的中垂线就是一个 将它们分离的超平面。
- 先对线性可分的这两组点求各自的凸包。
- SVM求得的超平面就是两个凸包上距离最短的两点连线的 中垂线,
- 也就是SHT定理二维情况中所阐释的分类超平面。
- 凸包性质易知,凸包上的点要么是样本点,要么处于两个样本点的连线上。
- 因此,两个凸包间距离最短的两个点可分三种情况:两边的点均为样本点,如图3.12(a);
- 两边的点均在样本点的连线上,如图3.12(b);
- 一边的点为样本点,另一边的点在样本点的连线上,如图3.12©。
- 无论哪种情况两类点的投影均是线性不可分的。
- 机器学习中还有很多这样看上去显而易见,细究起来却不可思议的结论。
- 面对每一个小问题,都应该从数学原理出发,细致耐心推导,对一些看似显而易见的结论抱有一颗怀疑的心
是否存在一组参数使SVM训练误差为0?
2 逻辑回归
场景描述
- 病理诊断、个人信用评估、垃圾邮件分类
相比线性回归,异同?
-
大相径庭
-
处理分类,处理回归问题
- 本质区別
-
逻辑回归中,因変量是二元分布
- 模型学习得出的是 E [ y ∣ x , θ ] E[y|x,\theta] E[y∣x,θ],
- 即给定自变量和超参数后,得因变量期望
- 并基于此期望来处理预测分类问题
-
线性回归实际求解的是 y ′ = θ T x y'=\theta^Tx y′=θTx
- 是对假设的真实关系 y = θ T x + ϵ y=\theta^Tx+\epsilon y=θTx+ϵ的近似
- ϵ \epsilon ϵ误差项,用这个近似项来处理回归问题
- 分类和回归是机器学习中两不同任务
- 属于分类算法的逻辑回归,命名有历史原因
- 最早统计学David Cox在58论文(The regression analysis of binary sequences)
- 当时人们对回归与分类的定义与今天有区别,只将“回归”这一名字沿用
- 逻辑回归可看作是对于“y=1”这一事件的对数几率的线性回归,
- 于是“逻辑回归”这一称谓也就延续下来
- 逻辑回归中,均认为 y y y是因变量,而非 p 1 − p \frac{p}{1-p} 1−pp
- 最大区别
- 因变量离散
- 线性回归中的因变量连续
- 且在自变量 x x x与超参数 θ \theta θ确定情况下
- 逻辑回归可看作(Generalized Linear Models)
- 在因变量 y y y服从二元分布时的特殊情況
- 最小乘法求解线性回归时,认为因変量 y y y服从正态分布
- 二者都用极大似然估计来对训练样本建模
- 线性回归用最小二乘法
- 实际就是在自变量 x x x与超参数 θ \theta θ确定
- 因变量 y y y服从正态分布的假设下
- 用极大似然估计的一个化简
- 实际就是在自变量 x x x与超参数 θ \theta θ确定
- 而逻辑回归中通过对似然函数
- 的学习,得到最佳 θ \theta θ
- 求解超参数的过程中,都可用梯度下降法,
- 这也是监督学习中一个常见的相似之处。
用逻辑回归处理多标签的分类问题时,有哪些常见做法,分別应用于哪些场景,它们之间有怎样关系?
- 用哪种办法处理多分类的问题取決于具体问题的定义
- 如果一样本只对应ー标签,
- 可假设每样本属于不同标签的概率服从几何分布,
- 用多项逻辑回归Softmax Regression
- 将 k k k个列向量按排列形成 n × k n\times k n×k矩阵,写作 θ \theta θ
- 表示整个参数集
- 多项逻辑回归参数冗余,即将同时加減一个向量后预测结果不变。
- 类别为2时
- 将所有参数减去O1,(3.16)变为
- 多项逻辑回归实际上是二分类逻辑回归
- 在多标签分类下的拓展
- 样本可能属多个标签时
- 训练 k k k个二分类的逻辑回归分类器
- 第 i i i个分类器区分每个样本是否可归为第 i i i类
- 训练分类器时
- 需把标签整理为“第 i i i类”与“非第 i i i类”
3决策树
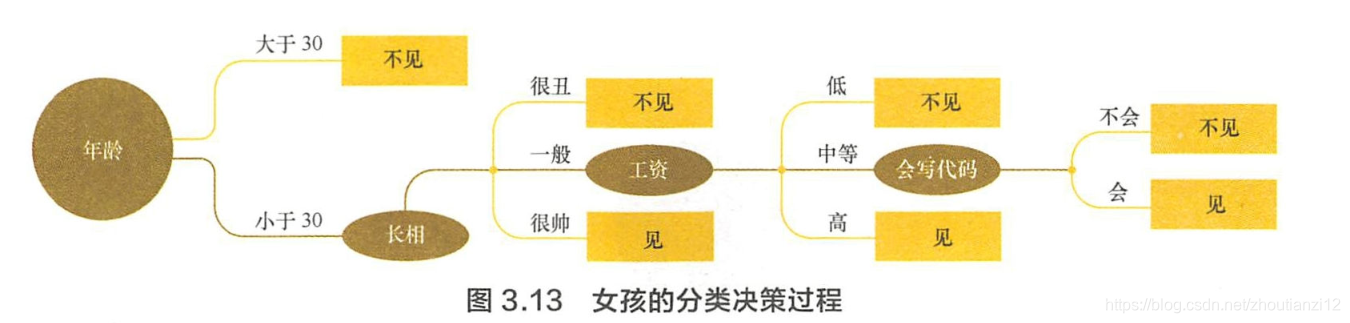
- 決策树是种自上而下,对样本数据进行树形分类
- 内部结点属性,叶结点类别
- 从顶部根结点开始,所有样本聚在一起
- 经过根结点的划分,
- 样本被分到不同的子结点中
- 再根据子结点的特征进一步划分,
- 直至所有样本都被归到某类別(叶结点)中。
-
最基础、常见的有监督
- 用于分类和回归,市场营销和生物医药领域
- 主要因为树形与销售、诊断等场景下的决策过程相似
-
将決策树应用集成学习的思想可以得到随机森林、梯度提升决策树等模型,
- 这些12章详细
-
完全生长的決策树模型具有筒单直观、解释性强的特点,
- 值得读者认真理解,
- 这也是为融会贯通集成学习相关内容所做的铺垫。
-
決策树生成含特征选择、树的构造、树的剪枝,
- 第一个问题中对几种常用的決策树对比
- 第二个问探讨决策树不同剪枝方法之间的区别与联系。
1 决策树有哪些常用的启发函数?
- 决策树的目标是从一组样本数据中,根据不同特征和属性,建立一棵树形的分类结构。
- 我们既希望它能拟合训练数据,达到良好的分类效果,
- 同时希望控制其复杂度,使得模型具有一定的泛化能力。
- 对ー个特定的问题,決策树的选择可能有很多种。比如,在场 景描述中,如果女孩把会写代码这一属性放在根结点考虑,可能只需要 很简单的一个树结构就能完成分类,如图3.14
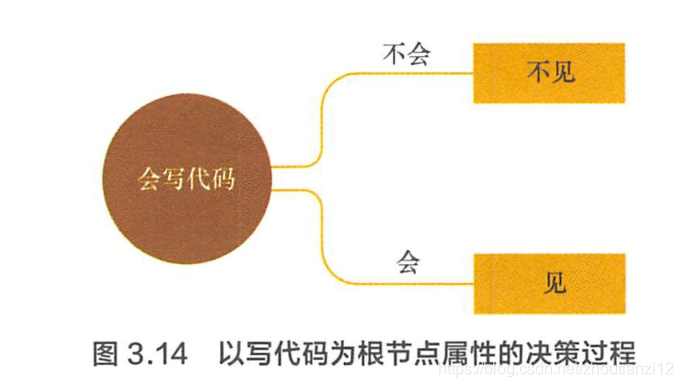
- 从若干不同的決策树中选取最优的決策树是一个NP完全,
- 实际中常用启发式学习的方法去构建一棵满足启发式条件的决策树。
- 常用決策树算法ID3、C4.5、CART,
- 它们构建树所使用的启发式函数各是什么?
- 除了构建准则之外,它们之间的区别与联系是什么?
- ID3
- 最大信息增益
- 数据集 D D D的经验熵为
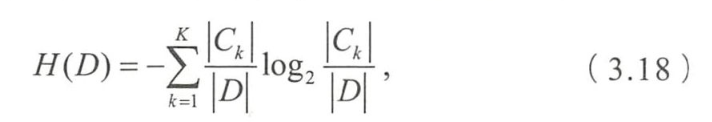
- 特征 A A A对数据集 D D D的经验条件熵
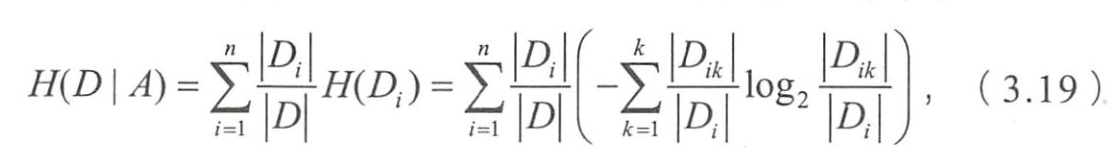
- 信息增益 g ( D , A ) g(D,A) g(D,A)表示为二者之差
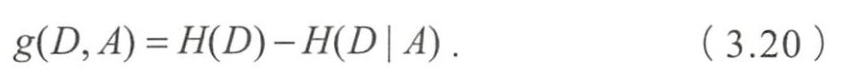
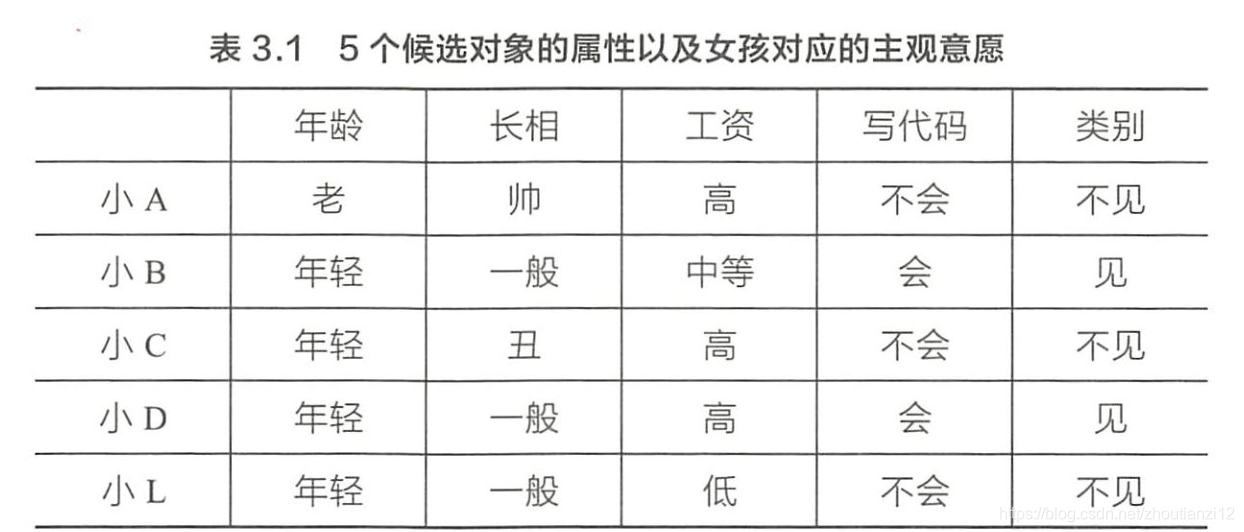

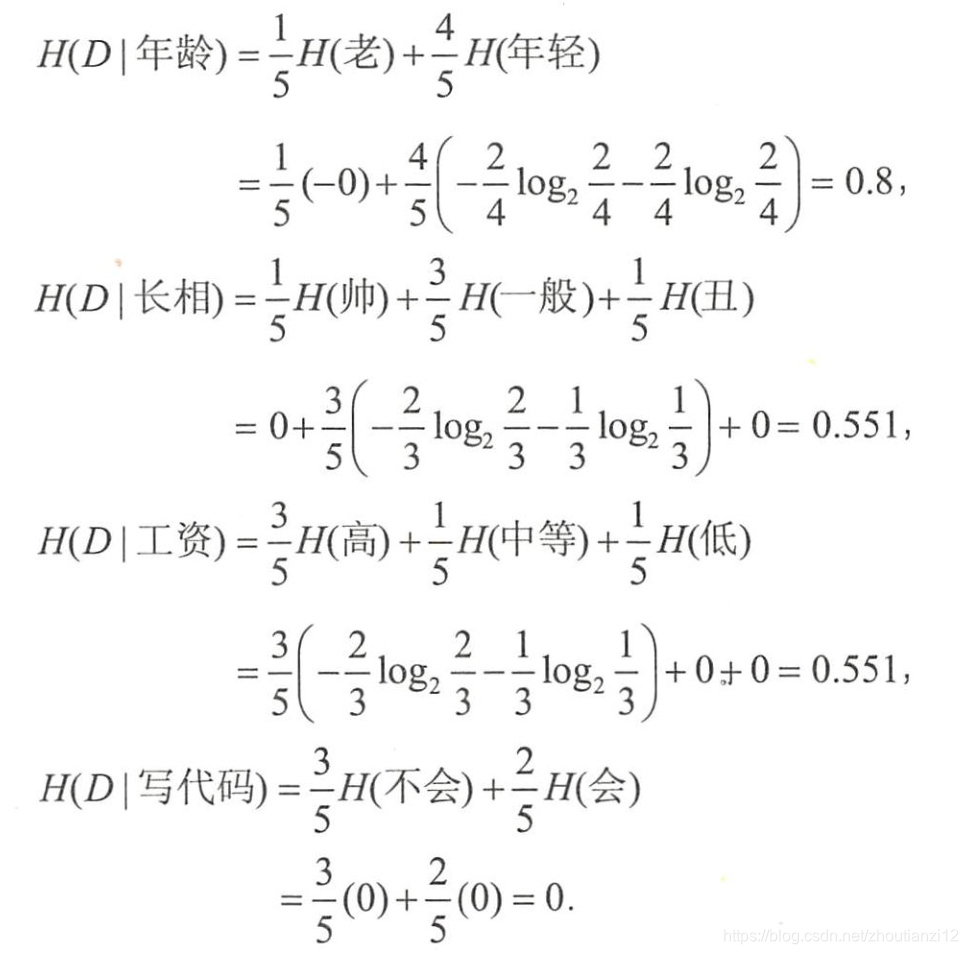
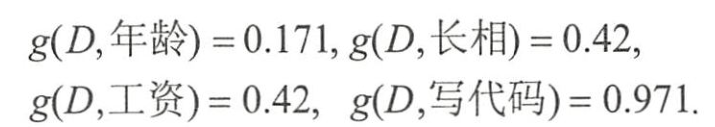
- 写代码”的信息増益最大,样本据此特征可直接被分到叶结点(即见或不见)中,完成决策树生长。
- 实际中,
- 決策树往往不能通过一个特征就完成
- 需在经验熵非0的类别中继续生长。
-
C4.5
- 最大信息增益比
-
特征A对数据集D的信息增益比
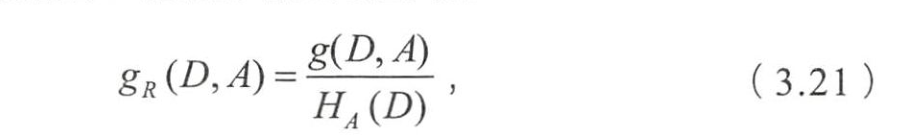
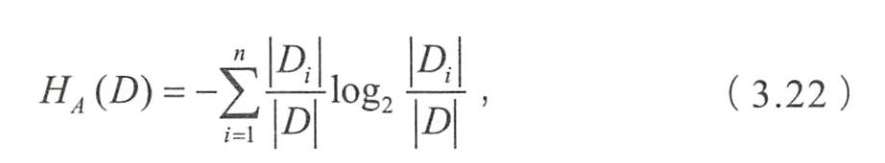
- 称为数据集 D D D关于 A A A的取值熵。
- 根据(3.22)
- 求出数据集关于每个特征的取值熵为

- 各个特征的信息増益比为
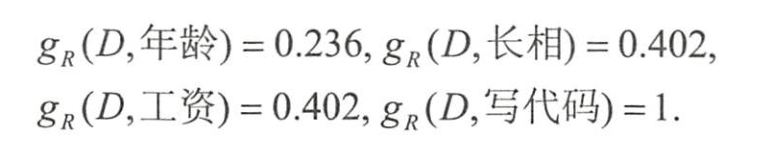
- 信息增益比最大的仍是特征“写代码”,
- 但通过信息増益比,
- “年岭”对应的指标上升了,
- “长相”和“工资”下降。
转载地址:https://cyj666.blog.csdn.net/article/details/104838595 如侵犯您的版权,请留言回复原文章的地址,我们会给您删除此文章,给您带来不便请您谅解!
发表评论
最新留言
表示我来过!
[***.240.166.169]2024年04月09日 14时06分29秒
关于作者

喝酒易醉,品茶养心,人生如梦,品茶悟道,何以解忧?唯有杜康!
-- 愿君每日到此一游!
推荐文章
C#类型转换工具类
2019-04-30
C# DataTable和List转换操作类
2021-07-03
C#xml泛型序列化
2019-04-30
C#获取客户端Ip工具类
2019-04-30
C#记录日志到本地文件工具类
2019-04-30
C#对象转换工具类
2019-04-30
C# SHA512和Base64加解密方法
2019-04-30
vs professional 2019 离线安装包下载方法
2019-04-30
sit、qas、dev、pet
2019-04-30
C# json转对象
2019-04-30
js定时器
2019-04-30
Jenkins 2017年用过
2019-04-30
aliplay获取播放时长
2019-04-30
ckplayer获取播放时长一
2019-04-30
CI/CD/Jenkins
2019-04-30
Docker
2019-04-30
网页瀑布流收集
2019-04-30
C# xml序列化 datatime字段
2019-04-30
C# LoadXml System.Xml.XmlException: Data at the root level is invalid. Line 1, position 1.
2019-04-30
jQuery.Marquee
2019-04-30
白红宇的个人博客 - 记录点点滴滴的事 - 您是第 310313745 位访客
访问时间: 2024-05-03 11:56:53
访问IP: 3.14.80.45
Copyright © 2020 - 2023 blog.css8.cn 京ICP备2021015314号-1
手机版