本文共 5906 字,大约阅读时间需要 19 分钟。
文章目录
- 没充足数据、合适特征,再强大的模型也无法满意输出
- 数据和特征决定结果上限
- 模型、算法的选择及优化则逐步接近这个上限
- 特征工程对原始数据一系列工程处理
- 将其提炼为特征,作为输入供算法和模型
- 特征工程旨在去除原始数据中的杂质和冗余
- 设计更高效特征以刻画求解的问题与预测模型之间的关系
- 本章讨论两种数据类型
- 1)结构化数据
- 可看作关系型数据库的一张表,
- 每列都有清晰定义
- 含数值型、类别型两种基本类型
- 非结构化数据。
- 文本、图像、音频、视频数据
- 无法用一个简单数值表示,也没有清晰的类别定义,
- 每条数据的大小不同
1 特征归ー化
场景描述
- 为消除数据特征间量纲影响,需对特征归一化
- 使不同指标有可比性
- 分析一个人的身高和体重对健康影响,如果用m和kg作单位
- 那么身高特征在1.6-1.8m
- 体重特征50~100kg
- 结果显然会倾向于数值差別较大的体重
- 想要更准确,就需特征(Normalization)
- 使各指标处于同一数值量级
为什么需对数值类型的特征做归ー化?
- 对数值类型的特征做归一化可以将所有的特征都统一到一个大致相 同的数值区间
- (1)Min- Max Scaling
- 对原始数据线性变换,映射到[0,1],
- 对原始数据的等比缩放

- 原来还有这个东西啊

-
(2) Z-Score Normalization
-
它将原始数据映射到均值为0、标准差为1的分布上
-
设原始均值为
- 标准差为

- 为什么要对数值型做归一化?
- 设有两种数值型特征,x1[0,10],x2[0,3],
- 构造一个目标函数符合图1.1(a)中的等值图。
- 学习速率相同时,x1更新速度>x2,需较多的迭代オ能找到最优解
- 如果x1和x2归一化到相同区间后
- 优化目标的等值图会变成圆形,
- x1和x2的更新速度一致
- 易更快通过梯度下降找到最优解

- 通过梯度下降法求解的模型通常要归一化,
- 线性回归、逻辑回归、支持向量机、神经网络
- 决策树模型不适用,以C4.5为例
- 决策树在节点分裂时主要依据数据集D关于特征x的信息增益比 (第3章第3节)
- 信息増益比跟特征是否经过归一化是无关
- 归ー化不改变样本在特征x上的信息增益
2类別型特征
场景描述
- Categorical Feature指性别(男、女)、血型(A、B、AB、O)。
- 类别型特征原始输入常是字符串,除决策树等少数模型能直接处理字符串形式的输入
- 逻辑回归、支持向量机,类别型特征必须经过处理转换成数值型特征
对数据预处理时,应怎样处理类别型特征?
- 序号编码常用于处理类別别间具有大小关系的数据
- 如成绩,分低、中、高,且“高>中>低
- 序号编码会按照大小关系对类别型特征赋予一个数值ID,
- 如高表示为3
- 中表示为2、低表示为1
- 转换后保留大小关系。
- 独热编码
- 处理类別间不具有大小关系的特征。
- 血型
- 独热编码会把血型变成一个4维稀疏向量
- A型血(1,0,0,0)
- B型血(0,1,0,0)
- 对类别取值较多的情況下用独热编码需注意
- (1)用稀疏向量来节省空间
- 在独热编码下,特征向量只有某维取值为1,其他均为0。
- 因此可利用向量的稀疏表示有效地节省空间,
- 且目前大部分的算法均接受稀疏向量形式的输入
- (2)配合特征选择来降低维度。
- K近邻中,高维空间下两点之间的距离很难得到有效衡量
- 逻辑回归中,参数数量会随着维度增高而增加,昜过拟合
- 通常只有部分维度是对分类、预测有帮助,因此可以考虑配合特征选择来降低维度
- 二进制编码分两步
- 先用序号编码给每个类别赋予一个类别ID
- 然后将类别ID对应的二进制编码作为结果
- 二进制编码本质上是利用二进制对ID哈希映射,
- 最终得到0/1特征向量,
- 维数少于独热编码,节省存储空间

- 其他编码方式
- 如Helmert Contrast、 Sum Contrast、 Polynomial ontrast、 Backward Difference Contrast
3 高维组合特征的处理
什么是组合特征?如何处理高维组合特征?
- 为提高复杂关系拟合能力
- 特征工程中会把一阶离散特征两两组合,构成高阶组合特征
- 广告点击预估为例,原始数据有语言和类型两特征
- 表1.2
- 为提高拟合能力,语言和类型可组成二阶特征
- 表1.3
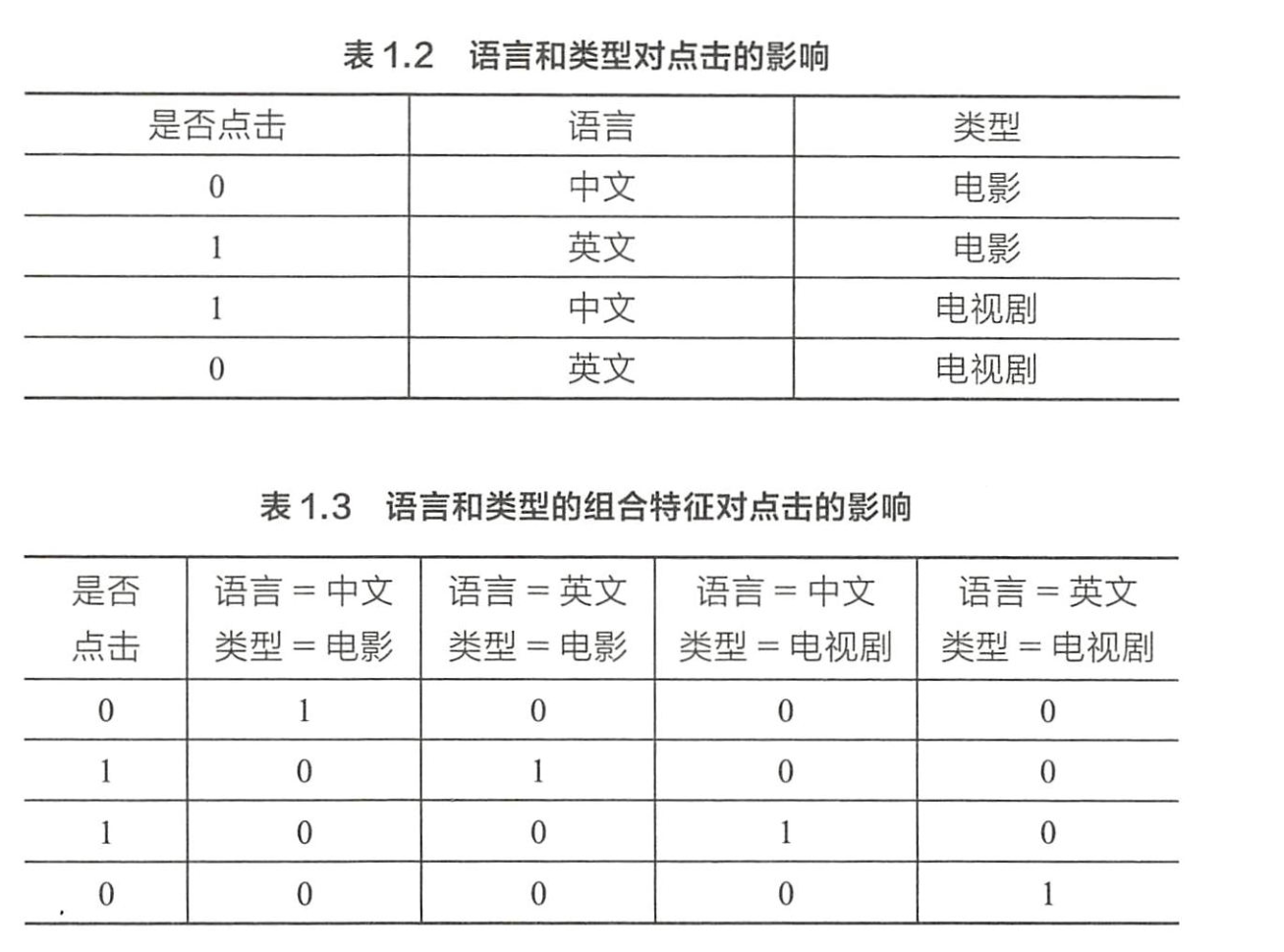
- 逻辑回归为例,特征向量为 X = ( x 1 , x 2 , ⋯ , x k ) X=(x_1,x_2,\cdots,x_k) X=(x1,x2,⋯,xk),则

每两个特征都组合成一个新的特征吧,所以 w i j w_{ij} wij是一个矩阵哦!
- < x i , x j > <x_i,x_j> <xi,xj>: x i x_i xi和 x j x_j xj的组合特征,
- w i j w_{ij} wij的维度等于 ∣ x i ∣ × ∣ x j ∣ |x_i|\times|x_j| ∣xi∣×∣xj∣
注意啊, w i j w_{ij} wij是个向量,不是矩阵啊,因为是二分类啊
- ∣ x i ∣ |x_i| ∣xi∣和 ∣ x j ∣ |x_j| ∣xj∣代表第 i i i个特征和第 j j j个特征不同取值的个数
- 表1.3中, w w w的维度是2×2=4
- 这种特征组合看起来是没有任何回题的,但当引入ID类型的特征时,问题就出现
- 表1.4是用户ID和物品ID对点击
- 表1.5是用户ID和物品ID的组合特征对点击

- 若用户数量 m m m、物品数量为 n n n,那么需要学习的参数的规模 为 m × n m×n m×n
- 无法学习
只有两个特征需要组合
- 将用户和物品分别用 k k k维的低维向量表示
- k < < m , k < < n k<<m,k<<n k<<m,k<<n
怎么将用户和物品用 k k k维的低维向量表示啊,这正是我们需要学习的,m个ID,每个ID用k维向量表示,n个物品,每个物品也用k维向量表示,所以总共要学 m × k + n × k m\times k+n\times k m×k+n×k个参数
我槽,都用k维向量表示啊??

< x i , x j > <x_i,x_j> <xi,xj>应该还是表1.5的行那样的特征啊,总共mn维,真的吗??不是的!我觉得这里没有必要搞清楚 < x i , x j > <x_i,x_j> <xi,xj>的维度到底是啥样子!他就是个表示法!表明我现在输入1个叫做 x x x的东西啦!
我觉得应该是:先设出来先各自的 k k k维表示,然后是不是有mk+nk个参数啊!然后结合训练数据对 x i ′ ⋅ x j ′ x_i'\cdot x_j' xi′⋅xj′的sigmoid函数来做预测!极大似然把这么多参数求出来!
- w i j = x i ′ ⋅ x j ′ w_{ij}=x_i'\cdot x_j' wij=xi′⋅xj′
- x i ′ , x j ′ x_i',x_j' xi′,xj′分别表示 x i x_i xi和 x j x_j xj对应的低维向量
为啥是点乘呢?如果不是点乘的话和矩阵分解就不是那么一回事了吧!
- 在表1.5的推荐问题中,要学习的参数的规模为 m × k + n × k m\times k+n\times k m×k+n×k
- 熟悉推荐算法的很快可看出来,这其实等价于矩阵分解
- 所以这里也提供另一个理解推荐系统中矩阵分解的思路。
这篇文章似乎有点懂了!
4组合特征
场景描述
- 上节如何用降维来减少两个高维特征组合后需学习的参数。
- 实际中,常面对多种高维特征
- 简单两两组合,
- 参数过多、过拟合,
- 不是所有的特征组合都有意义
- 有效方法找到应该对哪些特征组合
怎样有效地找到组合特征?
-
介绍基于决策树的特征组合寻找方法
-
原始输入特征年龄、性别、用户类型(试用期、付费)
-
物品类型(护肤、食品)
-
且根据原始输入和标签(点击/未点击)构造出决策树
-
每一条从根节点到叶节点的路径都可看成一种特征组合方式
-
4种特征组合
- “年岭<=35”且“性别=女”。
- “年龄<=35”且“物品类别=护肤”。
- “用户类型=付费”且“物品类型=食品”
- “用户类型=付费”且“年龄<=40”。

- 编码为(1,1,0,0)
- 编码为(0,0,1,1)

- 给定原始输入该如何有效地构造决策树呢?
- 可采用梯度提升决策树,思想是每次都在之前构建的決策树的残差上构建下一棵决策树。
- 对梯度提升决策树感兴趣的参12章
5文本表示模型
场景描述
- 文本是重要的非结构化数据
- 如何表示文本是机器学习重要研究方向
- 词袋模型(Bag of Words)
- TF-IDF(Term Frequency-Inverse Document Frequency)
- 主题模型(Topic Model)
- 词嵌入模型(Word Embedding)
有哪些文本表示模型?优缺点?
词袋模型和N-gram模型
- 就是将每篇文章看成一袋子词,忽略词出现的顺序
- 将整段文本以词为单位切分开,
- 然后每篇文章可表示成一个长向量,
- 向量中的每维代表一个单词,
- 该维对应的权重反映这个词在原文章中的重要程度
- 用TF-IDF来计算权重

- TF(t,d)为单词t在文档d中出现的频率
- 逆文档频率用来衡量单词 t t t对表达语义所起的重要性

- 如果一个单词在非常多的文章里面都出现,
- 那它可能是较通用的词汇,
- 对区分某篇文章特殊语义的贡献较小,因此对权重做一定惩罚
- 将连续出现的n个词(n≤N)组成的词组(N-gram)
- 也作为一个单独特征放到向量表示中去,构成N-gram模型
- 同一个词可能有多种词性变化,却有相似含义
- 实际中,一般会对单词进行词干抽取(Word Stemming)处理
- 即将不同词性的单词统一成为同一词干的形式
主题模型
- 用于从文本库中发现有代表性的主题(得到每个主题上面词的分布特性),且能够计算出每篇文章的主题分布
- 细节见第6章第5节。
词嵌入与深度学习模型
- 词嵌入是一类将词向量化的模型的统称
- 将每个词都映射成低维空间(50~300维)上的一个稠密向量
- K维空间的每一维也可看作一个隐含主题
- 不过不像主题模型中的主题那样直观
- 词嵌入将每个词映射成一个K维向量
- 一篇文档N个词,就用 N × K N\times K N×K矩阵表示这篇文档,但这样的表示过于底层
- 如果仅把这个矩阵作为原文本的表示特征输入到模型,不好
- 还需在此基础上加工出更高层特征
- 浅层机器学习模型中,好的特征工程可以带来算法效果显著提升。
- 深度学习模型为我们提供一种自动进行特征工程的方式,
- 每个隐层都可认为对应不同抽象层次的特征。
- 这个角度讲,深度学习模型能打败浅层模型也自然了
- CNN和RNN在文本表示中很好的效果
- 主要是由于它们能更好对文本建模,抽取出高层语义特征
- 与全连接的网络结构相比,CNN和RNN抓住文本的特性,又减少网络中待学习的参数,提高训练速度,降低过拟合
6 Word2Vec
场景描述
- 谷歌13年
- 最常用的词嵌入模型之一
- 浅层的神经网络模型,两种网络结构,
- CBOW( Continues Bag of Words)
- Skip-gram
Word2Vec如何工作?和LDA区别与联系?
- CBOW的: 根据上下文出现的词语来预测当前词的生成概率
- Skip-gram根据当前词来预测上下文中各词的生成概率
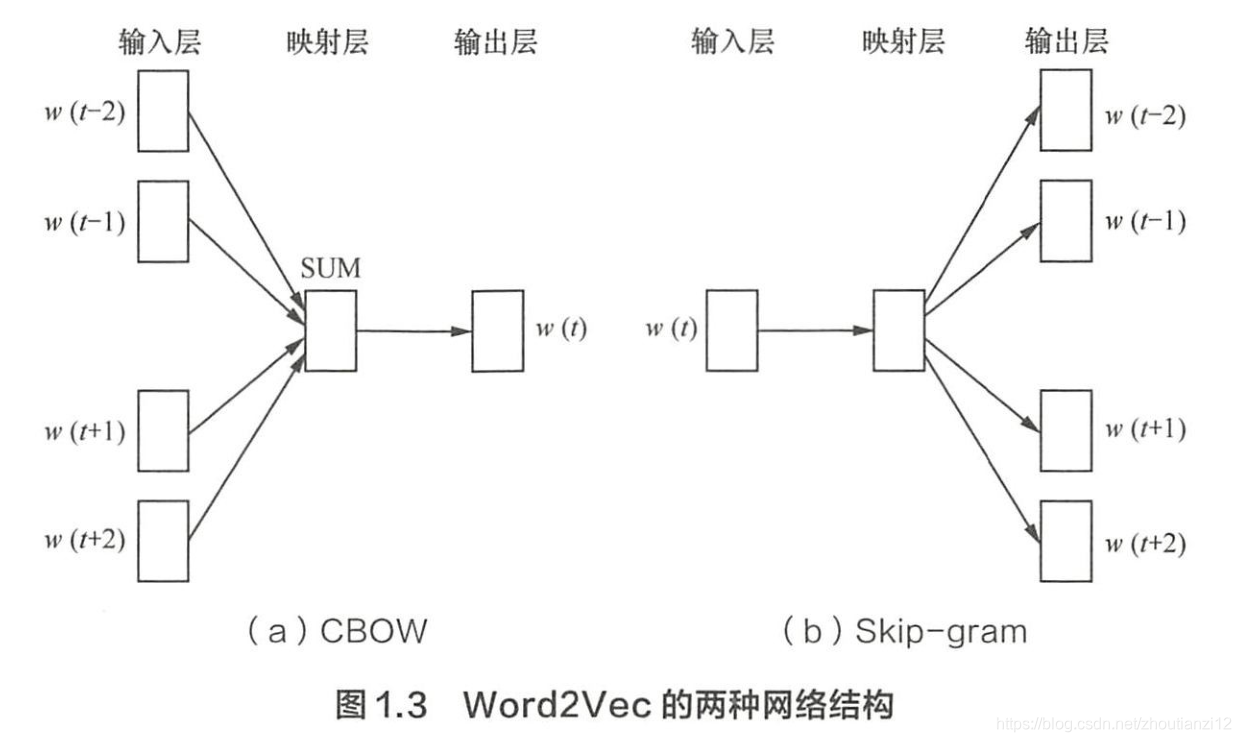
- w ( t ) w(t) w(t)是当前关注的词
- w ( t − 2 ) 、 w ( t − 1 ) 、 w ( t + 1 ) 、 w ( t + 2 ) w(t-2)、w(t-1)、w(t+1)、w(t+2) w(t−2)、w(t−1)、w(t+1)、w(t+2)是上下文中的词
- 前后滑动窗口为2
- CBOW和Skip-gram表示成
- 输入层、映射层和输出层组成的神经网络
- 输入层中每个词独热编码
- 词表示成 N N N维向量
- N N N为词汇表单词总数
- 映射层(隐含层)中, K K K个隐含单元的取值可由 N N N维输入向量及连接输入和隐含单元之间的 N × K N\times K N×K维权重矩阵计算得到
- CBOW中,还需将各个输入词所计算出的隐含单元求和
- 输出层向量的值通过隐含层向量( K K K维),及连接隐层和输出层之间的 K × N K\times N K×N矩阵计算得到
- 输出层是 N N N维向量,每维与词汇表中的一个单词对应
- 最后,对输出层向量应用Softmax
- 计算出每个单词的生成概率
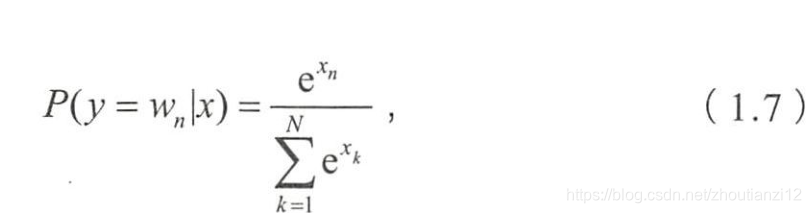
- x x x代表 N N N维的原始输出向量
- x n x_n xn为在原始输出向量中,与单词 w n w_n wn对应维度取值
- 接下来任务是训练神经网络权重
- 使语料库中所有单词整体生成概率最大化
- 输入层到隐含层需 N x K NxK NxK权重矩阵
- 隐含层到输出层又要 K x N KxN KxN权重矩阵
- 学习权重反向传播算法实现
- 每次迭代将权重沿梯度更优的方向一小步更新
- 由于Softmax中存在归一化项的缘故,推导出来的迭代公式需要对词汇表中的所有单词遍历,使每次迭代过程缓慢,由此产 Hierarchical Softmax和 Negative Sampling两种改进,可参考Word2Vec论文
- 训练得到 N × K N\times K N×K和 K × N K\times N K×N两矩阵后,可选其中一个作为 N N N个词的 K K K维向量表示
- LDA利用文档中单词的共现关系来对单词按主题緊类
- 也可理解为对“文档-单词”矩阵分解
- 得到“文档-主题”和“主题-单词”两概率分布
- Word2vec其实是对“上下文-单词”矩阵学习,上下文由周围几个单词组成,由此得到的词向量表示更多地融入了上下文共现的特征。
- 如果两个单词所对应的Word2vec向量相似度较高,那么它们很可能经常在同样的上下文中出现
- 上述是LDA与Word2vec的不同,不应该作为主题模型和词嵌入两类方法的差异。
- 主题模型通过一定结构调整可基于“上下文-单词”矩阵进行主题推理。
- 词嵌入方法也可根据“文档-单词”矩阵学习出词的隐含向量表示。
- 主题模型和词嵌入两类方法最大的不同其实在于模型本身,
- 主题模型是一种基于概率图模型的生成式模型,其似然函数可以写成若干条件概率连乘,其中包括需要推测的隐含变量(即主题);
- 词嵌入模型一般表达为神经网络,似然函数定义在网络的输出之上,需要通过学习网络的权重以得到单词的稠密向量表示。
7 图像数据不足时的处理方法
转载地址:https://cyj666.blog.csdn.net/article/details/104826995 如侵犯您的版权,请留言回复原文章的地址,我们会给您删除此文章,给您带来不便请您谅解!
发表评论
最新留言
关于作者
