本文共 15747 字,大约阅读时间需要 52 分钟。
我们再次回到了parse_network_cfg函数
//parse_network_cfg else if(lt == ACTIVE){ l = parse_activation(options, params); } 接着看后面这个parse_activation函数
#0x01 parse_activation
layer parse_activation(list *options, size_params params){ char *activation_s = option_find_str(options, "activation", "linear"); ACTIVATION activation = get_activation(activation_s); layer l = make_activation_layer(params.batch, params.inputs, activation); l.out_h = params.h; l.out_w = params.w; l.out_c = params.c; l.h = params.h; l.w = params.w; l.c = params.c; return l;} 上面的一些参数我在之前的文章中已经说过了,这里就不再说明了。直接看关键函数make_activation_layer
layer make_activation_layer(int batch, int inputs, ACTIVATION activation){ ... l.forward = forward_activation_layer; l.backward = backward_activation_layer;... return l;} 前面的参数信息我这里也不再提了,直接看关键的两个函数,先看第一个forward_activation_layer
0x0101 forward_activation_layer
void forward_activation_layer(layer l, network net){ copy_cpu(l.outputs*l.batch, net.input, 1, l.output, 1); activate_array(l.output, l.outputs*l.batch, l.activation);} 貌似这里没什么好说的b( ̄▽ ̄)d
0x0102 backward_activation_layer
void backward_activation_layer(layer l, network net){ gradient_array(l.output, l.outputs*l.batch, l.activation, l.delta); copy_cpu(l.outputs*l.batch, l.delta, 1, net.delta, 1);} 貌似这里也没什么好说的d( •̀ ω •́ )y
回到parse_network_cfg函数
//parse_network_cfg else if(lt == RNN){ l = parse_rnn(options, params); } #0x02 parse_rnn
layer parse_rnn(list *options, size_params params){ int output = option_find_int(options, "output",1); int hidden = option_find_int(options, "hidden",1); char *activation_s = option_find_str(options, "activation", "logistic"); ACTIVATION activation = get_activation(activation_s); int batch_normalize = option_find_int_quiet(options, "batch_normalize", 0); int logistic = option_find_int_quiet(options, "logistic", 0); layer l = make_rnn_layer(params.batch, params.inputs, hidden, output, params.time_steps, activation, batch_normalize, logistic); l.shortcut = option_find_int_quiet(options, "shortcut", 0); return l;} 我先说说这里的几个参数的含义,因为我之前有的没有讲过。
hidden:RNN隐藏层的元素个数time_steps:RNN的步长logistic:Logistic激活函数
接着我们来看关键函数make_rnn_layer
0x02 make_rnn_layer
作者这里使用的是vanilla RNN结构,有三个全连接层组成。
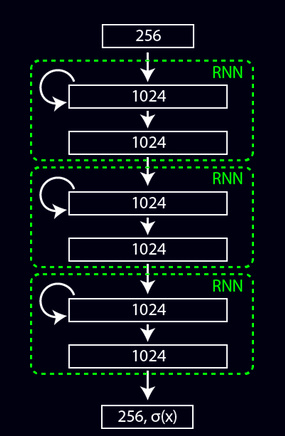
layer make_rnn_layer(int batch, int inputs, int outputs, int steps, ACTIVATION activation, int batch_normalize, int adam){ ... l.input_layer = malloc(sizeof(layer));//隐藏层1 fprintf(stderr, "\t\t"); *(l.input_layer) = make_connected_layer(batch*steps, inputs, outputs, activation, batch_normalize, adam); l.input_layer->batch = batch; l.self_layer = malloc(sizeof(layer));//隐藏层2 fprintf(stderr, "\t\t"); *(l.self_layer) = make_connected_layer(batch*steps, outputs, outputs, activation, batch_normalize, adam); l.self_layer->batch = batch; l.output_layer = malloc(sizeof(layer));//隐藏层3 fprintf(stderr, "\t\t"); *(l.output_layer) = make_connected_layer(batch*steps, outputs, outputs, activation, batch_normalize, adam); l.output_layer->batch = batch; l.outputs = outputs; l.output = l.output_layer->output; l.delta = l.output_layer->delta; l.forward = forward_rnn_layer; l.backward = backward_rnn_layer; l.update = update_rnn_layer;... 我们看这里的make_connected_layer函数
0x0201 make_connected_layer
layer make_connected_layer(int batch, int inputs, int outputs, ACTIVATION activation, int batch_normalize, int adam){ ... l.forward = forward_connected_layer; l.backward = backward_connected_layer; l.update = update_connected_layer; ...} 这里的参数信息也没什么好说的,直接看函数吧
0x020101 forward_connected_layer
void forward_connected_layer(layer l, network net){ fill_cpu(l.outputs*l.batch, 0, l.output, 1); int m = l.batch; int k = l.inputs; int n = l.outputs; float *a = net.input; float *b = l.weights; float *c = l.output; gemm(0,1,m,n,k,1,a,k,b,k,1,c,n); if(l.batch_normalize){ forward_batchnorm_layer(l, net); } else { add_bias(l.output, l.biases, l.batch, l.outputs, 1); } activate_array(l.output, l.outputs*l.batch, l.activation);} 这个函数其实没什么好说的,要注意的地方就是这里的b是转置的。还有一个地方要注意的是,这里没有了groups和batch,这也非常好理解。
0x020102 backward_connected_layer
void backward_connected_layer(layer l, network net){ gradient_array(l.output, l.outputs*l.batch, l.activation, l.delta); if(l.batch_normalize){ backward_batchnorm_layer(l, net); } else { backward_bias(l.bias_updates, l.delta, l.batch, l.outputs, 1); } int m = l.outputs; int k = l.batch; int n = l.inputs; float *a = l.delta; float *b = net.input; float *c = l.weight_updates; gemm(1,0,m,n,k,1,a,m,b,n,1,c,n); m = l.batch; k = l.outputs; n = l.inputs; a = l.delta; b = l.weights; c = net.delta; if(c) gemm(0,0,m,n,k,1,a,k,b,n,1,c,n);} 没什么好说的
0x020103 update_connected_layer
void update_connected_layer(layer l, update_args a){ float learning_rate = a.learning_rate*l.learning_rate_scale; float momentum = a.momentum; float decay = a.decay; int batch = a.batch; axpy_cpu(l.outputs, learning_rate/batch, l.bias_updates, 1, l.biases, 1); scal_cpu(l.outputs, momentum, l.bias_updates, 1); if(l.batch_normalize){ axpy_cpu(l.outputs, learning_rate/batch, l.scale_updates, 1, l.scales, 1); scal_cpu(l.outputs, momentum, l.scale_updates, 1); } axpy_cpu(l.inputs*l.outputs, -decay*batch, l.weights, 1, l.weight_updates, 1); axpy_cpu(l.inputs*l.outputs, learning_rate/batch, l.weight_updates, 1, l.weights, 1); scal_cpu(l.inputs*l.outputs, momentum, l.weight_updates, 1);} 没什么说的( ̄▽ ̄)"
0x0202 forward_rnn_layer
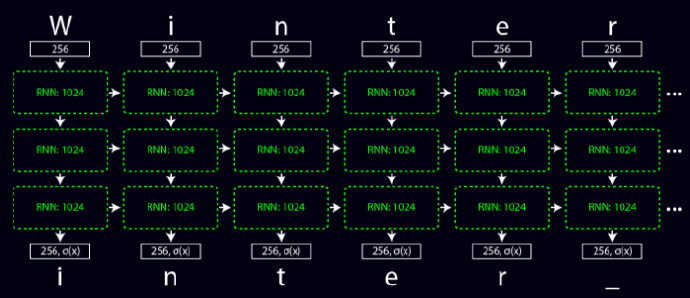
void forward_rnn_layer(layer l, network net){ network s = net; s.train = net.train; int i; layer input_layer = *(l.input_layer); layer self_layer = *(l.self_layer); layer output_layer = *(l.output_layer); fill_cpu(l.outputs * l.batch * l.steps, 0, output_layer.delta, 1); fill_cpu(l.outputs * l.batch * l.steps, 0, self_layer.delta, 1); fill_cpu(l.outputs * l.batch * l.steps, 0, input_layer.delta, 1); if(net.train) fill_cpu(l.outputs * l.batch, 0, l.state, 1);//如果网络是训练状态的话,将state设置为0 for (i = 0; i < l.steps; ++i) { s.input = net.input; forward_connected_layer(input_layer, s); s.input = l.state; forward_connected_layer(self_layer, s); float *old_state = l.state;//存储当前状态 if(net.train) l.state += l.outputs*l.batch; if(l.shortcut){ //是否添加shortcut连接 copy_cpu(l.outputs * l.batch, old_state, 1, l.state, 1); }else{ fill_cpu(l.outputs * l.batch, 0, l.state, 1); } axpy_cpu(l.outputs * l.batch, 1, input_layer.output, 1, l.state, 1); axpy_cpu(l.outputs * l.batch, 1, self_layer.output, 1, l.state, 1); s.input = l.state; forward_connected_layer(output_layer, s); //结束后,三个层都向前移动一步 net.input += l.inputs*l.batch; increment_layer(&input_layer, 1); increment_layer(&self_layer, 1); increment_layer(&output_layer, 1); }} 先说说这个函数吧increment_layer
static void increment_layer(layer *l, int steps){ int num = l->outputs*l->batch*steps; l->output += num; l->delta += num; l->x += num; l->x_norm += num;#ifdef GPU l->output_gpu += num; l->delta_gpu += num; l->x_gpu += num; l->x_norm_gpu += num;#endif} 这个函数的作用就是rnn向前的过程中,调整参数的初始位置。
这个RNN网络主要前向传播time_steps次。网络总共分为三层,第一层将输入数据编码(one-hot),是一个256的向量。第二层主要是传入上一次的状态和前一层的输出。第二层主要是传入上一次的状态和前一层的输出,并且输出结果转化为一个256维的向量,并且进行归一化处理。
0x0203 backward_rnn_layer
void backward_rnn_layer(layer l, network net){ network s = net; s.train = net.train; int i; layer input_layer = *(l.input_layer); layer self_layer = *(l.self_layer); layer output_layer = *(l.output_layer); increment_layer(&input_layer, l.steps-1); increment_layer(&self_layer, l.steps-1); increment_layer(&output_layer, l.steps-1); l.state += l.outputs*l.batch*l.steps; for (i = l.steps-1; i >= 0; --i) { copy_cpu(l.outputs * l.batch, input_layer.output, 1, l.state, 1); axpy_cpu(l.outputs * l.batch, 1, self_layer.output, 1, l.state, 1); s.input = l.state; s.delta = self_layer.delta; backward_connected_layer(output_layer, s); l.state -= l.outputs*l.batch; /* if(i > 0){ copy_cpu(l.outputs * l.batch, input_layer.output - l.outputs*l.batch, 1, l.state, 1); axpy_cpu(l.outputs * l.batch, 1, self_layer.output - l.outputs*l.batch, 1, l.state, 1); }else{ fill_cpu(l.outputs * l.batch, 0, l.state, 1); } */ s.input = l.state; s.delta = self_layer.delta - l.outputs*l.batch; if (i == 0) s.delta = 0; backward_connected_layer(self_layer, s); copy_cpu(l.outputs*l.batch, self_layer.delta, 1, input_layer.delta, 1); if (i > 0 && l.shortcut) axpy_cpu(l.outputs*l.batch, 1, self_layer.delta, 1, self_layer.delta - l.outputs*l.batch, 1); s.input = net.input + i*l.inputs*l.batch; if(net.delta) s.delta = net.delta + i*l.inputs*l.batch; else s.delta = 0; backward_connected_layer(input_layer, s); //误差传回后,后退一步 increment_layer(&input_layer, -1); increment_layer(&self_layer, -1); increment_layer(&output_layer, -1); }} 没啥好说的( ̄▽ ̄)"
0x0204 update_rnn_layer
void update_rnn_layer(layer l, update_args a){ update_connected_layer(*(l.input_layer), a); update_connected_layer(*(l.self_layer), a); update_connected_layer(*(l.output_layer), a);} 更新参数信息,调用三次全连接层的更新函数
回到parse_network_cfg函数
else if(lt == GRU){ l = parse_gru(options, params); } 0x03 parse_gru
这一部分内容我本来不打算写了,因为这和YOLOv2没有一点关系,但是抱着一种学习的态度,我还是将这部分代码做一些简要地分析,如果有不对的地方,希望大家指出,互相学习。
layer parse_gru(list *options, size_params params){ int output = option_find_int(options, "output",1); int batch_normalize = option_find_int_quiet(options, "batch_normalize", 0); layer l = make_gru_layer(params.batch, params.inputs, output, params.time_steps, batch_normalize, params.net->adam); l.tanh = option_find_int_quiet(options, "tanh", 0);//tanh激活函数 return l;} 我们现在看看这个make_gru_layer函数
layer make_gru_layer(int batch, int inputs, int outputs, int steps, int batch_normalize, int adam){ ... l.uz = malloc(sizeof(layer)); fprintf(stderr, "\t\t"); *(l.uz) = make_connected_layer(batch*steps, inputs, outputs, LINEAR, batch_normalize, adam); l.uz->batch = batch; l.wz = malloc(sizeof(layer)); fprintf(stderr, "\t\t"); *(l.wz) = make_connected_layer(batch*steps, outputs, outputs, LINEAR, batch_normalize, adam); l.wz->batch = batch; l.ur = malloc(sizeof(layer)); fprintf(stderr, "\t\t"); *(l.ur) = make_connected_layer(batch*steps, inputs, outputs, LINEAR, batch_normalize, adam); l.ur->batch = batch; l.wr = malloc(sizeof(layer)); fprintf(stderr, "\t\t"); *(l.wr) = make_connected_layer(batch*steps, outputs, outputs, LINEAR, batch_normalize, adam); l.wr->batch = batch; l.uh = malloc(sizeof(layer)); fprintf(stderr, "\t\t"); *(l.uh) = make_connected_layer(batch*steps, inputs, outputs, LINEAR, batch_normalize, adam); l.uh->batch = batch; l.wh = malloc(sizeof(layer)); fprintf(stderr, "\t\t"); *(l.wh) = make_connected_layer(batch*steps, outputs, outputs, LINEAR, batch_normalize, adam); l.wh->batch = batch; l.batch_normalize = batch_normalize; l.outputs = outputs; l.output = calloc(outputs*batch*steps, sizeof(float)); l.delta = calloc(outputs*batch*steps, sizeof(float)); l.state = calloc(outputs*batch, sizeof(float)); l.prev_state = calloc(outputs*batch, sizeof(float)); l.forgot_state = calloc(outputs*batch, sizeof(float)); l.forgot_delta = calloc(outputs*batch, sizeof(float)); l.r_cpu = calloc(outputs*batch, sizeof(float)); l.z_cpu = calloc(outputs*batch, sizeof(float)); l.h_cpu = calloc(outputs*batch, sizeof(float)); l.forward = forward_gru_layer; l.backward = backward_gru_layer; l.update = update_gru_layer;...} 0x0301 forward_gru_layer
void forward_gru_layer(layer l, network net){ network s = net; s.train = net.train; int i; layer uz = *(l.uz); layer ur = *(l.ur); layer uh = *(l.uh); layer wz = *(l.wz); layer wr = *(l.wr); layer wh = *(l.wh); fill_cpu(l.outputs * l.batch * l.steps, 0, uz.delta, 1); fill_cpu(l.outputs * l.batch * l.steps, 0, ur.delta, 1); fill_cpu(l.outputs * l.batch * l.steps, 0, uh.delta, 1); fill_cpu(l.outputs * l.batch * l.steps, 0, wz.delta, 1); fill_cpu(l.outputs * l.batch * l.steps, 0, wr.delta, 1); fill_cpu(l.outputs * l.batch * l.steps, 0, wh.delta, 1); if(net.train) { fill_cpu(l.outputs * l.batch * l.steps, 0, l.delta, 1); copy_cpu(l.outputs*l.batch, l.state, 1, l.prev_state, 1); } for (i = 0; i < l.steps; ++i) { s.input = l.state; forward_connected_layer(wz, s); forward_connected_layer(wr, s); s.input = net.input; forward_connected_layer(uz, s); forward_connected_layer(ur, s); forward_connected_layer(uh, s); copy_cpu(l.outputs*l.batch, uz.output, 1, l.z_cpu, 1); axpy_cpu(l.outputs*l.batch, 1, wz.output, 1, l.z_cpu, 1); copy_cpu(l.outputs*l.batch, ur.output, 1, l.r_cpu, 1); axpy_cpu(l.outputs*l.batch, 1, wr.output, 1, l.r_cpu, 1); activate_array(l.z_cpu, l.outputs*l.batch, LOGISTIC); activate_array(l.r_cpu, l.outputs*l.batch, LOGISTIC); copy_cpu(l.outputs*l.batch, l.state, 1, l.forgot_state, 1); mul_cpu(l.outputs*l.batch, l.r_cpu, 1, l.forgot_state, 1); s.input = l.forgot_state; forward_connected_layer(wh, s); copy_cpu(l.outputs*l.batch, uh.output, 1, l.h_cpu, 1); axpy_cpu(l.outputs*l.batch, 1, wh.output, 1, l.h_cpu, 1); if(l.tanh){ activate_array(l.h_cpu, l.outputs*l.batch, TANH); } else { activate_array(l.h_cpu, l.outputs*l.batch, LOGISTIC); } weighted_sum_cpu(l.state, l.h_cpu, l.z_cpu, l.outputs*l.batch, l.output); copy_cpu(l.outputs*l.batch, l.output, 1, l.state, 1); net.input += l.inputs*l.batch; l.output += l.outputs*l.batch; increment_layer(&uz, 1); increment_layer(&ur, 1); increment_layer(&uh, 1); increment_layer(&wz, 1); increment_layer(&wr, 1); increment_layer(&wh, 1); }} -
axpy_cpu(l.outputs*l.batch, 1, wz.output, 1, l.z_cpu, 1);
对应 i z ( t ) = x t U z + s t − 1 W z i^z(t)=x_tU^z+s_{t-1}W^z iz(t)=xtUz+st−1Wz
-
axpy_cpu(l.outputs*l.batch, 1, wr.output, 1, l.r_cpu, 1);
对应 i z ( t ) = x t U z + s t − 1 W z i^z(t)=x_tU^z+s_{t-1}W^z iz(t)=xtUz+st−1Wz
-
mul_cpu(l.outputs*l.batch, l.r_cpu, 1, l.forgot_state, 1);
对应 s t − 1 ⊙ r ( t ) s_{t-1}\odot r(t) st−1⊙r(t)
-
axpy_cpu(l.outputs*l.batch, 1, wh.output, 1, l.h_cpu, 1);
对应 i h ( t ) = x t U h + ( s t − 1 ⊙ r ( t ) ) W h i^h(t)=x_tU^h+(s_{t-1}\odot r(t))W^h ih(t)=xtUh+(st−1⊙r(t))Wh
看一下weighted_sum_cpu函数的作用
void weighted_sum_cpu(float *a, float *b, float *s, int n, float *c){ int i; for(i = 0; i < n; ++i){ c[i] = s[i]*a[i] + (1-s[i])*(b ? b[i] : 0); }} -
weighted_sum_cpu(l.state, l.h_cpu, l.z_cpu, l.outputs*l.batch, l.output);
对应 ( 1 − z ) ⊙ h + z ⊙ s t − 1 (1-z)\odot h+z\odot s_{t-1} (1−z)⊙h+z⊙st−1
0x0302 update_gru_layer
void update_gru_layer(layer l, update_args a){ update_connected_layer(*(l.ur), a); update_connected_layer(*(l.uz), a); update_connected_layer(*(l.uh), a); update_connected_layer(*(l.wr), a); update_connected_layer(*(l.wz), a); update_connected_layer(*(l.wh), a);} 我现在看到的这个源码,作者还没有实现backward_gru_layer
文章全部
由于本人水平有限,文中有不对之处,希望大家指出,谢谢_!
转载地址:https://coordinate.blog.csdn.net/article/details/78911984 如侵犯您的版权,请留言回复原文章的地址,我们会给您删除此文章,给您带来不便请您谅解!
发表评论
最新留言
关于作者
