本文共 500 字,大约阅读时间需要 1 分钟。
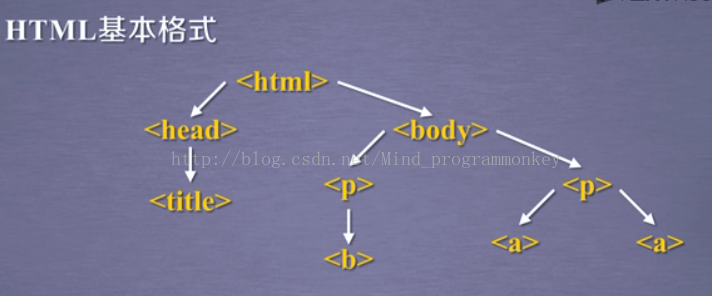
1.HTML基本格式
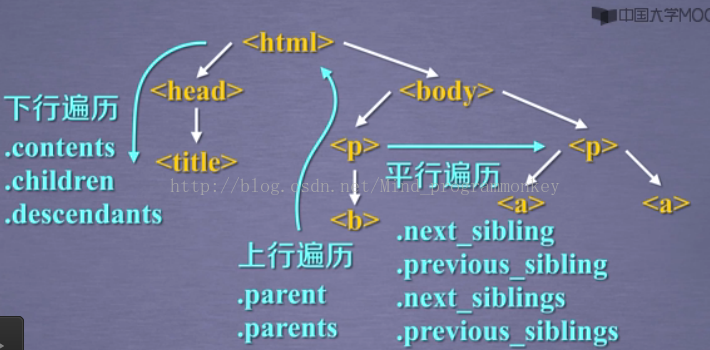
2.标签树的下行遍历
属性 说明
.contents 子节点的列表,将<tag>所有儿子节点存入列表
.children 子节点的迭代类型,与.content类似,用于循环遍历儿子节点
.descendants 子孙节点的迭代类型,包含所有子孙节点,用于循环遍历
遍历儿子节点
for child in soup.body.children:
print(child)
遍历子孙节点
for child in soup.body.descendants
print(child)
3.标签树的上行遍历
属性 说明
.parent 节点的父亲标签
.parents 节点先辈标签的迭代类型,用于循环遍历先辈节点
4.标签树的平行遍历
属性 说明
.net_sibling 返回按照HTML文本顺序的下一个平行节点标签
.previous_sibling 返回按照HTML文本顺序的上一个平行节点标签
.next_siblings 迭代类型,返回按照HTML文本顺序的后续所有平行节点标签
.previous_siblings迭代类型,返回按照HTML文本顺序的前续所有平行节点标签
转载地址:https://codingchaozhang.blog.csdn.net/article/details/76571599 如侵犯您的版权,请留言回复原文章的地址,我们会给您删除此文章,给您带来不便请您谅解!
发表评论
最新留言
关于作者
