本文共 854 字,大约阅读时间需要 2 分钟。
一、BeautifulSoup的安装
1.安装beautifu soup
以管理员权限执行cmd,然后执行pip install beautifulsoup4 命令
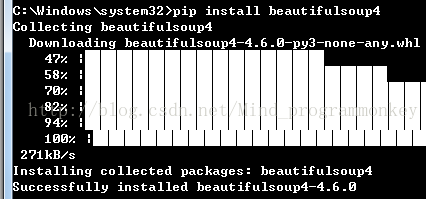
2.Beautiful Soup库的安装小测
演示HTML页面地址http://python123.io/ws/demo.html
3.BeautifulSoup库解析HTML库
from bs4 import BeautifulSoup
soup=BeautifulSoup(‘<p>data</p>,’html.parser’’)

二、BeautifulSoup库的基本元素
1.Beautiful Soup库的引用
Beautiful Soup库,也叫beautifulsoup4或bs4 如:from bs4 import BeautifulSoup
2.Beautiful Soup解析器
解析器 使用方法 条件
bs4的HTML解析器 BeautifulSoup(mk,’html.parser’) 安装bs4库
lxml的HTML解析器 BeautifulSoup(mk,’lxml’) pip install lxml
lxml的XML解析器 BeautifulSoup(mk,’xml’) pip install lxml
html5lib的解析器 BeautifulSoup(mk,’html5lib’) pip install html5lib
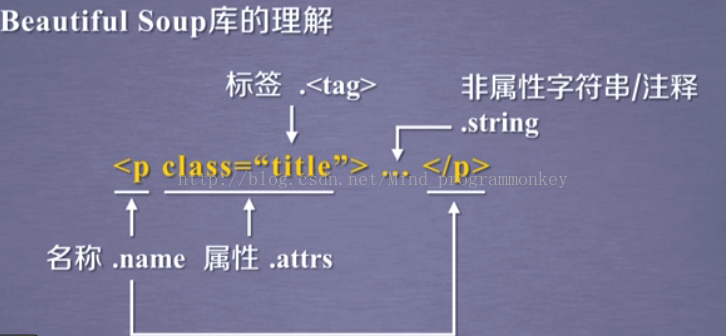
3.Beautiful Soup类的基本元素
基本元素 说明
Tag 标签,最基本的信息组织单元,分别用<>和</>标明开头和结尾
Name 标签的名字,<p>...</p>的名字是’p’,格式是:<tag>.name
Attributes 签的属性,字典形式组织,格式:<tag>.attrs
NavigableString 标签内非属性字符串,<>...</>中字符串,格式:<tag>.string
Comment 标签内字符串的注释部分,一种特殊的Comment类型
转载地址:https://codingchaozhang.blog.csdn.net/article/details/76571502 如侵犯您的版权,请留言回复原文章的地址,我们会给您删除此文章,给您带来不便请您谅解!
发表评论
最新留言
关于作者
