爬虫学习(13):爬取坑爹网gif图
发布日期:2021-06-29 14:38:55
浏览次数:3
分类:技术文章
本文共 1147 字,大约阅读时间需要 3 分钟。
昨天学完了BeautifulSoup,爬取了诗词网,今天学了PyQuery,于是我选择爬取坑爹网
学啥用啥嘛,嘿嘿!插个小曲:这是我qq群970353786,同在学习python,希望更多大神小白能跟我一起交流,我很多源代码也放到群里的,但是你进群问题回答print(“hello world”)结果是啥都回答不上还是不允许进。
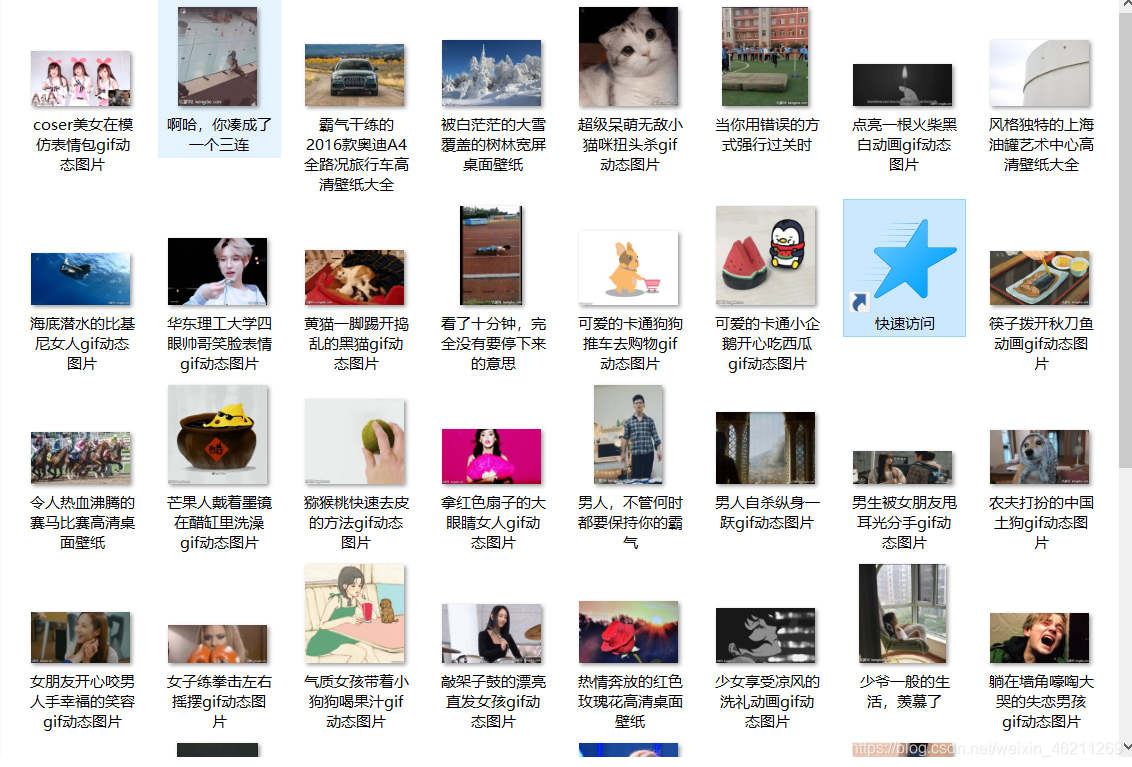
效果:(都是动态gif的) 代码:(代码仅供学习参考,如果爬取内容有所侵权请联系我删除)
import requestsfrom fake_useragent import UserAgentfrom pyquery import PyQuery as pqheaders={ 'UserAgent':UserAgent().random}url='https://kengdie.com/'#搞笑网网址html = requests.get(url=url,headers=headers).content.decode('utf-8')doc=pq(html)#初始化html字符串img=doc('.card-bg img')#获取card-bg下内容的a标签path='D://code//my python code//爬虫//image//'for item in img.items(): # print(item.attr('data-src')) title=item.attr('alt')#获取标题 title=title+'.gif' src=item.attr('data-src')#获取照片地址 src1=src.replace('mw200','large') src2=src1.replace('thumb150','large') response=requests.get(url=src2,headers=headers) with open(path+title,'wb') as f: f.write(response.content) print('下载成功:%s'%title) 我来缕一缕PyQuery与BeautifulSoup两个模块区别:
我觉得最大的区别就是BeautifulSoup返回的东西都装在一个列表,还要去单独遍历。两者都用到了CSS选择器,确实好用,当我学到这的时候,对比下之前的正则表达式,真是简单好多了。 CSS选择器的语法参考:https://www.w3school.com.cn/cssref/css_selectors.asp
如果对代码有问题,可以对我留言或者加群问我,我可以讲一下。
转载地址:https://chuanchuan.blog.csdn.net/article/details/113728894 如侵犯您的版权,请留言回复原文章的地址,我们会给您删除此文章,给您带来不便请您谅解!
发表评论
最新留言
逛到本站,mark一下
[***.202.152.39]2024年04月27日 17时23分50秒
关于作者

喝酒易醉,品茶养心,人生如梦,品茶悟道,何以解忧?唯有杜康!
-- 愿君每日到此一游!
推荐文章
-jsp-
2019-04-29
EL表达式、JSTL标签库、文件上传和下载
2019-04-29
Cookie、Session
2019-04-29
表单重复提交
2019-04-29
Filter
2019-04-29
BAT大厂最爱问的Android核心面试百题详细解析!真香
2019-04-29
BAT大厂最爱问的Android核心面试百题详细解析!面试必问
2019-04-29
BAT大厂面试基础题集合,跳槽薪资翻倍
2019-04-29
BAT常见的20道Android面试题详解,终局之战
2019-04-29
spring-boot2集成influxDB
2019-04-29
JVM Garbage Collector Summary
2019-04-29
Win10 开启 Ubuntu 及Ubuntu升级过程中的部分问题
2019-04-29
Google ProtoBuf入门(Java)
2019-04-29
net.if.in.dropped rx_missed_errors 丢包
2019-04-29
open-falcon template继承与覆盖 注意事项
2019-04-29
Docker stack task: non-zero exit (137) OOM
2019-04-29
Nginx Docker容器 获取客户端真实IP地址问题
2019-04-29
ssh-copy-id 卡住问题
2019-04-29
白红宇的个人博客 - 记录点点滴滴的事 - 您是第 310095822 位访客
访问时间: 2024-05-02 18:21:26
访问IP: 3.133.141.6
Copyright © 2020 - 2023 blog.css8.cn 京ICP备2021015314号-1
手机版