爬虫学习(12):爬取诗词名句网并且下载保存
发布日期:2021-06-29 14:38:54
浏览次数:2
分类:技术文章
本文共 1210 字,大约阅读时间需要 4 分钟。
用BeautifulSoup爬取并且下载。仅仅用作学习用途哈,不然又侵权了。
效果: 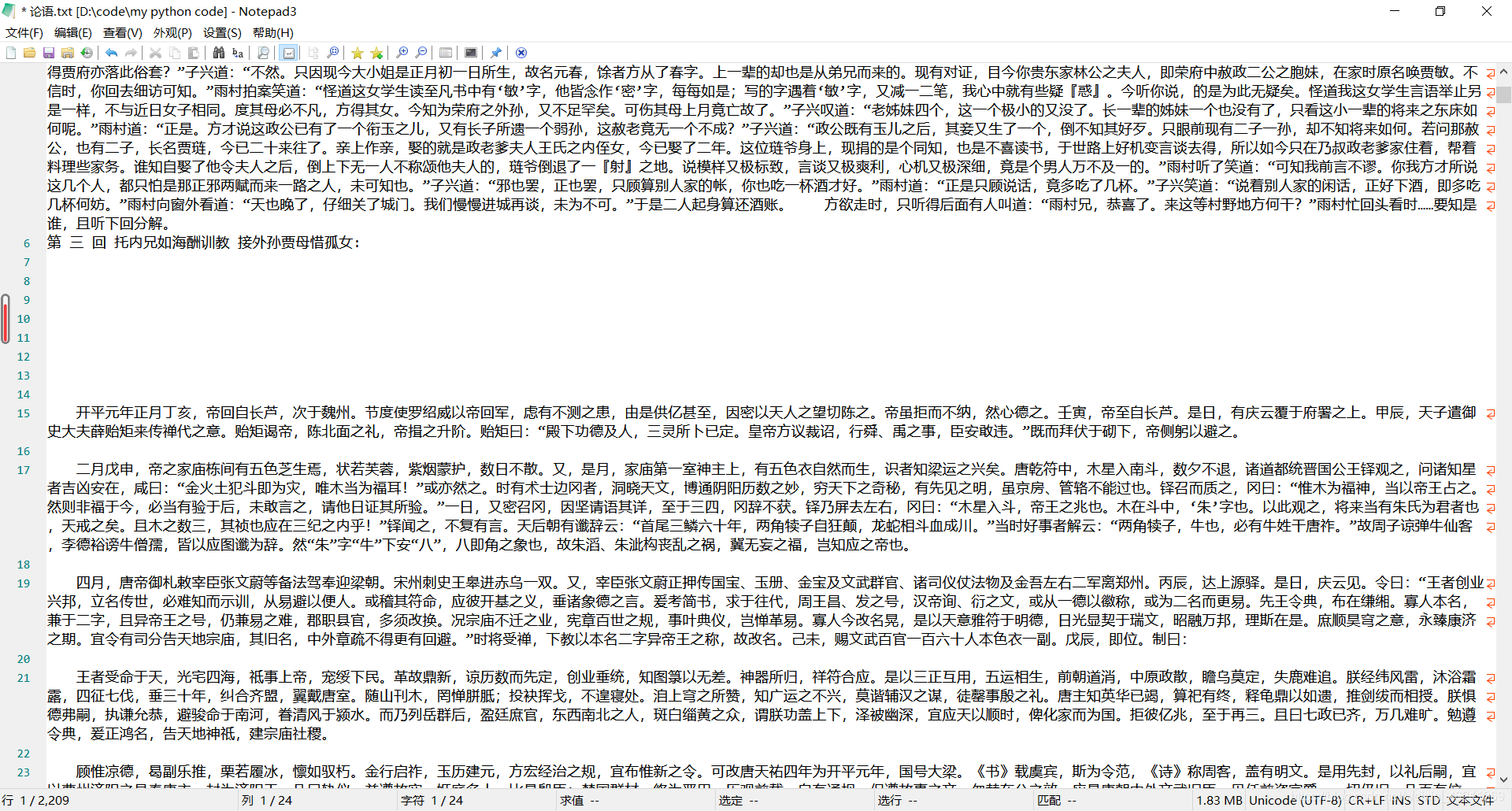
由于我是正在自学爬虫,不是很能找到非常优化的办法,是一名计算机大二学生,代码可能不是很好,还请大神指点,这是我扣扣群:970353786,希望更多喜欢学习python的可以跟我一起学习交流。
上代码:import requestsfrom bs4 import BeautifulSoupheaders = { 'User-Agent':'Mozilla/5.0 (Windows NT 10.0; Win64; x64) AppleWebKit/537.36 (KHTML, like Gecko) Chrome/86.0.4240.183 Safari/537.36 Edg/86.0.622.63'}url = 'https://www.shicimingju.com/book/hongloumeng.html'page_text = requests.get(url=url,headers=headers).content.decode('utf-8')soup = BeautifulSoup(page_text,'lxml')mulu=soup.find_all(attrs={ 'class':'book-mulu'})# mulu=soup.select('.book-mulu')# print(mulu)fp = open('./论语.txt','w',encoding='utf-8')for ul in mulu: a=ul.find_all(name='a') for i in a: title = i.string new_url = 'https://www.shicimingju.com' + i['href'] # print(new_url) # print(title) html=requests.get(url=new_url,headers=headers).content.decode('utf-8') new_soup=BeautifulSoup(html,'lxml') # print(soup) for wenben in new_soup.find_all('div',{ 'class':'chapter_content'}): print(wenben.text) c=wenben.text fp.write(title + ':' + c + '\n') print('下载成功') 有问题群里找我,或者这里留言都可以
转载地址:https://chuanchuan.blog.csdn.net/article/details/113668163 如侵犯您的版权,请留言回复原文章的地址,我们会给您删除此文章,给您带来不便请您谅解!
发表评论
最新留言
逛到本站,mark一下
[***.202.152.39]2024年04月03日 10时31分35秒
关于作者

喝酒易醉,品茶养心,人生如梦,品茶悟道,何以解忧?唯有杜康!
-- 愿君每日到此一游!
推荐文章
力扣的两数相加解法 (Python)
2019-04-29
力扣的删除链表的倒数第N个节点解法(Python)
2019-04-29
力扣的串联所有单词的子串解法(Python)
2019-04-29
力扣的接雨水解法(Python3)
2019-04-29
HTML5 五种密码框
2019-04-29
Node.js npm uuid
2019-04-29
JavaScript 滑动验证
2019-04-29
CSS3 二级菜单
2019-04-29
CSS3 帧动画(Sprite,直译叫雪碧图)
2019-04-29
JavaScript 帧动画
2019-04-29
Java NIO —— 用 Path 取代 File
2019-04-29
毕业后的五年拉开大家差距的原因在哪里?
2019-04-29
Java Callable、Future、FutureTask
2019-04-29
Java 父线程与子线程相互通信的方法
2019-04-29
Java 逃逸分析
2019-04-29
Java 装饰模式
2019-04-29
Java 观察者模式
2019-04-29
Java ReentrantLock源码解读
2019-04-29
Java CompletableFuture
2019-04-29
白红宇的个人博客 - 记录点点滴滴的事 - 您是第 309930327 位访客
访问时间: 2024-05-02 07:09:59
访问IP: 18.221.53.209
Copyright © 2020 - 2023 blog.css8.cn 京ICP备2021015314号-1
手机版