本文共 2444 字,大约阅读时间需要 8 分钟。
Flume是什么
- 收集、聚合事件流数据的分布式框架
- 通常用于log数据
- 采用ad-hoc方案,明显优点如下:
- 可靠的、可伸缩、可管理、可定制、高性能
- 声明式配置,可以动态更新配置
- 提供上下文路由功能
- 支持负载均衡和故障转移
- 功能丰富
- 完全的可扩展
- Event
- Client
- Agent
- Sources、Channels、Sinks
- 其他组件:Interceptors、Channel Selectors、Sink Processor
Event是Flume数据传输的基本单元。flume以事件的形式将数据从源头传送到最终的目的。Event由可选的hearders和载有数据的一个byte array构成。
- 载有的数据对flume是不透明的
- Headers是容纳了key-value字符串对的无序集合,key在集合内是唯一的。
- Headers可以在上下文路由中使用扩展
public interface Event { public Map getHeaders(); public void setHeaders(Map headers); public byte[] getBody(); public void setBody(byte[] body);} 核心概念:Client
Clinet是一个将原始log包装成events并且发送它们到一个或多个agent的实体。
- 例如
- Flume log4j Appender
- 可以使用Client SDK (org.apache.flume.api)定制特定的Client
- 目的是从数据源系统中解耦Flume
- 在flume的拓扑结构中不是必须的
核心概念:Agent
一个Agent包含Sources, Channels, Sinks和其他组件,它利用这些组件将events从一个节点传输到另一个节点或最终目的。
- agent是flume流的基础部分。
- flume为这些组件提供了配置、生命周期管理、监控支持。
核心概念:Source
Source负责接收events或通过特殊机制产生events,并将events批量的放到一个或多个Channels。有event驱动和轮询2种类型的Source
- 不同类型的Source:
- 和众所周知的系统集成的Sources: Syslog, Netcat
- 自动生成事件的Sources: Exec, SEQ
- 用于Agent和Agent之间通信的IPC Sources: Avro
- Source必须至少和一个channel关联
Channel位于Source和Sink之间,用于缓存进来的events,当Sink成功的将events发送到下一跳的channel或最终目的,events从Channel移除。
- 不同的Channels提供的持久化水平也是不一样的:
- Memory Channel: volatile
- File Channel: 基于WAL(预写式日志Write-Ahead Logging)实现
- JDBC Channel: 基于嵌入Database实现
- Channels支持事务
- 提供较弱的顺序保证
- 可以和任何数量的Source和Sink工作
核心概念:Sink
Sink负责将events传输到下一跳或最终目的,成功完成后将events从channel移除。
- 不同类型的Sinks:
- 存储events到最终目的的终端Sink. 比如: HDFS, HBase
- 自动消耗的Sinks. 比如: Null Sink
- 用于Agent间通信的IPC sink: Avro
- 必须作用与一个确切的channel
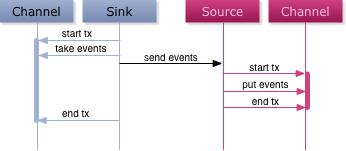
- 可靠性基于:
- Agent间事务的交换
- Flow中,Channel的持久特性
- 可用性:
- 内建的Load balancing支持
- 内建的Failover支持
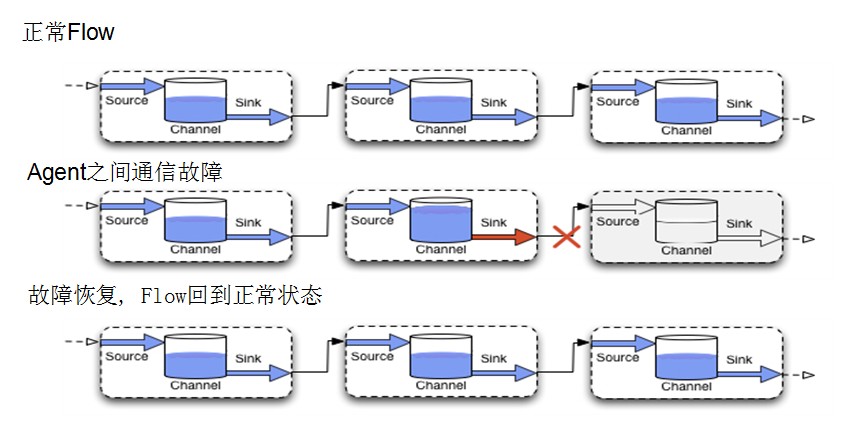
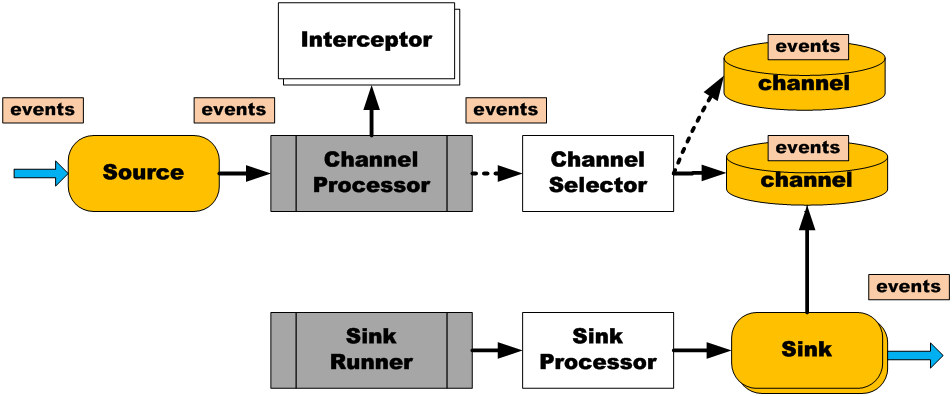
核心概念:Interceptor
用于Source的一组Interceptor,按照预设的顺序在必要地方装饰和过滤events。
- 内建的Interceptors允许增加event的headers比如:时间戳、主机名、静态标记等等
- 定制的interceptors可以通过内省event payload(读取原始日志),在必要的地方创建一个特定的headers。
Channel Selector允许Source基于预设的标准,从所有Channel中,选择一个或多个Channel
- 内建的Channel Selectors:
- 复制Replicating: event被复制到相关的channel
- 复用Multiplexing: 基于hearder,event被路由到特定的channel
多个Sink可以构成一个Sink Group。一个Sink Processor负责从一个指定的Sink Group中激活一个Sink。Sink Processor可以通过组中所有Sink实现负载均衡;也可以在一个Sink失败时转移到另一个。
- Flume通过Sink Processor实现负载均衡(Load Balancing)和故障转移(failover)
- 内建的Sink Processors:
- Load Balancing Sink Processor – 使用RANDOM, ROUND_ROBIN或定制的选择算法
- Failover Sink Processor
- Default Sink Processor(单Sink)
- 所有的Sink都是采取轮询(polling)的方式从Channel上获取events。这个动作是通过Sink Runner激活的
- Sink Processor充当Sink的一个代理
转载地址:https://blog.csdn.net/xiaochawan/article/details/8986489 如侵犯您的版权,请留言回复原文章的地址,我们会给您删除此文章,给您带来不便请您谅解!
发表评论
最新留言
关于作者
