本文共 2348 字,大约阅读时间需要 7 分钟。

文章目录
好几天没写啥实在的干货了,今天见六不废话了,直接上干货。
玩转json
什么是json
Json是一种轻量级的数据交换格式,具有数据格式简单,读写方便易懂等很多优点。用它来进行前后端的数据传输,大大的简化了服务器和客户端的开发工作量。
如果说现在对json还没有什么概念的朋友,了解了以上内容之后,再了解一下它是字典形式的即可。一切存取操作如字典。
只是前后可能做点格式转换罢了。来个例子熟悉一下:
{ "animals": { "dog": [ { "name": "Rufus", "age":15 }, { "name": "Marty", "age": null } ] }} 我们平时要去哪里找这种json格式的数据呢?网络抓包抓出来的就有很多是这样的,前面不是说了嘛。
Python中的Json模块
Python有自带的json模块,用的比较多的函数有如下:
json.dumps() 是将 python 对象转化为 json。json.loads() 是将 json 转化为 python 对象。
如果你是用谷歌浏览器来看网页源码的话,你看到的json包那是相当之凌乱的啊,这时候我建议你先暂时切换到火狐来,就会看到如下格式的图:
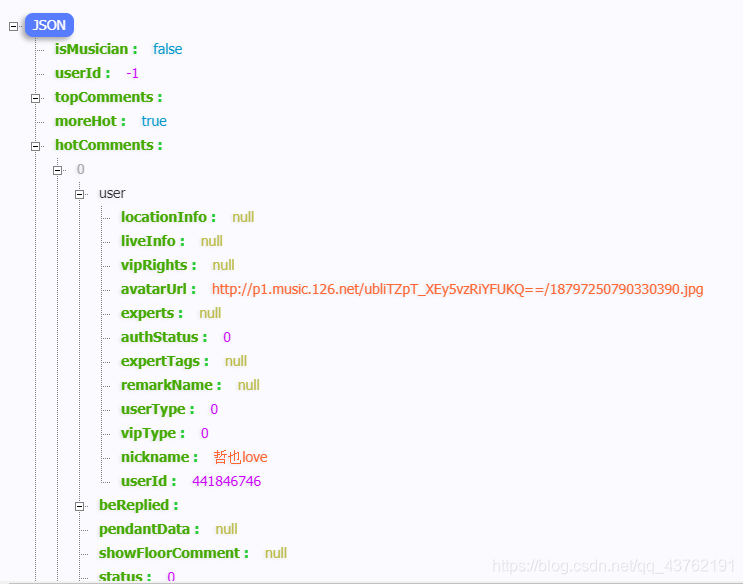
是不是会清晰很多、
获取json中的某个数据
如果我们要获取上面示例数据(test)中的某个元素,比方说,狗的名字,要如何操作呢?
dog_msg = json.loads(test)for msg in dog_msg["animals"]["dog"] print(msg["name"])
注意,在json数据里面,{} 是字典,[] 是列表。
Jpath
既然XML都有Xpath,那 json 就不配有自己的导航路径了吗?
那必须有啊,安排!!!
接下来,我们使用Jpath来获取一下所有的狗的名字:
load_data = json.loads(dump_data)data=load_data['animals']['dog']for i in data:# 从根节点开始,匹配name节点 print(jsonpath.jsonpath(i,'$..name')[0])
其中 $…name 代表从根节点开始,匹配name节点
numpy
numpy,底层运行的是C和C++的代码,但是上层使用的是python语言去写的。
考虑到不是所有小伙伴都学过C/C++,我还是简单介绍一下ndarray。

list列表中可以存储不同的数据类型。ndarray数组中存储的所有的元素的类型,都必须一致。
使用ndarray创建数组的好处
ndarray好处在于:1、由于元数据(数据类型)只需要存储一份,所以可以更节省空间。2、由于每个元素的类型一致,就证明每个元素占用内存的大小是一致的,那么这样的数据的存储可以更紧凑,操作更高效。
numpy基本操作
创建numpy对象
import numpy as np array1 = [1,2,3]m = np.array(array1)display(m)
array1 = np.arange(1,10,2)display(array1)
arange()函数的步长,可以是浮点数,但是range()函数的步长,不能是浮点数
np.zeros((x,y)):生成一个x行y列的,元素都是0的二维数组;np.ones((x,y)):生成一个x行y列的,元素都是1的二维数组;np.full((x,y),value):生成一个x行y列的,元素都是value的二维数组,其中这个value值可以是整数(正整数,0,负整数)或者小数
and so on.
我也不知道为啥写了这么一个模块,但是既然写了就放这里吧。
文本数据去重
在做情感分析的时候,有时候需要对文本进行分词,做词频统计。
以“单字词”为例,进行原理说明:
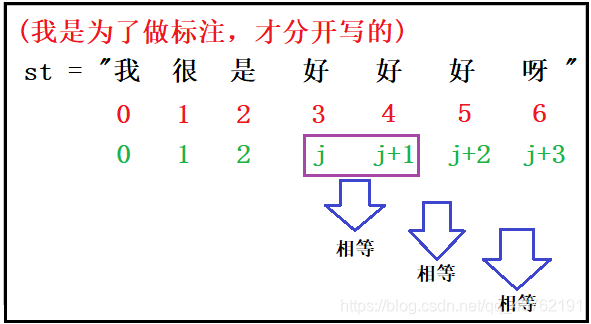
通过上图可以发现,进行词语句内去重,首先判断位置j到j+1位置的元素是否相等,如果相等,再判断j+1处的元素和j+2处的元素是否相等,这样依次进行下去。
不多说,直接上代码吧:
def func(st): for i in range(1,int(len(st)/2)+1): for j in range(len(st)): if st[j:j+i] == st[j+i:j+2*i]: k = j + i while st[k:k+i] == st[k+i:k+2*i] and k
数据采集方式
这几天都在陆陆续续的做数据采集,也感受到了采集数据的困难,所以还是有必要开这么一块儿的。
目前我所能了解到的比较好的数据采集方式如下:
1、日志,这个毋庸置疑了吧2、政府网站:如国家统计局,我们之前做时间序列分析的课设就是那里找到。此外还有:国家数据网等3、私人数据网站,如:蝉妈妈等,这个需要经验。4、咨询类公司数据报告,这个就是花钱买数据了。5、数据竞赛网站:国内外都有许多著名的数据竞赛网站,在这里聚集了大量数据分析师,甚至是数据科学家。这些网站不仅提供了大量数据,也由于专业性的比赛,也是学习数据分析的好地方。如:下方蓝字6、开放API接口,如:下方蓝字7、网络爬虫
转载地址:https://lion-wu.blog.csdn.net/article/details/115429705 如侵犯您的版权,请留言回复原文章的地址,我们会给您删除此文章,给您带来不便请您谅解!
发表评论
最新留言
关于作者
