本文共 1298 字,大约阅读时间需要 4 分钟。
思考:redis本质是要解决什么问题?
看一个场景:系统查询用户的接口中sql执行需要两秒怎么优化?
第一种优化架构:解决接口性能问题,在浏览器端加缓存
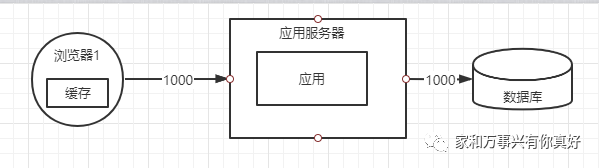
问题是:浏览器2..N都要自己建立缓存后才能使用,同时有1000新用户打开浏览器系统瘫痪(假设数据库能抗住的qps极限是1000)。
第二种架构优化 :解决缓存不能重复利用问题,使用JVM缓存
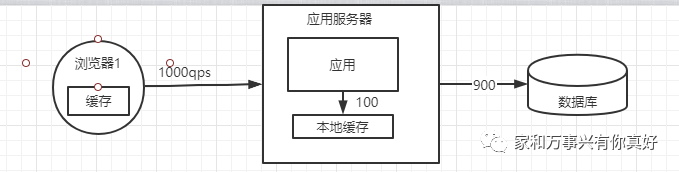
问题是:JVM需要的内存增加了,增加GC频率,不久后内存不够了。
第三种架构优化:解决内存不足GC频繁问题,用一个内存大的服务器部署单体redis(假设有500的qps命中缓存)
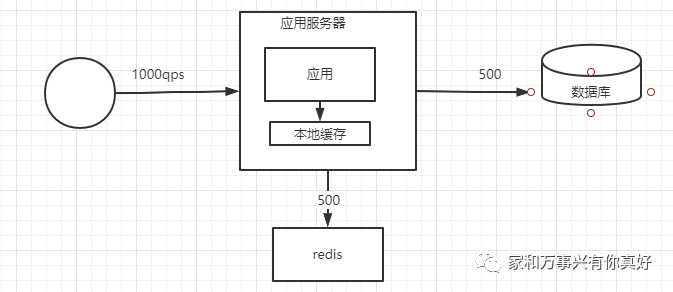
问题是:
1、一旦redis罢工导致内存中的数据全部丢失,所有的请求都到了数据库上DB被打死((假设数据库能抗住的qps极限是1000)。
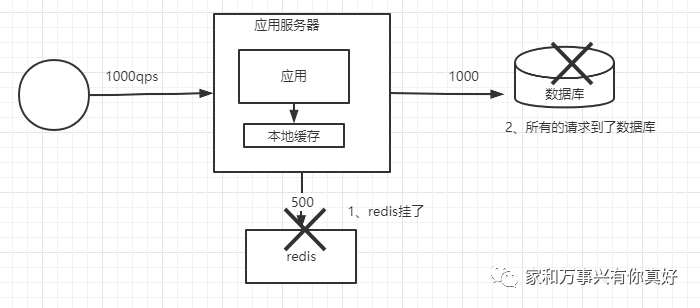
2、单台redis扛不住太高的并发,qps增加到5000假设4000都命中缓存缓存挂掉(假设单机的redis抗住的qps极限是4000)
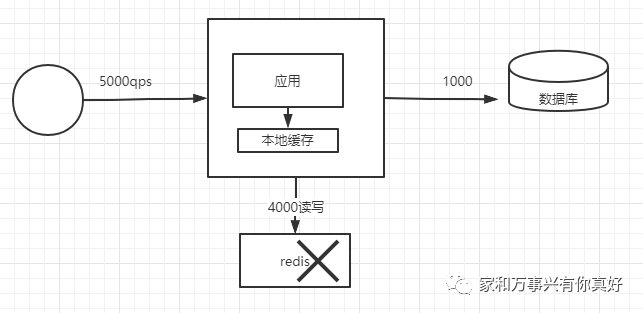
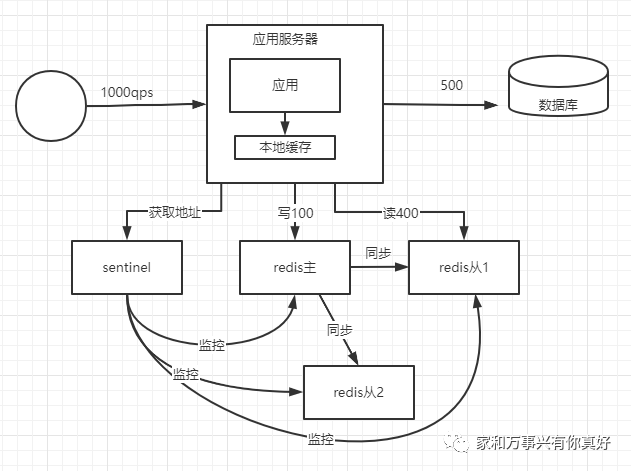
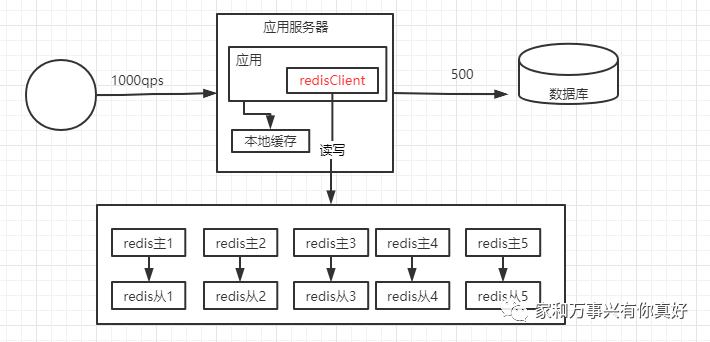
第四种架构优化:解决redis不能抗更高的并发、缓存服务故障没有热备份,使用一主多从架构
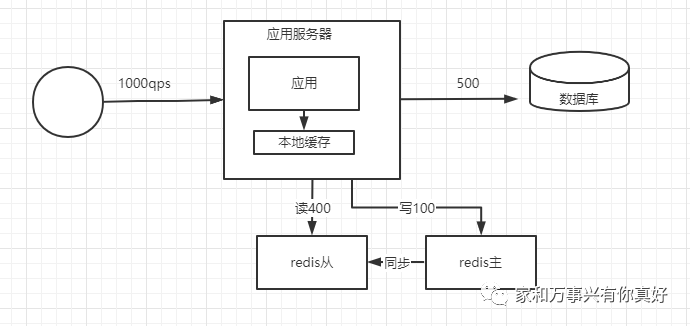
故障检测和故障转移过程:redis主挂了人工发现,手动把redis从提升为主从启挂掉的redis并设置为新主的从节点
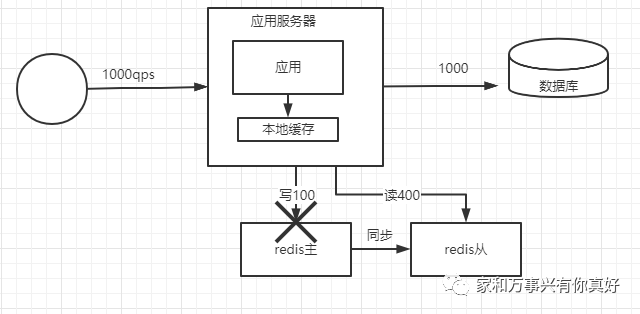
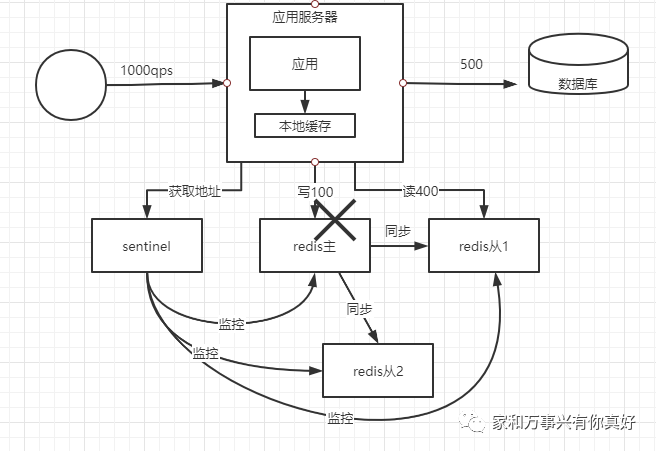
问题:故障检测只能靠人发现,故障转移需要人工操作
人工切换的问题:假设主redis在晚上23点挂了,10分钟之后你接到电话,老板让你赶紧修复,于是你从被窝爬起来整,岂不是很头疼。假如你关机了,其他人又不知道服务器密码,那系统岂不是要停机一晚上?停机一晚上如果你的业务是全球业务或者是在晚上有高峰期的业务那岂不是损失惨重!
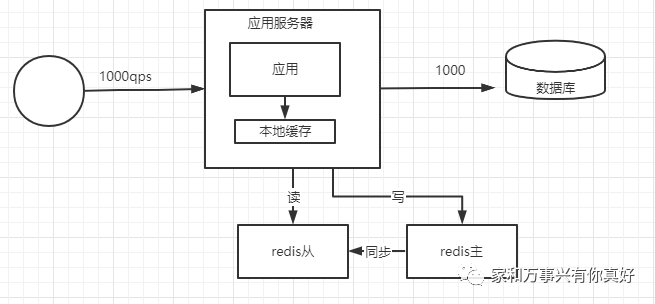
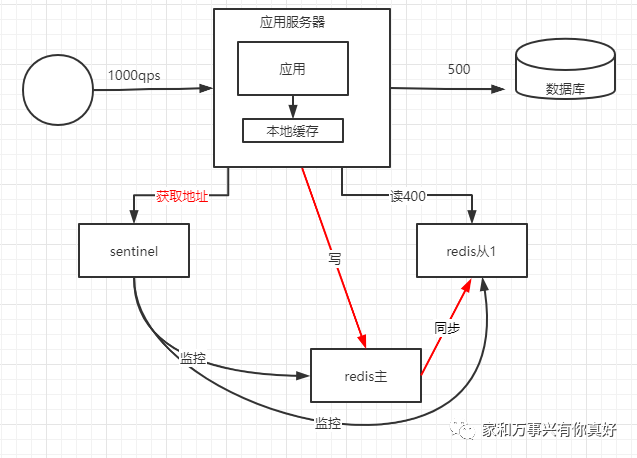
第五种架构优化:解决依靠人工检测和转移故障,使用哨兵监控状态并自动转移故障
故障检测和故障转移过程:
问题:哨兵本省就是单点他的高可用怎么保证呢?生产环境一定是用的sentinel集群
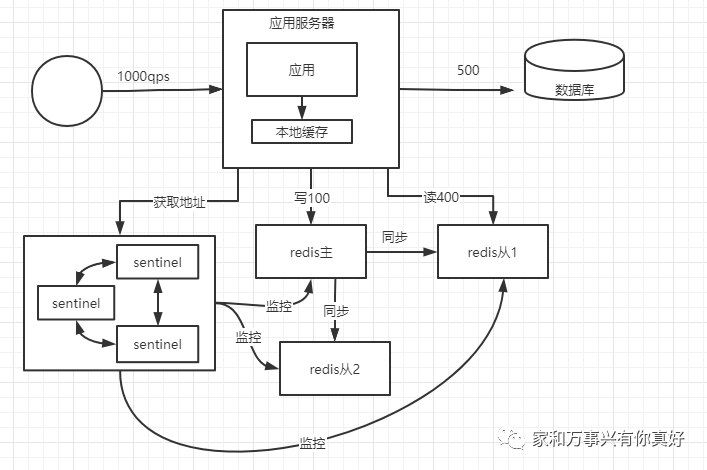
上述第五种架构解决了缓存的高可用、高并发问题。应对80%的业务完全够用。
看第二个场景:我有两台4G内存的机器但是我有5G的东西要缓存怎么解决?
第六种架构优化:解决大数据量问题,使用数据分片(sharding)、数据复制(replication)、故障转移(failover)
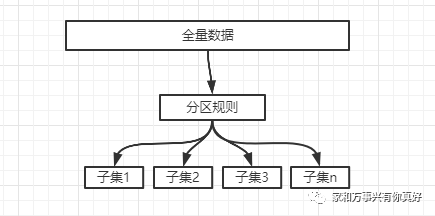
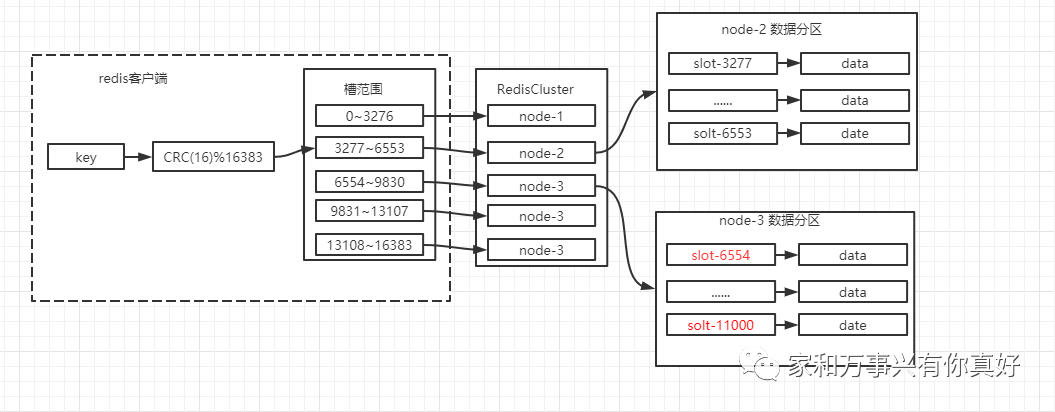
数据分片的通用逻辑如下图:
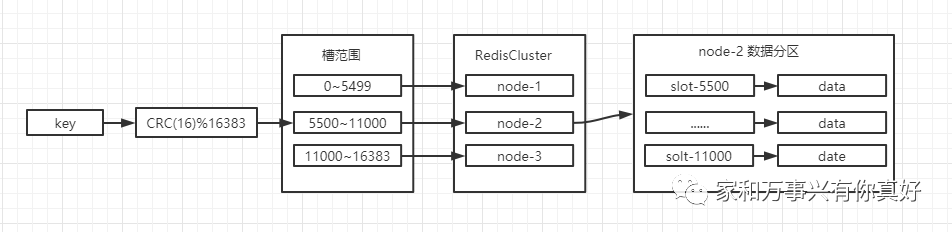
rediscluster总共有16384个slot(槽)分布在所有主接点中,每个槽存储一部分数据,根据下图的规则计算出数据所在槽
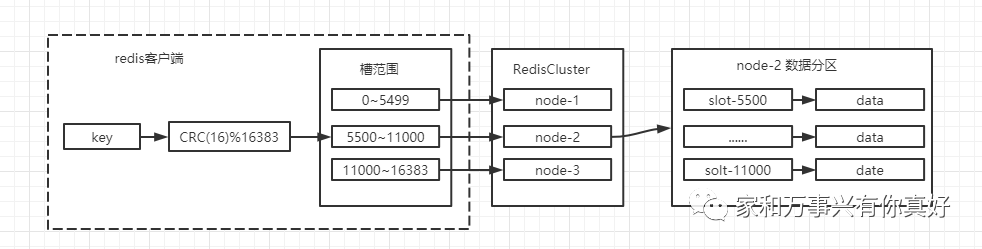
计算出数据所在槽是在客户端(JedisCluster)中完成
故障检测和故障转移过程:
1、当redis主3挂了,会自动提升redis从3作为主节点
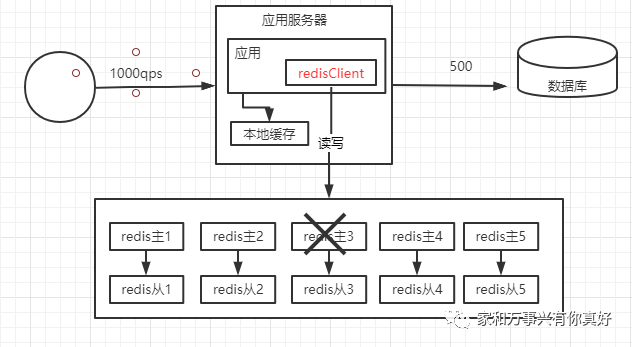
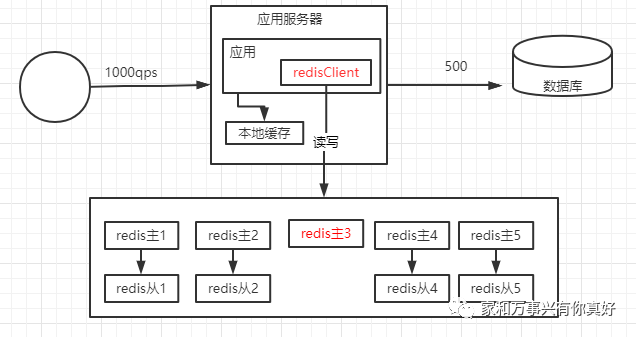
2、如果redis主4、5和redis从4、5都挂了,数据需要重新分布
分布之前的情况:
分布之后的情况:
最终的架构:
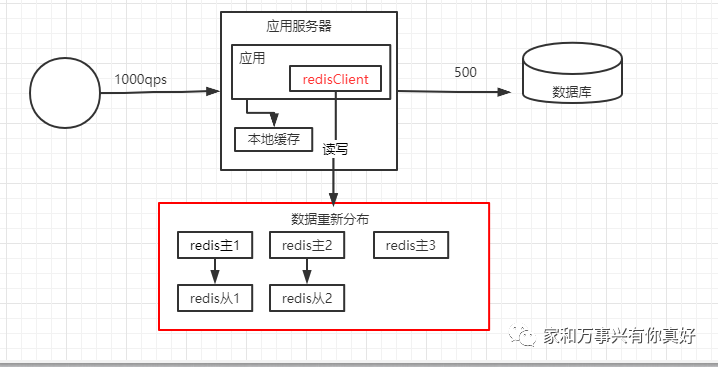
其实第六种架构就是亿级流量下的高并发高可用大数据的解决方案!!
这次分享就到这里!留个思考题:对比六种架构我们的系统合适用那种?为什么?
后续会对架构演进中的具体知识点进行探讨涉及的如下:
redis的主从复制原理是什么?
数据复制技术的及时性和一致性如何保证?
redis的持久化技术的原理是什么?
哨兵实现高可用的原理是什么?
集群模式key的寻址过程是什么?
转载地址:https://blog.csdn.net/weixin_39785600/article/details/111296459 如侵犯您的版权,请留言回复原文章的地址,我们会给您删除此文章,给您带来不便请您谅解!
发表评论
最新留言
关于作者
