本文共 11844 字,大约阅读时间需要 39 分钟。
二叉树的遍历(traversing binary tree)是指从根节点出发,按照某种次序依次访问二叉树中所有结点,使得每个结点被访问一次且仅被访问一次。
本文介绍了4种二叉树的遍历方法,分别是前序、中序、后续、层序遍历,并且每种方法均提供了详尽的Java语言的代码演示,在最后还介绍了遍历结果推导的方法。
文章目录
1 概述
二叉树的遍历(traversing binary tree)是指从根节点出发,按照某种次序依次访问二叉树中所有结点,使得每个结点被访问一次且仅被访问一次。
访问其实是要根据实际的需要来确定具体做什么,比如对每个结点进行相关计算,输出打印等,它算作是一个抽象操作。在这里我们可以简单地假定访问就是输出结点的数据信息。 二叉树的遍历次序不同于线性结构,最多也就是从头至尾、循环、双向等简单的遍历方式。树的结点之间不存在唯一的前驱和后继关系,在访问一个结点后,下一个被访问的结点面临着不同的选择。因此遍历的方式也有很多种,主要的方式有先序遍历、中序遍历、后序遍历、层序遍历。 关于二叉树的知识,如果不是很了解,可以看这篇文章:。本文将以下面的二叉树来作为样例进行遍历:

2 构建二叉树
首先,构建出上图中二叉树,下面是二叉树的简单链式存储结构的实现。二叉树的实现在:中有讲解。
/** * 二叉树的链式存储结构的简单实现 */public class LinkedBinaryTree{ /** * 外部保存根节点的引用 */ private BinaryTreeNode root; /** * 树节点的数量 */ private int size; /** * 内部节点对象 * * @param 数据类型 */ public static class BinaryTreeNode { //数据域 E data; //左子节点 BinaryTreeNode left; //右子节点 BinaryTreeNode right; public BinaryTreeNode(E data) { this.data = data; } public BinaryTreeNode(E data, BinaryTreeNode left, BinaryTreeNode right) { this.data = data; this.left = left; this.right = right; } @Override public String toString() { return data.toString(); } /*@Override public String toString() { return "BinaryTreeNode{" + "data=" + data + '}'; }*/ } /** * 空构造器 */ public LinkedBinaryTree() { } /** * 构造器,初始化root节点 * * @param root 根节点数据 */ public LinkedBinaryTree(E root) { checkNullData(root); this.root = new BinaryTreeNode<>(root); size++; } /** * 添加子节点 * * @param parent 父节点的引用 * @param data 节点数据 * @param left 是否是左子节点,true 是;false 否 */ public BinaryTreeNode addChild(BinaryTreeNode parent, E data, boolean left) { checkNullParent(parent); checkNullData(data); BinaryTreeNode node = new BinaryTreeNode<>(data); if (left) { if (parent.left != null) { throw new IllegalStateException("该父节点已经存在左子节点,添加失败"); } parent.left = node; } else { if (parent.right != null) { throw new IllegalStateException("该父节点已经存在右子节点,添加失败"); } parent.right = node; } size++; return node; } /** * 是否是空树 * * @return true 是 ;false 否 */ public boolean isEmpty() { return size == 0; } /** * 获取根节点 * * @return 根节点 ;或者null--表示空树 */ public BinaryTreeNode getRoot() { return root; } /** * 获取左子节点 * * @param parent 父节点引用 * @return 左子节点或者null--表示没有左子节点 */ public BinaryTreeNode getLeft(BinaryTreeNode parent) { return parent == null ? null : parent.left; } /** * 获取右子节点 * * @param parent 父节点引用 * @return 右子节点或者null--表示没有右子节点 */ public BinaryTreeNode getRight(BinaryTreeNode parent) { return parent == null ? null : parent.right; } /** * 数据判null * * @param data 添加的数据 */ private void checkNullData(E data) { if (data == null) { throw new NullPointerException("数据不允许为null"); } } /** * 检查父节点是否为null * * @param parent 父节点引用 */ private void checkNullParent(BinaryTreeNode parent) { if (parent == null) { throw new NoSuchElementException("父节点不能为null"); } }}
2.1 添加节点数据
public class TreeTest { /** * 构建二叉树,添加根节点r */ LinkedBinaryTree integerLinkedBinaryTree = new LinkedBinaryTree<>("r"); @Before public void buildTree() { /*构建二叉树*/ LinkedBinaryTree.BinaryTreeNode r = integerLinkedBinaryTree.getRoot(); //添加r根节点的左子结点a LinkedBinaryTree.BinaryTreeNode a = integerLinkedBinaryTree.addChild(r, "a", true); //添加r根节点的右子结点b LinkedBinaryTree.BinaryTreeNode b = integerLinkedBinaryTree.addChild(r, "b", false); //添加a节点的左子结点c LinkedBinaryTree.BinaryTreeNode c = integerLinkedBinaryTree.addChild(a, "c", true); //添加a节点的右子结点d LinkedBinaryTree.BinaryTreeNode d = integerLinkedBinaryTree.addChild(a, "d", false); //添加b节点的左子结点e LinkedBinaryTree.BinaryTreeNode e = integerLinkedBinaryTree.addChild(b, "e", true); //添加b节点的右子结点f LinkedBinaryTree.BinaryTreeNode f = integerLinkedBinaryTree.addChild(b, "f", false); //添加c节点的左子结点g LinkedBinaryTree.BinaryTreeNode g = integerLinkedBinaryTree.addChild(c, "g", true); //添加c节点的右子结点h LinkedBinaryTree.BinaryTreeNode h = integerLinkedBinaryTree.addChild(c, "h", false); //添加d节点的左子结点i LinkedBinaryTree.BinaryTreeNode i = integerLinkedBinaryTree.addChild(d, "i", true); //添加f节点的左子结点j LinkedBinaryTree.BinaryTreeNode j = integerLinkedBinaryTree.addChild(f, "j", true); }} 3 先序遍历 preorder traversal
3.1 先序遍历的介绍
规则是:若二叉树为空,则空操作返回;否则,从根节点开始,先遍历根,然后是左子树,最后遍历右子树;对于子树,同样从子树根开始,先遍历根,然后是左子树,最后遍历右子树。采用了递归的思想。
先序遍历中,对节点的遍历工作,是在对该节点的儿子节点的遍历之前进行遍历的。这也就是“先序”的得来。 先序遍历也叫前序遍历。从r根节点开始,其遍历流程如下:
3.2 先序遍历的简单实现
以下代码添加到LinkedBinaryTree类中。
/** * 保存遍历出来的节点数据 */ThreadLocalthreadLocal = ThreadLocal.withInitial(StringBuilder::new);/** * 先序遍历,提供给外部使用的api * * @return 遍历的数据 */public String toPreorderTraversalString() { //如果是空树,直接返回空 if (isEmpty()) { return null; } //从根节点开始递归 preorderTraversal(root); //获取遍历结果 String s1 = threadLocal.get().toString(); threadLocal.remove(); return s1.substring(0, s1.length() - 3);}/** * 先序遍历 内部使用的递归遍历方法 * * @param root 节点,从根节点开始 */private void preorderTraversal(BinaryTreeNode root) { //添加数节点 threadLocal.get().append(root).append("-->"); //获取节点的左子节点 BinaryTreeNode left = getLeft(root); if (left != null) { //如果左子节点不为null,则继续递归遍历该左子节点 preorderTraversal(left); } //获取节点的右子节点 BinaryTreeNode right = getRight(root); if (right != null) { //如果右子节点不为null,则继续递归遍历该右子节点 preorderTraversal(right); }}
3.2.1 测试
/** * 先序遍历 */@Testpublic void preorderTraversal() { String s = integerLinkedBinaryTree.toPreorderTraversalString(); System.out.println(s);} 查看输出:
r–>a–>c–>g–>h–>d–>i–>b–>e–>f–>j
确实图中的遍历顺序一致。
4 中序遍历 inorder traversal
4.1 中序遍历的介绍
规则是:若树为空,则空操作返回;否则,从根节点开始,先遍历根结点的左子树,然后是访问根结点,最后遍历右子树;对于子树,同样,先遍历子树根节点的左子树,然后是访问子树根结点,最后遍历右子树。采用了递归的思想。
中序遍历中,对节点的遍历工作,是在对该节点的左儿子节点的遍历之后、右儿子节点的遍历之前进行遍历的。这也就是“中序”的得来。 对图中的树采用中序遍历,从r根节点开始,顺序如下:
4.2 中序遍历的简单实现
/** * 中序遍历,提供给外部使用的api * * @return 遍历的数据 */public String toInorderTraversalString() { //如果是空树,直接返回空 if (isEmpty()) { return null; } //从根节点开始递归 inorderTraversal(root); //获取遍历结果 String s1 = threadLocal.get().toString(); threadLocal.remove(); return s1.substring(0, s1.length() - 3);}/** * 中序遍历 内部使用的递归遍历方法 * * @param root 节点,从根节点开始 */private void inorderTraversal(BinaryTreeNode root) { BinaryTreeNode left = getLeft(root); if (left != null) { //如果左子节点不为null,则继续递归遍历该左子节点 inorderTraversal(left); } //添加数据节点 threadLocal.get().append(root).append("-->"); //获取节点的右子节点 BinaryTreeNode right = getRight(root); if (right != null) { //如果右子节点不为null,则继续递归遍历该右子节点 inorderTraversal(right); }} 4.2.1 测试
/** * 中序遍历 */@Testpublic void inorderTraversal() { String s = integerLinkedBinaryTree.toInorderTraversalString(); System.out.println(s);} 查看输出:
g–>c–>h–>a–>i–>d–>r–>e–>b–>j–>f
确实图中的遍历顺序一致。
5 后序遍历 postorder traversal
5.1 后序遍历的介绍
规则是:若树为空,则空操作返回;否则,从根节点开始,先遍历根结点的左子树,然后是遍历右子树,最后遍历根结点;对于子树,同样,先遍历子树根节点的左子树,然后是遍历右子树,最后遍历子树根结点。采用了递归的思想。
后序遍历中,对节点的遍历工作,是在对该节点的儿子节点的遍历之后进行遍历的。这也就是“后序”的得来。 对图中的树采用后序遍历,从r根节点开始,顺序如下:
5.2 后序遍历的简单实现
/** * 后序遍历,提供给外部使用的api * * @return 遍历的数据 */public String toPostorderTraversalString() { //如果是空树,直接返回空 if (isEmpty()) { return null; } //从根节点开始递归 postorderTraversal(root); //获取遍历结果 String s1 = threadLocal.get().toString(); threadLocal.remove(); return s1.substring(0, s1.length() - 3);}/** * 后序遍历 内部使用的递归遍历方法 * * @param root 节点,从根节点开始 */private void postorderTraversal(BinaryTreeNode root) { BinaryTreeNode left = getLeft(root); if (left != null) { //如果左子节点不为null,则继续递归遍历该左子节点 postorderTraversal(left); } //获取节点的右子节点 BinaryTreeNode right = getRight(root); if (right != null) { //如果右子节点不为null,则继续递归遍历该右子节点 postorderTraversal(right); } //添加数据节点 threadLocal.get().append(root).append("-->");} 5.2.1 测试
/** * 后序遍历 */@Testpublic void postorderTraversal() { String s = integerLinkedBinaryTree.toPostorderTraversalString(); System.out.println(s);} 查看输出:
g–>h–>c–>i–>d–>a–>e–>j–>f–>b–>r
确实图中的遍历顺序一致。
6 层序遍历 level traversal
6.1 层序遍历的介绍
规则是:若树为空,则空操作返回;否则从树的第一层,也就是根结点开始访问,从上而下逐层遍历,在同一层中,按从左到右的顺序对结点逐个访问。
层序遍历中,对节点的遍历工作,上层节点的遍历先于下层节点的遍历。这也就是“层序”的得来。 对图中的树采用层序遍历,从r根节点开始,顺序如下:
6.2 层序遍历的简单实现
/** * 层序遍历,提供给外部使用的api * * @return 遍历的数据 */public String toLevelTraversalString() { //如果是空树,直接返回空 if (isEmpty()) { return null; } //从根节点开始遍历,借用队列 levelTraversal(root); //获取遍历结果 String s1 = threadLocal.get().toString(); threadLocal.remove(); return s1.substring(0, s1.length() - 3);}/** * 层序遍历 内部使用的借用了队列 * * @param root 节点,从根节点开始 */private void levelTraversal(BinaryTreeNode root) { Queue > q = new LinkedList<>(); q.add(root); while (!q.isEmpty()) { BinaryTreeNode nowNode = q.poll(); //添加数据节点 threadLocal.get().append(nowNode.data).append("-->"); if (nowNode.left != null) { //如果左子节点不为null,则将子节点加入队列 q.add(nowNode.left); } if (nowNode.right != null) { //如果右子节点不为null,则将子节点加入队列 q.add(nowNode.right); } }} 6.2.1 测试
/** * 层序遍历 */@Testpublic void levelTraversal() { String s = integerLinkedBinaryTree.toLevelTraversalString(); System.out.println(s);} 查看输出:
r–>a–>b–>c–>d–>e–>f–>g–>h–>i–>j
确实图中的遍历顺序一致。
7 遍历结果推导
题目:已知一棵二叉树的前序遍历序列为r–>a–>c–>h–>d–>i–>b–>e–>j–>k–>f,中序遍历序列为c–>h–>a–>d–>i–>r–>e–>k–>j–>b–>f,请问这棵二叉树的后序遍历结果是多少?
这样的题目常出现在面试中,这个原理其实并不是很复杂,并且有一定的规律性。下面一起来推导。7.6.1 寻找根节点
找到前序遍历的第1个字符:r,可知r是根节点;
再找到中序遍历中的根节点r的位置,r的左边c–>h–>a–>d–>i,这就是最大的左子树Ⅰ,e–>k–>j–>b–>f就是最大的右子树Ⅱ。7.6.2 推导左子树
找到前序遍历的第2个字符:a,然后在中序遍历的子树Ⅰ中也能找到节点a,可知a是r根节点的左子节点,也是左子树Ⅰ的根节点,;那么可以推导出来,左子树Ⅰ还具有左子树Ⅲ:c–>h和右子树Ⅳ:d–>i
找到前序遍历的第3、4个字符:c–>h,可知,c作为子树Ⅰ的左子结点,对比中顺序遍历顺序c–>h,可知h是c节点的右子结点; 找到前序遍历的第5、6个字符:d–>i,可知,d作为子树Ⅰ的右子结点,对比中顺序遍历顺序d–>i,可知 i是d节点的右子节点; 到此可以推导出最大的左子树的数据结构如下: 下面推导右子树。
下面推导右子树。 7.6.3 推导右子树
右子树Ⅱ的前序遍历节点就是排除左子树和根节点剩下的节点:b–>e–>j–>k–>f,中序遍历为e–>k–>j–>b–>f
前序遍历的第一个节点是b,可以b是右子树Ⅱ的根节点; 在中序遍历中b节点的左边是e–>k–>j,右边是f。可以f是节点b的右子结点,并且是叶子节点;这样还剩下最后的左子树Ⅴ; 左子树Ⅴ的前序遍历就是排除子树Ⅱ的根节点和子树Ⅱ的右子数节点,剩下:e–>j–>k,对应中序遍历为e–>k–>j。三个节点的前序排序和中序排序的结果一样,那么只有一种可能,那就是每个节点作为一层,并且最底层j是节点k的左子结点,中间层k是节点e右子节点,剩下的e节点,自然作为左子树Ⅴ的左子节点。 到此树结构推导完毕!树结构图如下: 有了树的结构,后序遍历的结果自然很明朗了:h–>c–>i–>d–>a–>k–>j–>e–>f–>b–>r。
有了树的结构,后序遍历的结果自然很明朗了:h–>c–>i–>d–>a–>k–>j–>e–>f–>b–>r。 7.6.4 快速推导
前序遍历序列为r–>a–>c–>h–>d–>i–>b–>e–>j–>k–>f,中序遍历序列为c–>h–>a–>d–>i–>r–> e–>k–>j–>b–>f。
后序排序的顺序为左子树、右子树、根节点。 r作为根节点,一定排在后序排序的最后一位。 最大的左子树Ⅰ中序排序为c–>h–>a–>d–>i,对应前序排序为a–>c–>h–>d–>i,根节点a。那么最大的右子树Ⅱ的其中序排序为e–>k–>j–>b–>f,前序排序为b–>e–>j–>k–>f,根节点b。 到此确定的顺序为: a–>b–>r。 下面看左子树Ⅰ,根节点为a,那么它的左右子节点别成子树Ⅲ、子树Ⅳ。 子树Ⅲ中序排序为c–>h,对应前序排序c–>h。到此可以确定的顺序为h–>c–>a–>b–>r。 子树四中序排序为d–>i,对应前序排序d–>i。到此可以确定的顺序为h–>c–>i–>d–>a–>b–>r。实际上到此已经把左子树进行了后序遍历。 下面看右子树Ⅱ,根节点为b,那么它的左右子节点别成子树Ⅴ、子树Ⅵ。 子树Ⅴ中序排序为e–>k–>j,对应前序排序e–>j–>k,根节点为e,由于中序排序和前序排序顺序一致,那么可以确定有三层,每层一个节点,第一层e、第二层k、第三层j。到此可以确定的顺序为h–>c–>i–>d–>a–>k–>j–>e–>b–>r。 剩下一个节点f,自然知道了位置唯一左子树节点和根节点之间,最终位置为:h–>c–>i–>d–>a–>k–>j–>e–>f–>b–>r。 完成推导。7.6.5 补充
- 已知前序遍历序列和中序遍历序列,可以唯一确定一棵二叉树。
- 已知后序遍历序列和中序遍历序列,可以唯一确定一棵二叉树。
- 已知前序和后序遍历,是不能确定一棵二叉树的。
案例如下,前序序列是ABC,后序序列是CBA,可能的结果又如下几种:
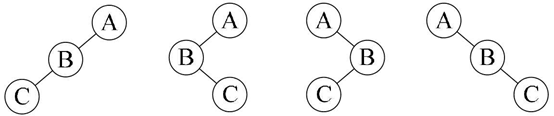
8 总结
本文对于二叉树的遍历,介绍了4种,前三种实际上都依赖了方法的递归,其底层是依赖了JVM的栈结构的方法调用;第四种层序遍历,依赖了队列。 关于方法的递归调用和栈的关系,可以看这篇文章:。
实际上,先序、中序、后序遍历又被称为深度优先遍历(DFS),其过程简要来说是对每一个可能的分支路径深入到不能再深入为止,而且每个节点只能访问一次;层序遍历又被称为广度优先遍历(BFS),之所以称之为宽度优先算法,是因为算法自始至终一直通过已找到和未找到顶点之间的边界向外扩展,就是说,算法首先搜索和s距离为k的所有顶点,然后再去搜索和S距离为k+l的其他顶点。 上面很多专业术语是如此的陌生,因为它属于图论算法中的一部分,实际上树(tree)就是一种特殊的没有闭环的图(map)。想要学好图吗?先跟我学好树吧!如果有什么不懂或者需要交流,可以留言。另外希望点赞、收藏、关注,我将不间断更新各种Java学习博客!
发表评论
最新留言
关于作者
