Python爬虫实列:新浪微博热门话题
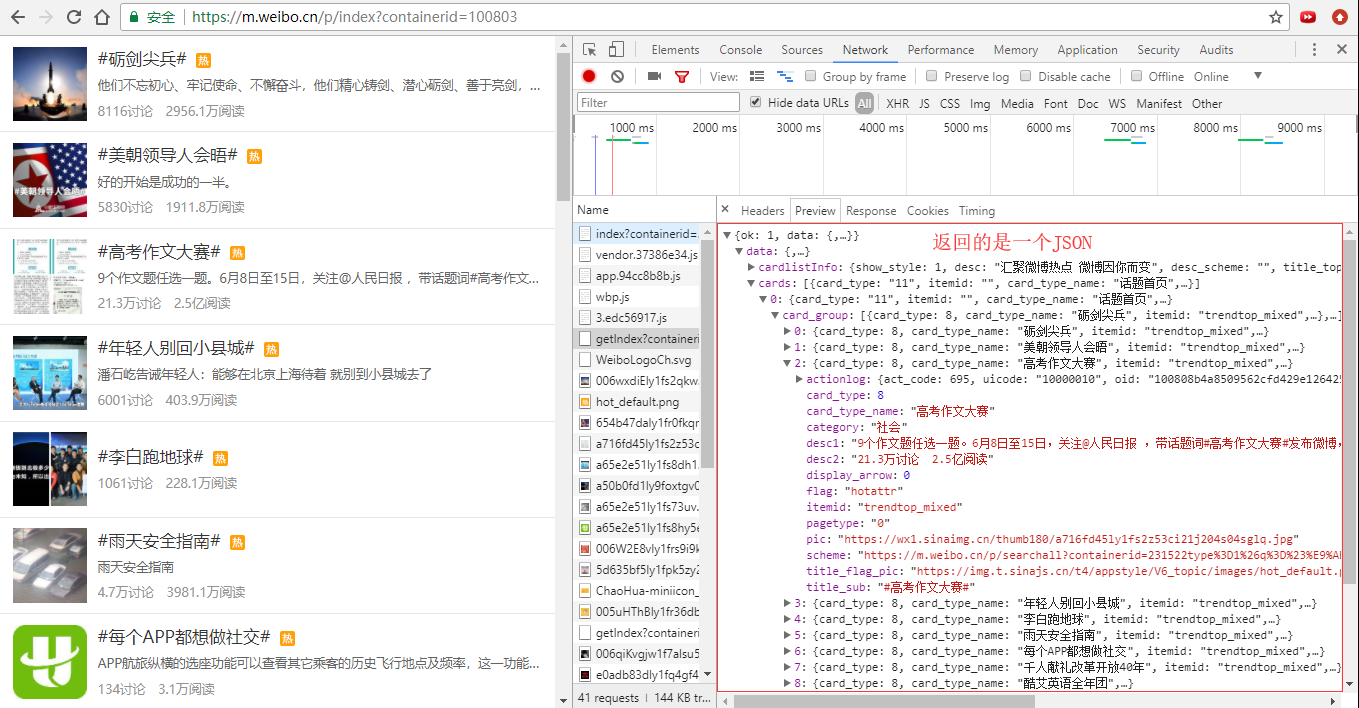
1.先找到数据所在的url
发布日期:2021-05-14 14:11:45
浏览次数:22
分类:精选文章
本文共 5860 字,大约阅读时间需要 19 分钟。
1.先找到数据所在的url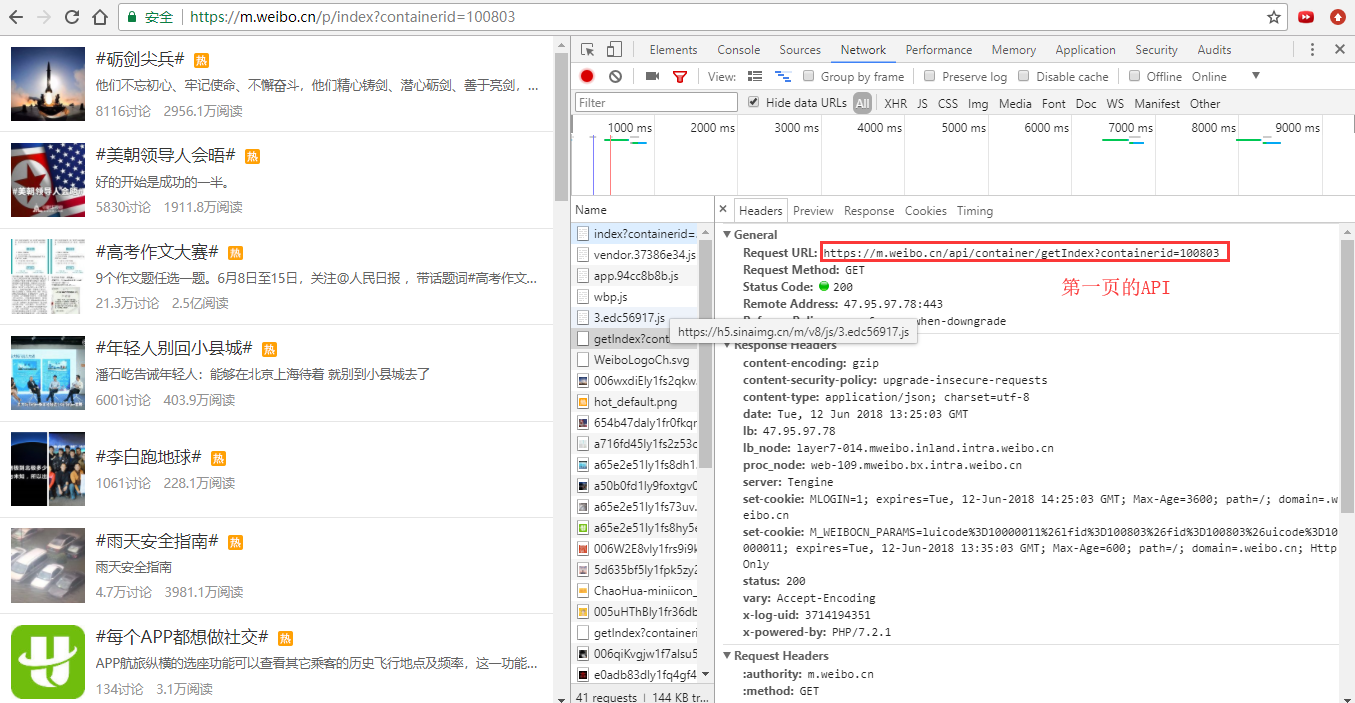
 2.写代码获取数据,并保存
2.写代码获取数据,并保存
import requestsimport timeimport sysimport osimport xlwt, xlrdimport xlutils.copy#传入要爬取的页数page,将获取的热门话题名称、类别、讨论数、阅读数存到二维列表中def get_hot_topic(page): topic_list = [] session = requests.session() for i in range(page): print("\n*****正在获取第{}页*****".format(i + 1)) if i == 0: the_url = "https://m.weibo.cn/api/container/getIndex?containerid=100803" if i == 1: the_url = "https://m.weibo.cn/api/container/getIndex?containerid=100803&since_id=%7B%22page%22:2,%22next_since_id%22:6,%22recommend_since_id%22:[%22%22,%221.8060920078958E15%22,%221.8060920009434E15%22,0]%7D" else: the_url = "https://m.weibo.cn/api/container/getIndex?containerid=100803&since_id=%7B%22page%22:{},%22next_since_id%22:{},%22recommend_since_id%22:[%22%22,%221.8060912084255E14%22,%221.8060920000515E15%22,0]%7D".format(i+1,6 + 14*(i-2)) header = {"User-Agent":"Mozilla/5.0 (Windows NT 10.0; Win64; x64) AppleWebKit/537.36 (KHTML, like Gecko) Chrome/64.0.3282.140 Safari/537.36", 'cookie': 'SCF=AtTCtKbsCE8JxtrO0kcD_C4f65Yn1U-tspMXv0bmj_6hIzGSTgr4GYtq3X5qaRmGPY3rS8HrRyz7YQeb51DKXVw.; SUB=_2A25zcABnDeRhGeVJ6lYQ-SrPzj2IHXVQmqAvrDV6PUJbktANLXLZkW1NT-MET2PLWPvDoriPDgqDIvvX8o7fA6UM; SUBP=0033WrSXqPxfM725Ws9jqgMF55529P9D9W5eGCL6N2RTW9mjY7Y465Lc5JpX5K-hUgL.FoeNeKBp1KB0SK22dJLoIpjLxK.LB.zL1K2LxK-LB.BLBo2LxK.L1-2L1K5t; SUHB=0D-F6txRCGnRJ9; _T_WM=98219736160; XSRF-TOKEN=aee893; WEIBOCN_FROM=1110006030; MLOGIN=1; M_WEIBOCN_PARAMS=fid%3D100803%26uicode%3D10000011', } try: r = session.get(the_url, headers = header) res = r.json() except requests.exceptions.ConnectionError: print("!!!网络连接出错,请检查网络!!!") time.sleep(2) for cards in res.get("data").get("cards"): #try: if cards.get("card_group") is None: continue for card in cards.get("card_group"): #print("***", card.get("title_sub"), card.get("category"), card.get("desc2")) title = card.get("title_sub") category = card.get("category") desc2 = card.get("desc2") if "超级话题" in desc2: print("超级话题:", end = "") scheme = card.get("scheme") topic_id = scheme[scheme.index("=") + 1 : scheme.index("=") + 7] topic_url = "https://m.weibo.cn/api/container/getIndex?containerid={}type%".format(topic_id)\ + "3D1%26q%3D%23%E7%8E%8B%E4%BF%8A%E5%87%AF%E4%B8%AD%E9%A4%90%E5%8E%"\ + "85%E7%AC%AC%E4%BA%8C%E5%AD%A3%23%26t%3D10&luicode=10000011&lfid="\ + "100803&page_type=searchall" r2 = session.get(topic_url) res2 = r2.json() desc2 = res2.get("data").get("cardlistInfo").get("cardlist_head_cards")[0].get("head_data").get("midtext").split() desc2.reverse() desc2 = " ".join(desc2) print(title, category, desc2.split()) cv = [] for n in desc2.split(): if "万" in n: for ch in n: if u'\u4e00' <= ch <= u'\u9fff': #去除中文 n = n.replace(ch, "") n = float(n) * 10000 elif "亿" in n: for ch in n: if u'\u4e00' <= ch <= u'\u9fff': #去除中文 n = n.replace(ch, "") n = float(n) * 100000000 else: for ch in n: if u'\u4e00' <= ch <= u'\u9fff': #去除中文 n = n.replace(ch, "") cv.append(int(n)) try: topic_list.append([title, category, cv[0], cv[1]]) except: continue #except: #continue time.sleep(2) print(len(topic_list)) return topic_list#将列表数据写入Excel文件中def write_excel(topic_list): root = os.getcwd() local_t = time.strftime("%Y-%m-%d-%H-%M", time.localtime()) path = root + "\\weibo_topic.xls" if os.path.exists(path): #如果存在该文件,添加数据 workbook = xlrd.open_workbook(path) #读取excel文件 sheet_names = workbook.sheet_names() #读取所有sheet的名称 wb = xlutils.copy.copy(workbook) if local_t not in sheet_names: sheet1 = wb.add_sheet(local_t, cell_overwrite_ok = False) #添加表 sheet1.write(0, 0, label = "标题") sheet1.write(0, 1, label = "类别") sheet1.write(0, 2, label = "讨论数") sheet1.write(0, 3, label = "阅读数") for row in range(len(topic_list)): for col in range(len(topic_list[row])): sheet1.write(row + 1, col, topic_list[row][col]) wb.save(path) print("文件更新成功:", path) else: #如果不存在xls文件则创建并添加数据 workbook = xlwt.Workbook() sheet1 = workbook.add_sheet(local_t, cell_overwrite_ok = True) #添加sheet sheet1.write(0, 0, label = "标题") sheet1.write(0, 1, label = "类别") sheet1.write(0, 2, label = "讨论数") sheet1.write(0, 3, label = "阅读数") for row in range(len(topic_list)): for col in range(len(topic_list[row])): sheet1.write(row + 1, col, topic_list[row][col]) workbook.save(path) print("文件保存成功:", path) def main(): topic_list = get_hot_topic(40) write_excel(topic_list)if __name__ == "__main__": main()
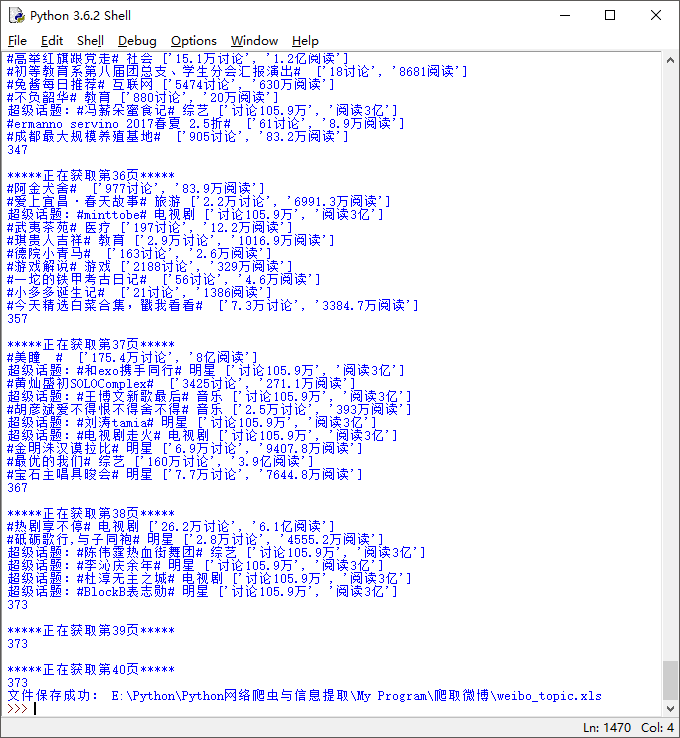
3.运行结果
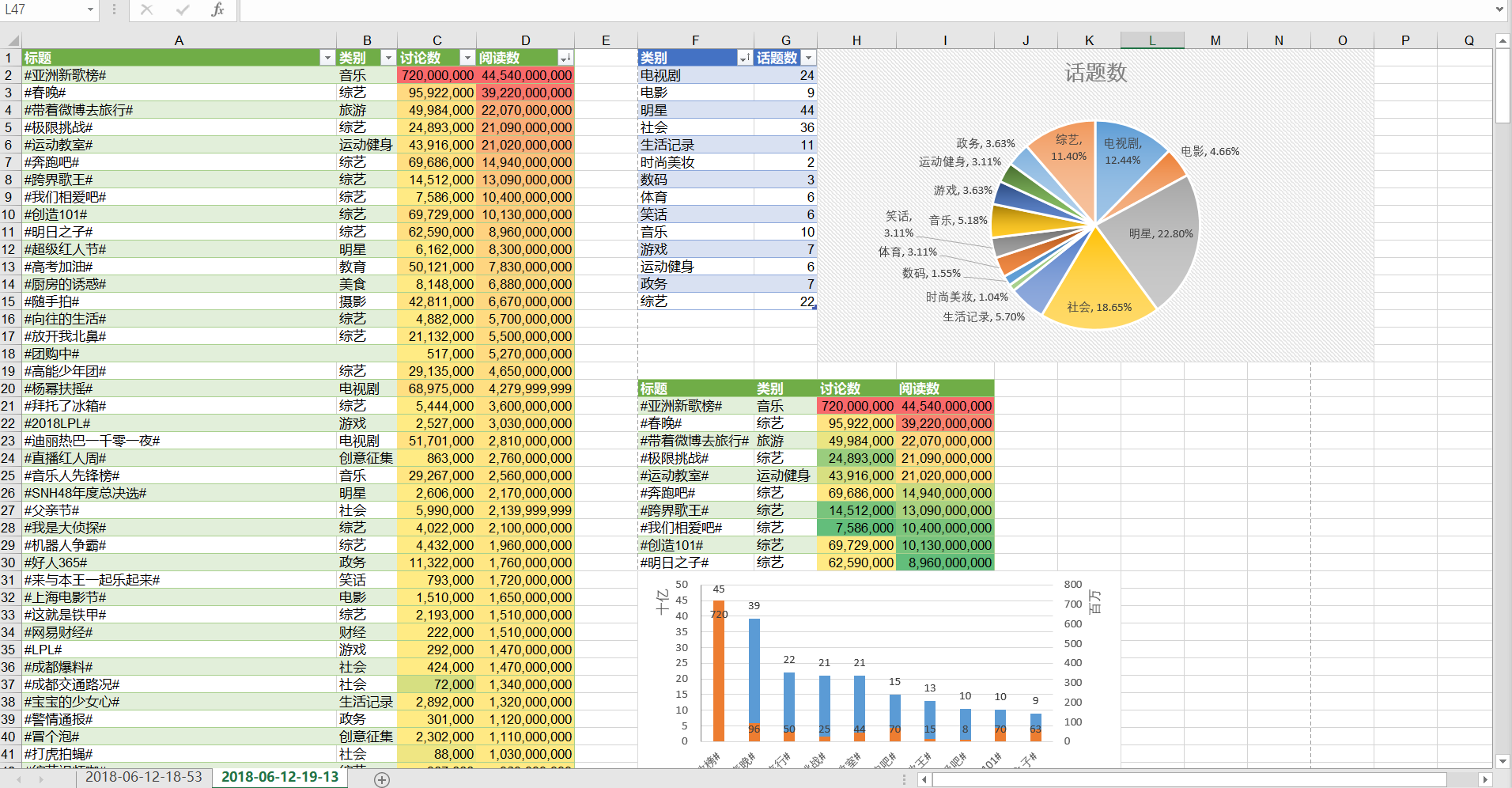
4.数据简单处理
5.补充说明
1.header需要把cookie加上,代码2020-04-21运行成功
2.get_hot_topic(40)爬取的是最新的前40页数据,结果保存在excel文件的新工作表中,工作表名称为当前时间
请使用手机"扫一扫"x
发表评论
最新留言
关注你微信了!
[***.104.42.241]2025年04月09日 23时19分04秒
关于作者

喝酒易醉,品茶养心,人生如梦,品茶悟道,何以解忧?唯有杜康!
-- 愿君每日到此一游!
推荐文章
IAR调试卡顿的解决办法
2021-05-13
Course Schedule II
2021-05-13
Django ORM操作
2021-05-13
剑指offer[32]——把数组排成最小的数
2021-05-13
java基础-java与c#接口不同点
2021-05-13
京喜小程序体验评分优化实践
2021-05-13
C#中文转换成拼音
2021-05-13
C#批量上传图片
2021-05-13
C++错误笔记
2021-05-13
【无线通信模块】GPRS DTU不稳定和容易掉线原因
2021-05-13
CSS(六)|页面布局之定位
2021-05-13
SpringBoot使用RedisTemplate简单操作Redis的五种数据类型
2021-05-13
国标流媒体服务器以ROOT身份运行提示“permission denide”报错解决
2021-05-13
qt中转到槽后如何取消信号与槽关联
2021-05-13
qt问题记录-spin box与double spin box
2021-05-13
移动端事件
2021-05-13
css 图片按比例缩放
2021-05-13
白红宇的个人博客 - 记录点点滴滴的事 - 您是第 461241605 位访客
访问时间: 2025-05-05 04:07:04
访问IP: 3.138.197.104
Copyright © 2020 - 2025 css8.cn 京ICP备2021015314号-1
手机版