利用python爬虫大量爬取网页图片
发布日期:2021-05-14 10:21:11
浏览次数:17
分类:原创文章
本文共 3638 字,大约阅读时间需要 12 分钟。
最近要进行一类图片的识别,因此需要大量图片,所以我用了python爬虫实现
一、爬取某一图片网站
主要参考:
爬取网页: (不过这个网页图片太少了)
1.1 代码
在安装相关库后及要爬取的网址后,可直接运行
在程序中相应地方可以更改爬取图片的网址和保存图片的路径
'''程序功能:爬取罂粟花图片作者:哥日期:2019.5.15版本更改说明:'''import requestsfrom bs4 import BeautifulSoupimport osdef getHtmlurl(url): #获取网址 try: r=requests.get(url) r.raise_for_status() r.encoding=r.apparent_encoding return r.text except: return ""def getpic(html): #获取图片地址并下载 soup =BeautifulSoup(html,'html.parser') all_img=soup.find('ul',class_='pli').find_all('img') for img in all_img: src=img['src'] img_url=src print (img_url) root='F:/poppy_pic/' path = root + img_url.split('/')[-1] try: #创建或判断路径图片是否存在并下载 if not os.path.exists(root): os.mkdir(root) if not os.path.exists(path): r = requests.get(img_url) with open(path, 'wb') as f: f.write(r.content) f.close() print("文件保存成功") else: print("文件已存在") except: print("爬取失败")def main(): url='https://www.ivsky.com/search.php?q=%E7%BD%82%E7%B2%9F%E8%8A%B1'# 这里我是搜索的罂粟花的图片,可以改成你搜索图片的网址 html=(getHtmlurl(url)) print(getpic(html)) #暂时不支持翻页,想要下载多页不,可以用下面的方式,就是把第二页、第三页的网址复制过来 # url='https://www.ivsky.com/search.php?q=%E7%BD%82%E7%B2%9F%E8%8A%B1&PageNo=2' # 这里我是搜索的罂粟花的图片,可以改成你搜索图片的网址 # html=(getHtmlurl(url)) # print(getpic(html))main()相关库介绍:
二、爬取百度图片
主要参考:
为了能够爬取更多的图片,我用了百度图片,下面是代码:
2.1 代码
'''程序功能:在百度图片里爬取罂粟花图片作者:哥日期:2019.5.15版本更改说明:'''# -*- coding: utf-8 -*-"""根据搜索词下载百度图片"""import reimport sysimport urllibimport requestsdef get_onepage_urls(onepageurl): """获取单个翻页的所有图片的urls+当前翻页的下一翻页的url""" if not onepageurl: print('已到最后一页, 结束') return [], '' try: html = requests.get(onepageurl) html.encoding = 'utf-8' html = html.text except Exception as e: print(e) pic_urls = [] fanye_url = '' return pic_urls, fanye_url pic_urls = re.findall('"objURL":"(.*?)",', html, re.S) fanye_urls = re.findall(re.compile(r'<a href="(.*)" class="n">下一页</a>'), html, flags=0) fanye_url = 'http://image.baidu.com' + fanye_urls[0] if fanye_urls else '' return pic_urls, fanye_urldef down_pic(pic_urls): """给出图片链接列表, 下载所有图片""" for i, pic_url in enumerate(pic_urls): try: pic = requests.get(pic_url, timeout=15) string = str(i + 1) + '.jpg' with open(string, 'wb') as f: f.write(pic.content) print('成功下载第%s张图片: %s' % (str(i + 1), str(pic_url))) except Exception as e: print('下载第%s张图片时失败: %s' % (str(i + 1), str(pic_url))) print(e) continueif __name__ == '__main__': keyword = '罂粟花' # 关键词, 改为你想输入的词即可, 相当于在百度图片里搜索一样 url_init_first = r'http://image.baidu.com/search/flip?tn=baiduimage&ipn=r&ct=201326592&cl=2&lm=-1&st=-1&fm=result&fr=&sf=1&fmq=1497491098685_R&pv=&ic=0&nc=1&z=&se=1&showtab=0&fb=0&width=&height=&face=0&istype=2&ie=utf-8&ctd=1497491098685%5E00_1519X735&word=' url_init = url_init_first + urllib.parse.quote(keyword, safe='/') all_pic_urls = [] onepage_urls, fanye_url = get_onepage_urls(url_init) all_pic_urls.extend(onepage_urls) fanye_count = 0 # 累计翻页数 while 1: onepage_urls, fanye_url = get_onepage_urls(fanye_url) fanye_count += 1 # print('第页' % str(fanye_count)) if fanye_url == '' and onepage_urls == []: break all_pic_urls.extend(onepage_urls) down_pic(list(set(all_pic_urls)))运行过程
图片是保存在py文件同文件夹下
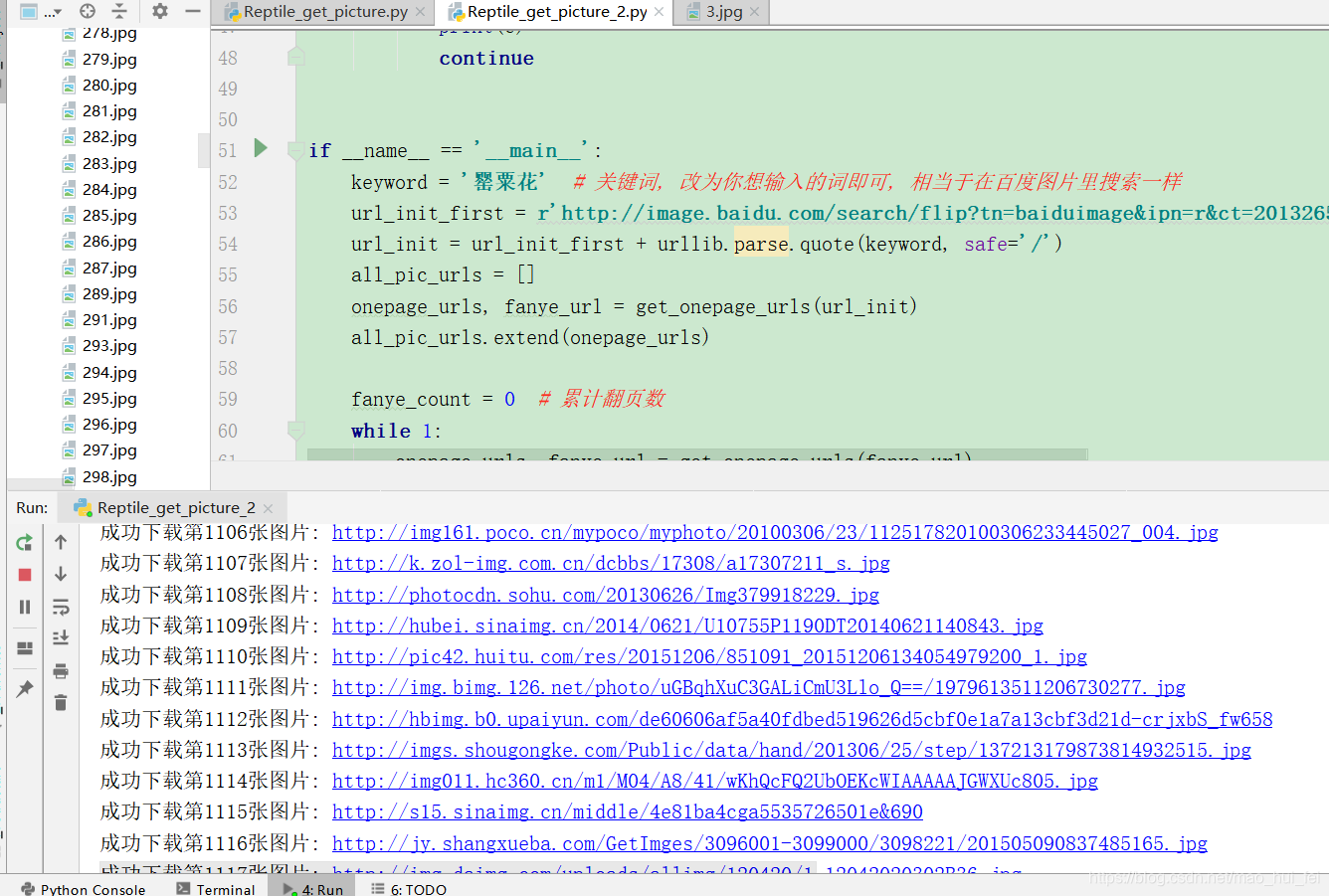
发表评论
最新留言
哈哈,博客排版真的漂亮呢~
[***.90.31.176]2025年04月06日 18时16分26秒
关于作者

喝酒易醉,品茶养心,人生如梦,品茶悟道,何以解忧?唯有杜康!
-- 愿君每日到此一游!
推荐文章
python中列表 元组 字典 集合的区别
2021-05-10
python struct 官方文档
2021-05-10
Android DEX加固方案与原理
2021-05-10
Android Retrofit2.0 上传单张图片和多张图片
2021-05-10
iOS_Runtime3_动态添加方法
2021-05-10
Leetcode第557题---翻转字符串中的单词
2021-05-10
Problem G. The Stones Game【取石子博弈 & 思维】
2021-05-10
Unable to execute dex: Multiple dex files
2021-05-10
Java多线程
2021-05-10
Unity监听日记
2021-05-10
AndroidStudio跳到错误位置
2021-05-10
openssl服务器证书操作
2021-05-10
expect 模拟交互 ftp 上传文件到指定目录下
2021-05-10
linux系统下双屏显示
2021-05-10
PDF.js —— vue项目中使用pdf.js显示pdf文件(流)
2021-05-10
我用wxPython搭建GUI量化系统之最小架构的运行
2021-05-10
我用wxPython搭建GUI量化系统之多只股票走势对比界面
2021-05-10
selenium+python之切换窗口
2021-05-10
重载和重写的区别:
2021-05-10
搭建Vue项目步骤
2021-05-10
白红宇的个人博客 - 记录点点滴滴的事 - 您是第 461275724 位访客