本文共 5369 字,大约阅读时间需要 17 分钟。
现在我们来到了五子棋ai的核心环节:极大极小搜索和α-β剪枝算法。这两个东西听上去挺高大上,但我实际中去实现之后才发现,原来也就是那么回事。
一、极大极小搜索
什么是极大极小搜索?我首先要介绍博弈树的概念。博弈树就是己方和敌方进行决策时形成的树状结构,每一个节点的分支表示当前节点可以走的各种可能的位置,每一个叶结点表示一个局面。比如说,从空棋盘开始(根节点),我进行落子,我有15x15=255种落子选择,我落子之后,形成了一颗有255个节点的博弈树,博弈树的叶结点就是一个局面。如果此时对手进行落子,对手有254种选择,那么新形成的博弈树就会有255x254个叶结点。
可以看到,博弈树是指数级别的,如果平均分支为b,博弈树层数为d(根节点为第0层),那么叶结点的总数约为b^d。
有了博弈树的概念,我们就可以实现能看几步的“聪明”ai了。那么怎么“看几步”呢?简单来说,就是遍历博弈树的所有叶结点,寻找到对ai最有利的局面,然后进行落子。在博弈树中,当ai走棋时选择对自己最有利的位置节点走,而当玩家走棋时,是ai模拟玩家选择对玩家最有利的位置节点走。由于评估函数F对局势的评分是对于ai白子来说的,所以ai走棋时选择F最大的节点,模拟玩家走棋时选择F最小的节点(F越小,对ai越不利,对玩家越有利,ai模拟玩家时是认为玩家是“聪明”的),这就是称为极大极小搜索的缘故。
二、极大极小搜索优化
1.α-β剪枝算法
这个算法的名字听起来很高大上,但是实际内涵并不难理解。
举一个很简单的例子。
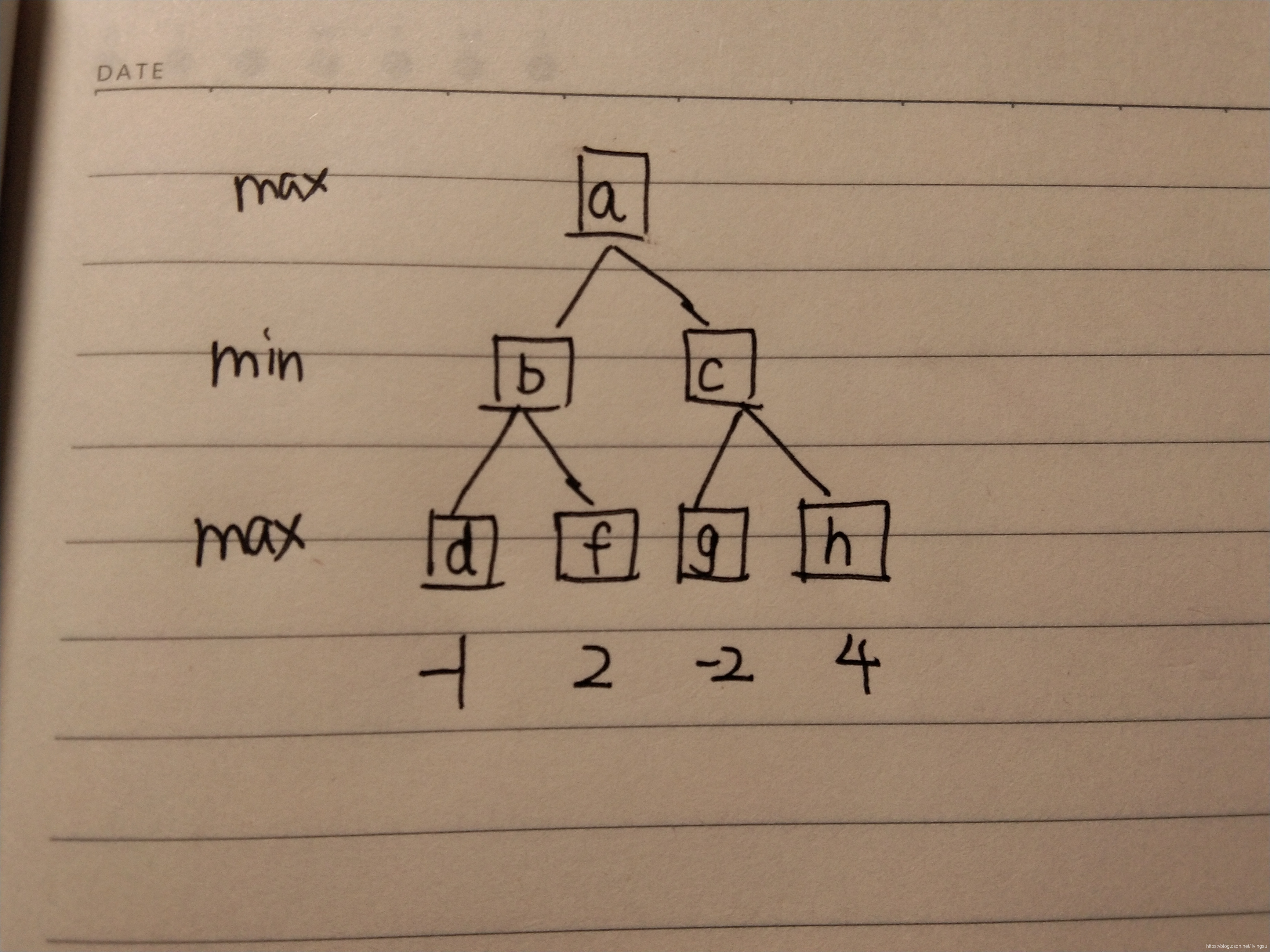 max层表示这一层节点的值应该选它的子节点的最大值,min层表示这一层节点的值应该选它的子节点的最小值。
max层表示这一层节点的值应该选它的子节点的最大值,min层表示这一层节点的值应该选它的子节点的最小值。 对于这样一颗博弈树,已知了叶结点d、f、g、h的值,怎么求a的值呢?首先由d、f可以知道b的值为-1,然后a搜完了b节点,搜索另一边,搜索到a-c-g,此时可以知道c的值必然是<=-2的,由于a要选最大值节点,b的值已经大于c了,没有必要再搜完c节点,那么a-c-h这一个分支就被“剪掉了”。
α-β剪枝算法中每一个节点对应有一个α和一个β,α表示目前该节点的最好下界,β表示目前该节点的最好上界。在最开始时,α为负无穷,β为正无穷。然后进行搜索,max层节点每搜索它的一个子节点,就要更新自己的α(下界),而min层节点每搜索它的一个子节点,就要更新自己的β(上界)。如果更新之后发现α>=β了,说明后面的子节点已经不需要进行搜索了,直接break剪枝掉。这就是α-β剪枝算法的全部含义。
我的代码:
struct POINTS{ //最佳落子位置,[0]分数最高,[9]分数最低 QPoint pos[10]; int score[10];//此处落子的局势分数};struct DECISION{ QPoint pos;//位置 int eval;//对分数的评估};DECISION decision;//analyse得到的最佳落子点 int chessAi::analyse(int (*board)[15], int depth, int alpha, int beta){ gameResult RESULT=evaluate(board).result; if(depth==0||RESULT!=R_DRAW){ //如果模拟落子可以分出输赢,那么直接返回结果,不需要再搜索 if(depth==0) POINTS P; P=seekPoints(board);//生成最佳的可能落子位置 return P.score[0];//返回最佳位置对应的最高分 }else return evaluate(board).score; }else if(depth%2==0){ //max层,我方(白)决策 int sameBoard[15][15]; copyBoard(board,sameBoard); POINTS P=seekPoints(sameBoard); for(int i=0;i<10;++i){ sameBoard[P.pos[i].x()][P.pos[i].y()]=C_WHITE;//模拟己方落子,不能用board,否则可能改变board的信息 int a=analyse(sameBoard,depth-1,alpha,beta); sameBoard[P.pos[i].x()][P.pos[i].y()]=C_NONE;//还原落子 if(a>alpha){ alpha=a; if(depth==4){ //4是自己设立的深度(可以改为6,8,但必须为偶数),用来找最佳落子 decision.pos.setX(P.pos[i].x()); decision.pos.setY(P.pos[i].y()); decision.eval=a; } } if(beta<=alpha)break;//剪枝 } return alpha; }else{ //min层,敌方(黑)决策 int rBoard[15][15]; reverseBoard(board,rBoard); POINTS P=seekPoints(rBoard);//找对于黑子的最佳位置,需要将棋盘不同颜色反转,因为seekPoint是求白色方的最佳位置 int sameBoard[15][15]; copyBoard(board,sameBoard); for(int i=0;i<10;++i){ sameBoard[P.pos[i].x()][P.pos[i].y()]=C_BLACK;//模拟敌方落子 int a=analyse(sameBoard,depth-1,alpha,beta); sameBoard[P.pos[i].x()][P.pos[i].y()]=C_NONE;//还原落子 if(a seekPoints()是用来找目前局面时最佳的几个落子点的位置以及落子之后的分数,这里用了局部搜索和静态评价启发来提高效率,后面再讲。
有几点非常容易犯错(我改bug花了半周),需要注意:
1.博弈树搜索深度depth必须为偶数,因为叶结点的局面评估函数F是对于白子走了一步的局面评估的,如果depth为奇数,会导致叶结点的F估值错误。 2.递归调用analyse时,不能用原来的board棋盘数组,因为analyse会模拟落子,如果简单的在board上面模拟落子会改变board的信息,后面的递归调用会不停的修改board,这样就不会得到正确结果。好的做法是复制一个新棋盘数组,然后模拟落子,再作为参数传给递归的analyse。2.局部搜索和静态评价启发
由于博弈树是指数级别的,如果能想办法减小平均分支数b,就能极大减少叶结点的数量。
局部搜索是说,只考虑那些能和棋子产生关系的空位置,而不用考虑所有空位置,这样能极大减小b的值。我的局部搜索的考虑棋盘上每一个有子点周围8个方向上延申3个深度,只有这些地方会与现有棋子产生联系。
静态评价启发是对于α-β剪枝算法而言的,意思是说,如果越早搜索到较优走法,剪枝就会越早发生。如果对可走节点的评估分数进行简单排序,就可以提高剪枝速度。我将局部搜索得到的所有可走节点的分数进行排序,放到POINTS类的一个对象中,[0]分数最高,[9]分数最低。
seekPoints()是综合了这两种优化方式的生成最佳落子位置函数,一般来说,搜索10个最优走法就已经可以满足需求了,可以极大提升搜索速度,但如果过多减小有可能剪掉有利分支。那么,如果是搜索深度为4,最多只需要搜索10^5=100000个叶结点,并且静态评价启发和α-β剪枝算法进一步减少,实际程序运行只需要搜索5000个叶结点,减少得非常多了!
struct POINTS{ //最佳落子位置,[0]分数最高,[9]分数最低 QPoint pos[10]; int score[10];//此处落子的局势分数};POINTS chessAi::seekPoints(int board[15][15]){ bool B[15][15];//局部搜索标记数组 int worth[15][15]; POINTS best_points; memset(B,0,sizeof (B)); for(int i=0;i<15;++i){ //每个非空点附近8个方向延伸3个深度,若不越界则标记为可走 for(int j=0;j<15;++j){ if(board[i][j]!=C_NONE){ for(int k=-3;k<=3;++k){ if(i+k>=0&&i+k<15){ B[i+k][j]=true; if(j+k>=0&&j+k<15)B[i+k][j+k]=true; if(j-k>=0&&j-k<15)B[i+k][j-k]=true; } if(j+k>=0&&j+k<15)B[i][j+k]=true; } } } } for(int i=0;i<15;++i){ for(int j=0;j<15;++j){ worth[i][j]=-INT_MAX; if(board[i][j]==C_NONE&&B[i][j]==true){ board[i][j]=C_BLACK; worth[i][j]=evaluate(board).score; board[i][j]=C_NONE; } } } int w; for(int k=0;k<10;++k){ w=-INT_MAX; for(int i=0;i<15;++i){ for(int j=0;j<15;++j){ if(worth[i][j]>w){ w=worth[i][j]; QPoint tmp(i,j); best_points.pos[k]=tmp; } } } best_points.score[k]=w; worth[best_points.pos[k].x()][best_points.pos[k].y()]=-INT_MAX;//清除掉上一点,计算下一点的位置和分数 } return best_points;} 结束语
那么到这里,实现的五子棋ai就已经基本结束了。ai当深度为4时表现相当优异(不到0.5秒),而当深度为6时运行就比较慢了(前面要8秒,后面就快了,只用2、3秒)。看别的大佬的项目,还实现了深度迭代算杀、zobrist缓存优化和多线程等更深的技术,无奈我们现在开始上网课了,之前丢掉的unity项目也忘得差不多了,总之事情一大堆,那么继续优化的事情还是以后有空再说吧。
这个项目搞了我一个多星期,现在回想起来,自己走了不少弯路,也得到了不少经验教训,在这里写博客是想分享自己费了好大功夫弄出来的估值函数那一块,别人能少踩几个坑吧,毕竟自己找资料蛮辛苦的。
发表评论
最新留言
关于作者
