100毫秒过滤一百万字文本的停用词
发布日期:2021-05-10 12:02:29
浏览次数:12
分类:精选文章
本文共 3247 字,大约阅读时间需要 10 分钟。
作者简介:小小明,Pandas数据处理专家,致力于帮助无数数据从业者解决数据处理难题。
之前有位群友分享了使用Pandas过滤停用词的技巧:
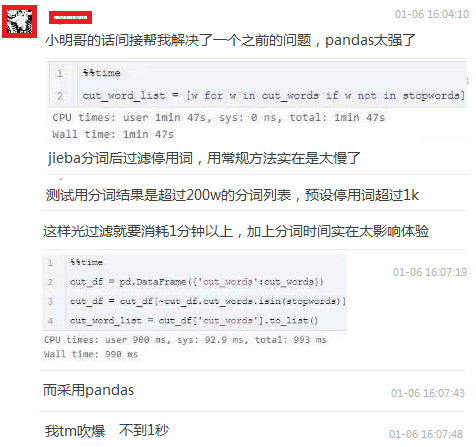
不过其实这并不是效率最高的一种方法,今天我将演示一种更高效过滤停用词的方法。
文章目录
过滤停用词前的准备工作
这次我打算用一部197W字的小说作为数据示例。
数据读取
首先,我们读取这部小说的数据:
with open(r"D:\hdfs\novels\天龙八部.txt", encoding="gb18030") as f: text = f.read()print(len(text))
结果:
1272432
可见这部小说共127.2万字。
下面我们对它进行分词并加载停用词:
jieba分词器设置角色为特定词汇
为了避免jieba分词库不能将主角正确的切词,所以现在我们需要将这部小说的角色名称加入到jieba的分词表中。
首先,加载《天龙八部》小说的角色名称:
with open('D:/hdfs/novels/names.txt', encoding="utf-8") as f: for line in f: if line.startswith("天龙八部"): names = next(f).split() breakprint(names[:20]) 前20个角色为:
['刀白凤', '丁春秋', '马夫人', '马五德', '小翠', '于光豪', '巴天石', '不平道人', '邓百川', '风波恶', '甘宝宝', '公冶乾', '木婉清', '包不同', '天狼子', '太皇太后', '王语嫣', '乌老大', '无崖子', '云岛主']
设置角色到特定词汇中:
import jiebafor word in names: jieba.add_word(word)
提示了一些警告信息:
Building prefix dict from the default dictionary ...Loading model from cache C:\Users\Think\AppData\Local\Temp\jieba.cacheLoading model cost 0.759 seconds.Prefix dict has been built successfully.
开始分词
然后对原始文本进行中文分词:
%time cut_word = jieba.lcut(text)
Wall time: 6 s
中文分词耗时6秒。
加载停用词
然后加载停用词:
# 加载停用词with open("stoplist.txt", encoding="utf-8-sig") as f: stop_words = f.read().split()stop_words.extend(['天龙八部', '\n', '\u3000', '目录', '一声','之中', '只见'])print(len(stop_words), stop_words[:10]) 5748 ['说', '人', '元', 'hellip', '&', ',', '?', '、', '。', '"']
过滤停用词的n种方法性能对比
直接过滤
%%timeall_words = [word for word in cut_word if len(word) > 1 and word not in stop_words]print(len(all_words), all_words[:20])
结果:
300656 ['释名', '青衫', '磊落', '险峰', '玉壁', '月华', '马疾香幽', '高人远', '微步', '纹生', '谁家', '子弟', '谁家', '无计悔', '多情', '虎啸', '龙吟', '换巢', '鸾凤', '剑气']Wall time: 26.2 s
直接过滤耗时26.2秒

使用Pandas进行停用词过滤
%%timewords = pd.Series(cut_word)all_words = words[(words.str.len() > 1) & (~words.isin(stop_words))].tolist()print(len(all_words), all_words[:20])
结果:
300656 ['释名', '青衫', '磊落', '险峰', '玉壁', '月华', '马疾香幽', '高人远', '微步', '纹生', '谁家', '子弟', '谁家', '无计悔', '多情', '虎啸', '龙吟', '换巢', '鸾凤', '剑气']Wall time: 465 ms
耗时0.46秒

使用set集合过滤
%%timestop_words = set(stop_words)all_words = [word for word in cut_word if len(word) > 1 and word not in stop_words]print(len(all_words), all_words[:20])
结果:
300656 ['释名', '青衫', '磊落', '险峰', '玉壁', '月华', '马疾香幽', '高人远', '微步', '纹生', '谁家', '子弟', '谁家', '无计悔', '多情', '虎啸', '龙吟', '换巢', '鸾凤', '剑气']Wall time: 104 ms
耗时0.1秒

速度最快的过滤方法
虽然我们过滤停用词使用set集合过滤更快,但是我们并没有考虑一开始分词过程所消耗的时间,分词耗时达到6秒的时间,有没有办法降低这个时间呢?
先看看使用set集合的情况,分词过滤的整体耗时:
%%timeall_words = [word for word in jieba.cut(text) if len(word) > 1 and word not in stop_words]print(len(all_words), all_words[:20])
结果:
300656 ['释名', '青衫', '磊落', '险峰', '玉壁', '月华', '马疾香幽', '高人远', '微步', '纹生', '谁家', '子弟', '谁家', '无计悔', '多情', '虎啸', '龙吟', '换巢', '鸾凤', '剑气']Wall time: 5.91 s
耗时5.9s秒。
但假如我们一开始就将停用词从原始文本中去掉会不会更快点呢?
%%timetext_sub = textfor stop_word in stop_words: text_sub = text_sub.replace(stop_word, " ")all_words = [word for word in jieba.cut(text_sub) if len(word) > 1]print(len(all_words), all_words[:20])
结果:
174495 ['天龙', '释名', '青衫', '磊落', '险峰', '玉壁', '月华', '马疾香幽', '微步', '纹生', '子弟', '家院', '计悔', '虎啸', '龙吟', '换巢', '鸾凤', '剑气', '碧烟', '水榭']Wall time: 5.76 s
整体耗时5.7秒。
速度稍微提升了一丁点儿,区别不大,结果差异还挺大,所以还是使用set集合来过滤比较好一点。
总结
综上所述,中文分词过滤停用词时,使用set集合即可获得最好的性能。
感谢各位读者的陪伴,下期我们将分享 和 。
咱们不见不散,下期再见~
发表评论
最新留言
哈哈,博客排版真的漂亮呢~
[***.90.31.176]2025年04月17日 14时44分31秒
关于作者

喝酒易醉,品茶养心,人生如梦,品茶悟道,何以解忧?唯有杜康!
-- 愿君每日到此一游!
推荐文章
接收get或post数据使用fwrite写入文件中,方便追踪错误;或其他几种缓存方式
2021-05-10
mysql开启慢查询日志及查询
2021-05-10
Window平台Grpc框架搭建
2021-05-10
C中几道位运算的例题
2021-05-10
python入门(二)基础知识
2021-05-10
golang log4go 使用说明及丢失日志原因
2021-05-10
Android Studio打包生成Jar包的方法
2021-05-10
Excel 如何根据单元格中的值设立不同的颜色(或渐变)?(222)
2021-05-10
python 文件操作 open()与with open() as的区别(打开文件)
2021-05-10
python中列表 元组 字典 集合的区别
2021-05-10
python struct 官方文档
2021-05-10
Docker镜像加速
2021-05-10
Unity3D的InputField输入框控件按下Tab键光标自动切换
2021-05-10
静态数组类的封装(泛型)
2021-05-10
操作记录-2021-03-15: sunxiaoyu_project
2021-05-10
Android DEX加固方案与原理
2021-05-10
白红宇的个人博客 - 记录点点滴滴的事 - 您是第 460827485 位访客
访问时间: 2025-04-29 21:56:31
访问IP: 18.227.183.215
Copyright © 2020 - 2025 css8.cn 京ICP备2021015314号-1
手机版