Python+Tesseract-OCR识别图片上的文本内容
发布日期:2021-05-10 11:26:19
浏览次数:18
分类:精选文章
本文共 474 字,大约阅读时间需要 1 分钟。
目标
解决UI自动化过程中的图文验证码问题,过程大致分为两个步骤:
- 自动下载网页上指定的图片
- 识别图片上的文本内容
本文以“识别页面上指定图片的文本“为例。
代码实现效果
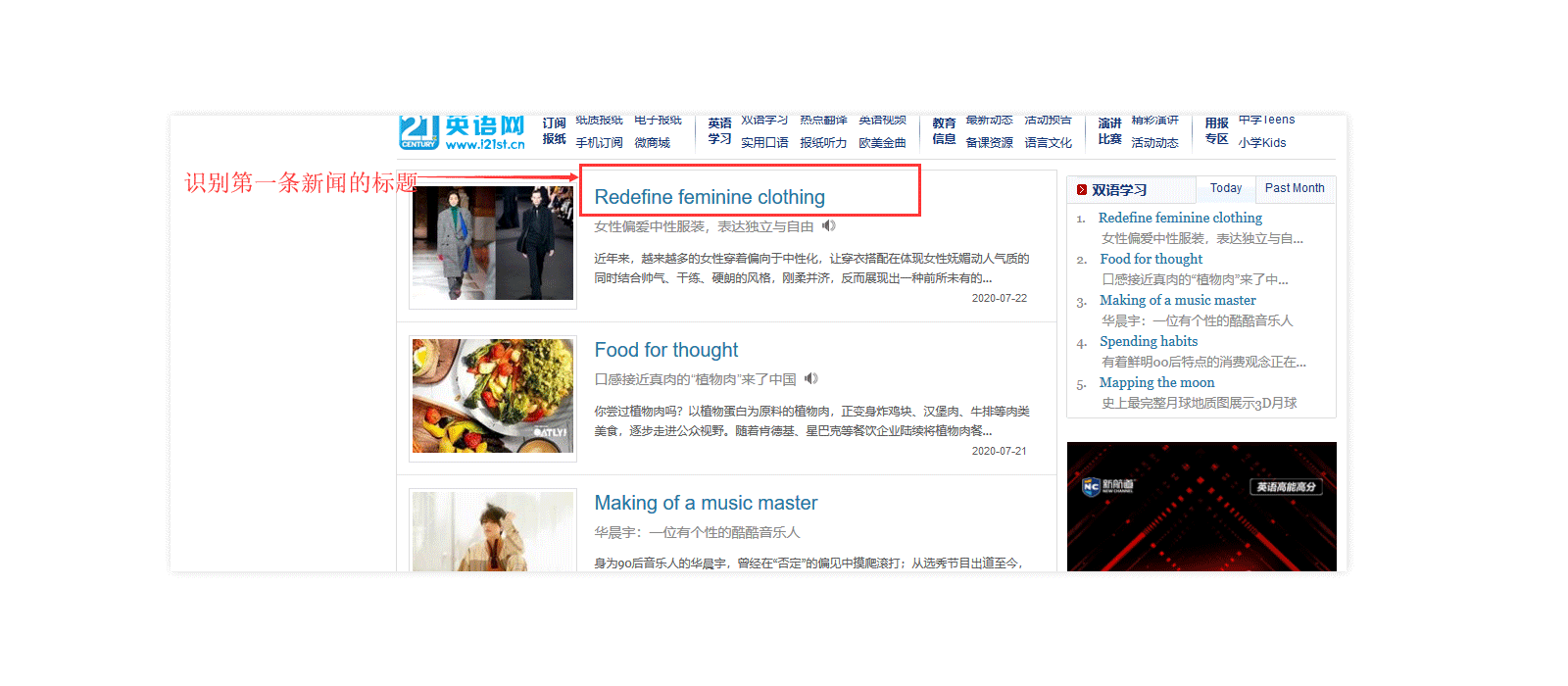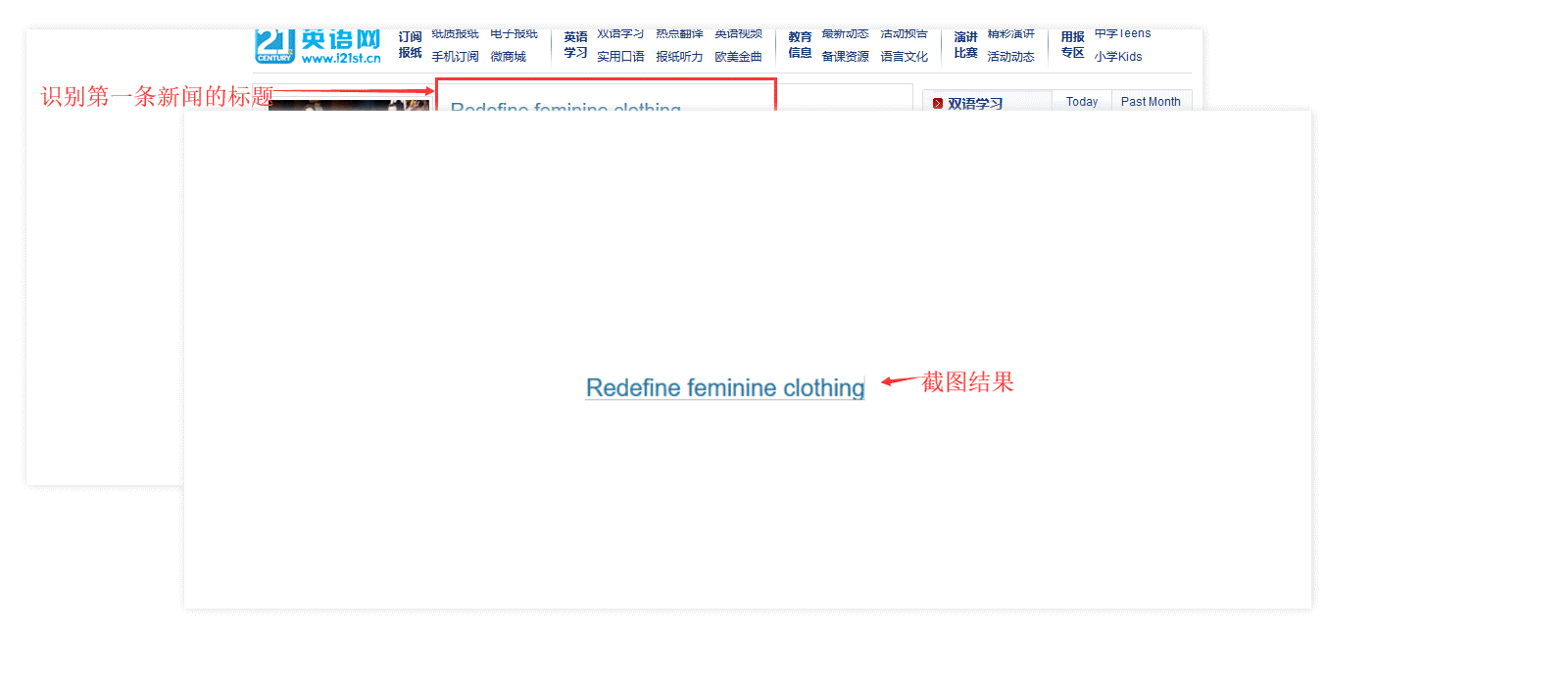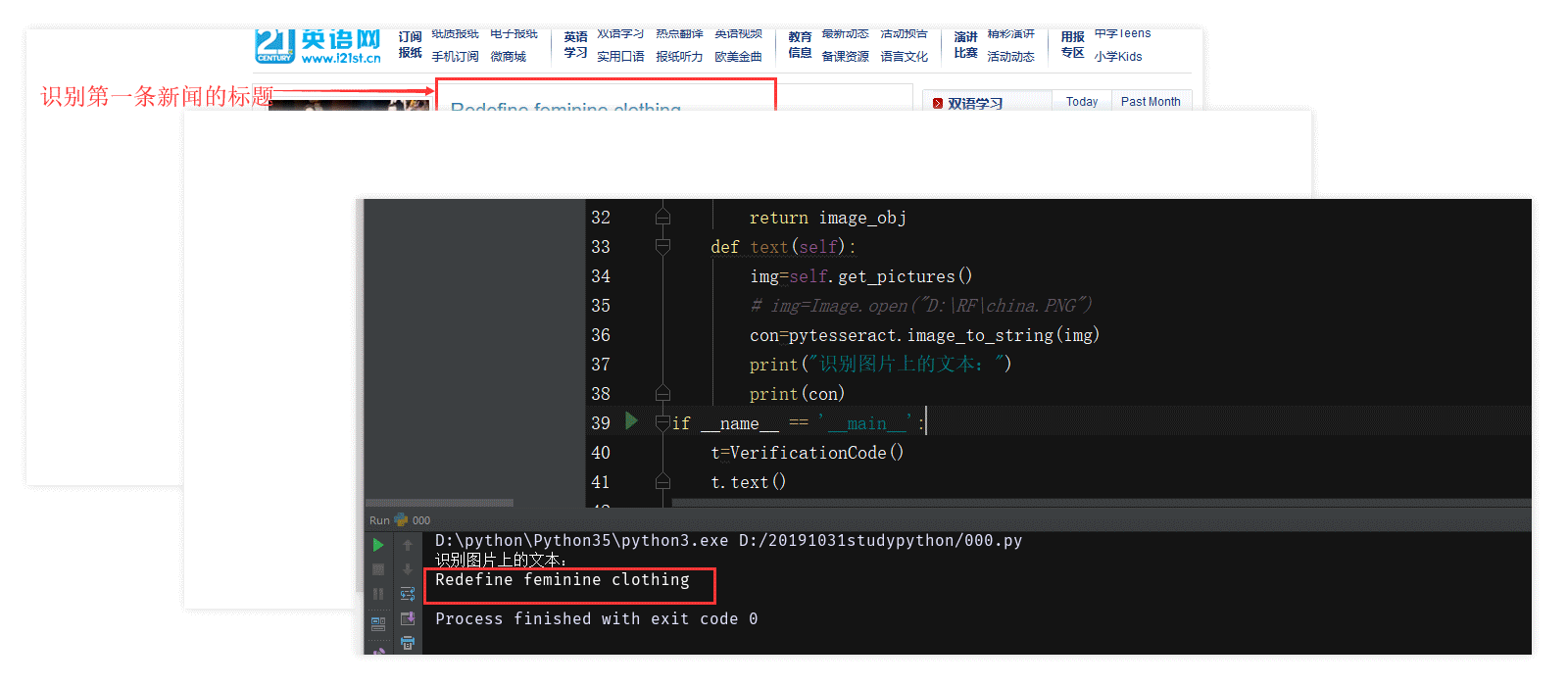

环境准备
- Pytesseract
- Tesseract-OCR
- Pillow
手动安装pytesseract库
命令:pip install pytesseract

安装Tesseract-OCR.exe
下载地址

双击exe程序直接安装即可

配置环境变量


校验安装成功

安装Pillow包
Python自带的图文简单处理模块,正常安装Python的时候会自动安装,故无需另外手动安装。(若没自动安装则可手动安装:pip install Pillow)
代码正文
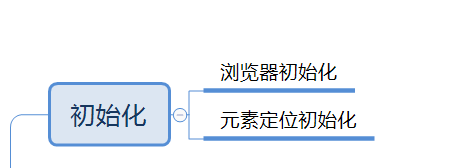
初始化浏览器和元素定位方式
- 初始化并放大浏览器
- 初始化元素定位方式:本文使用CSS选择器方式定位

获取图片
- 页面全屏截图
- 截图转为Image对象
- 获取指定图片的大小和位置
- 裁剪图片


识别图片上的文本
- 识别裁剪后的图片上的文本内容
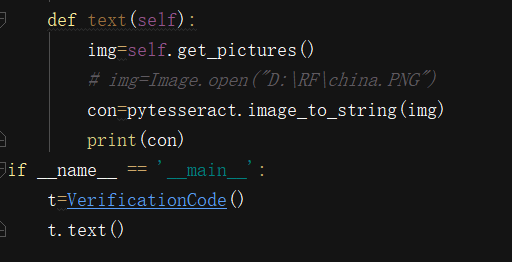

问题:
Python脚本运行报错:

解决方案:
修改tesseract文件的默认路径

发表评论
最新留言
做的很好,不错不错
[***.243.131.199]2025年04月13日 06时21分59秒
关于作者

喝酒易醉,品茶养心,人生如梦,品茶悟道,何以解忧?唯有杜康!
-- 愿君每日到此一游!
推荐文章
HDOJ1028-Ignatius and the Princess III(整数划分)
2021-05-10
学习spring security 5~入门
2021-05-10
ArcServer10.1-10.2集群部署和Nginx结合负载均衡
2021-05-10
ArcEngine代码 GP区域分析之面积制表(统计各行政区内的各土地利用类型面积)
2021-05-10
ArcEngine代码 GP提取分析之筛选
2021-05-10
Flutter-Dart version solving failed
2021-05-10
JAVA变量和运算符
2021-05-10
常见状态码
2021-05-10
重定向
2021-05-10
08-springmvc-异常解析器
2021-05-10
杂谈: 记一次深夜发版经历
2021-05-10
在select后面嵌套子查询
2021-05-10
表的复制和批量插入
2021-05-10
MYISAM存储引擎
2021-05-10
练习题第一道
2021-05-10
什么情况必须使用 statement
2021-05-10
账号转账演示事务
2021-05-10
HDML BS结构和CS结构介绍
2021-05-10
Object类:jDK类库的根类
2021-05-10
白红宇的个人博客 - 记录点点滴滴的事 - 您是第 460824170 位访客
访问时间: 2025-04-29 21:14:48
访问IP: 3.148.247.210
Copyright © 2020 - 2025 css8.cn 京ICP备2021015314号-1
手机版