本文共 1060 字,大约阅读时间需要 3 分钟。
核心思想
本文在度量学习的基础上结合了语义信息实现小样本学习任务。作者的核心观点是在小样本条件下,有些时候图像特征信息具有较高的区分度,而有些时候语义信息具有较高的区分度,为了提高分类的准确度,作者提出一种自适应模态混合机制(Adaptive Modality Mixture Mechanism ,AM3)将两种信息结合,并利用一个网络输出二者之间的比例权重,利用混合的特征信息极大的改善了原有算法的分类效果。整个网络的流程如下图所示

如上图所示,训练图片经过一个特征提取网络 f f f得到对应的图像特征向量 P c P_c Pc,然后语义标签信息首先经过一个词嵌入模型 W \mathcal{W} W(提前在一个大规模文本语料库中经无监督训练得到的)得到对应的语义特征向量 e c e_c ec,然后经过一个维度变换网络 g g g将其转化为可以用于融合 的特征 W c W_c Wc,融合方式如下
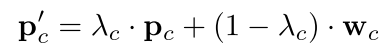
式中 λ c \lambda_c λc是一个分配权重系数,通过以下方式计算得到
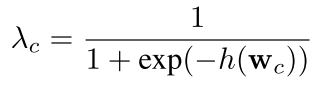
式中 h h h是一个自适应混合网络。将混合后的特征 P c ′ P_{c}' Pc′’作为原型,采用Prototypical Network的方式进行分类预测
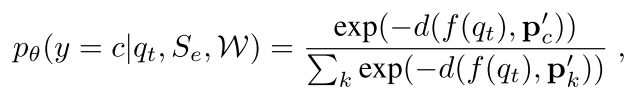
θ \theta θ表示网络参数,包含 θ f , θ g , θ h \theta_f,\theta_g,\theta_h θf,θg,θh三个部分。
实现过程
网络结构
特征提取网络 f f f采用ResNet-12结构,语义变换网络 g g g只有一个隐藏层,包含300个神经元,自适应混合网络 h h h同样只有一个隐藏层,包含300个神经元, g g g和 h h h均采用ReLU激活函数与dropout操作。
损失函数
如下所示
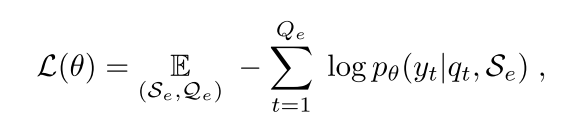
训练策略
如下所示

创新点
- 在特征提取阶段引入语义特征信息,并利用自适应混合网络调整语义特征与图像特征的融合比例
算法评价
本文提出的方法非常简单,思路也很清晰,设计的结构也很精简,不会对原有的基于度量学习的方法带来过多的计算压力,但却取得了非常显著的进步,在多个数据集上相对于baseline,本文的分类精度都有明显提升,尤其是在one-shot条件下,提升幅度甚至超过10%。本文提出的方法可移植性也比较强,能够广泛的同基于度量学习的小样本分类算法相结合,具有较强的学习和实用价值。
如果大家对于深度学习与计算机视觉领域感兴趣,希望获得更多的知识分享与最新的论文解读,欢迎关注我的个人公众号“深视”。
发表评论
最新留言
关于作者
