链家广州二手房的数据与分析——爬取数据
1. [链家广州二手房的数据与分析——数据分析1](https://www.cnblogs.com/yukiwu/p/11271515.html)2. [链家广州二手房的数据与分析——数据分析2](https://www.cnblogs.com/yukiwu/p/11333349.html)
发布日期:2021-05-09 09:08:21
浏览次数:19
分类:博客文章
本文共 1207 字,大约阅读时间需要 4 分钟。
之前在博客分享了利用 R 和 rvest 包爬虫的基础方法。现在就来实战一下:爬取链家网广州 40,000+ 套二手房的数据。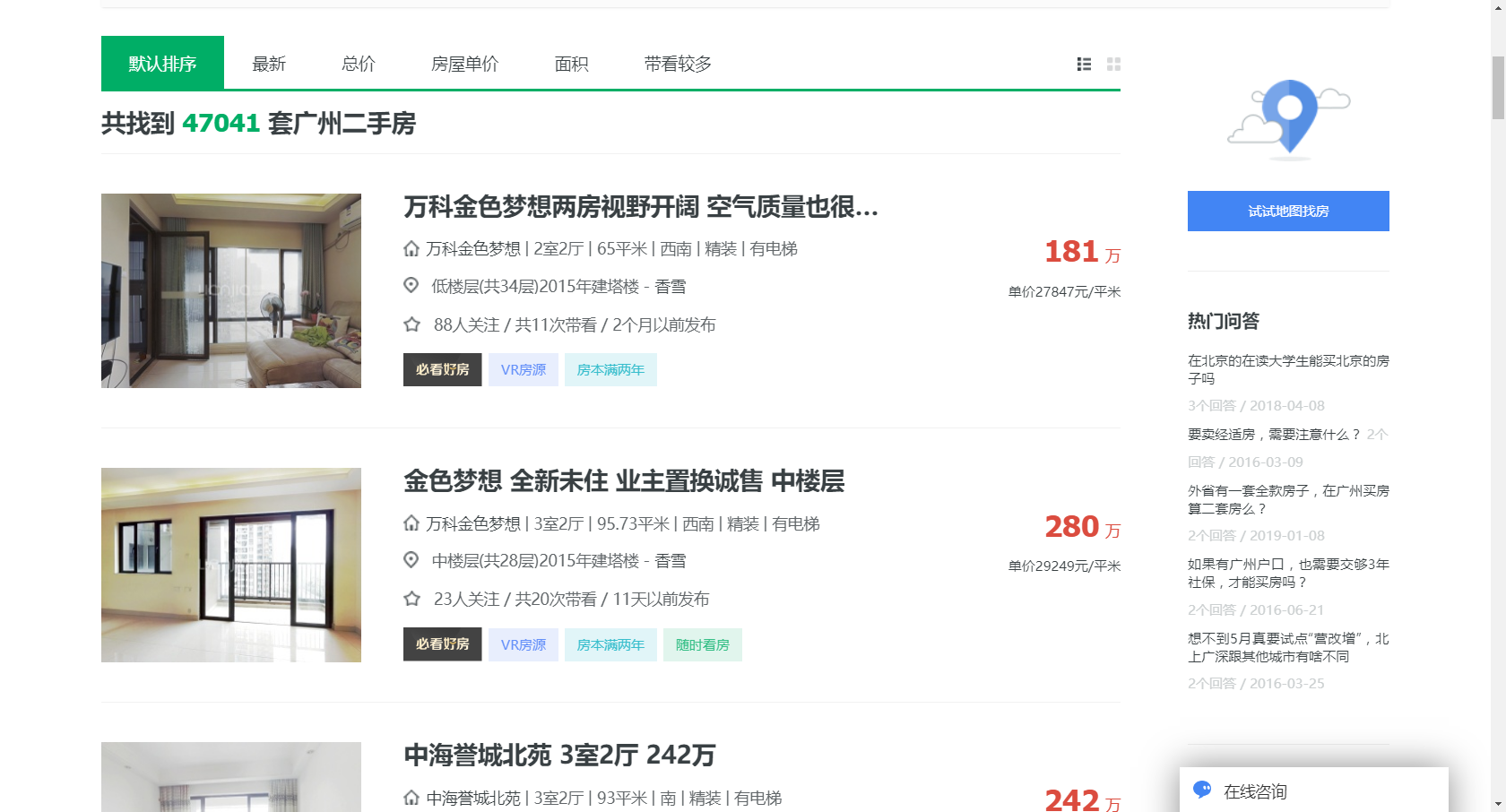之前在 说过的爬虫方法在这篇中就不在赘述了。这里就分享怎么样爬取网站中翻页的数据。
#### >> Web Scraping across Multiple Pages首先观察翻页页面的 url 规律,比如广州链家二手房数据:
第一页:
第二页:
第三页:
......
由此可推断,url 为 "" + 页码
- 假设我们需要爬去第 1 页到第 100 页的房屋总价。那么我们可以先尝试爬取第一页的数据,并封装成一个函数.
getHouseInfo <- function(pageNum, urlWithoutPageNum) { url <- paste0(urlWithoutPageNum, pageNum) webpage <- read_html(url,encoding="UTF-8") total_price_data_html <- html_nodes(webpage,'.totalPrice span') total_price_data <- html_text(total_price_data_html) data.frame(totalprice = total_price_data)} - 然后利用上述的函数循环爬取第 1 页到第 100 页的数据,并将多页的数据合并成一个 data frame
url <- "https://gz.lianjia.com/ershoufang/pg"houseInfo <- data.frame()for (ii in 1:1553){ houseInfo <- rbind(houseInfo, getHouseInfo(ii, url))} #### >> Sample Code 知道如何爬取翻页的数据后我们就可以尝试完整的爬取广州链家网上 4w+ 套二手房的详细信息(包括区域,小区,几室几厅,有无电梯等等)了。
数据量比较大,爬取数据需要一些时间。爬取完毕如果要保存数据需要注意选择适合的编码,不然容易乱码。提供一个可在 Mac Excel 打开的 cvs 格式。
>> 后续分析
1. [链家广州二手房的数据与分析——数据分析1](https://www.cnblogs.com/yukiwu/p/11271515.html)2. [链家广州二手房的数据与分析——数据分析2](https://www.cnblogs.com/yukiwu/p/11333349.html)
发表评论
最新留言
做的很好,不错不错
[***.243.131.199]2025年04月24日 21时14分54秒
关于作者

喝酒易醉,品茶养心,人生如梦,品茶悟道,何以解忧?唯有杜康!
-- 愿君每日到此一游!
推荐文章
openssl服务器证书操作
2019-03-07
expect 模拟交互 ftp 上传文件到指定目录下
2019-03-07
linux系统下双屏显示
2019-03-07
PDF.js —— vue项目中使用pdf.js显示pdf文件(流)
2019-03-07
我用wxPython搭建GUI量化系统之最小架构的运行
2019-03-07
我用wxPython搭建GUI量化系统之Sizer布局管理与页面切换
2019-03-07
我用wxPython搭建GUI量化系统之多只股票走势对比界面
2019-03-07
我用wxPython搭建GUI量化系统之财务选股工具添加日历和排序
2019-03-07
selenium+python之切换窗口
2019-03-07
重载和重写的区别:
2019-03-07
搭建Vue项目步骤
2019-03-07
linux 编译出现的错误
2019-03-07
账号转账演示事务
2019-03-07
idea创建工程时错误提醒的是architectCatalog=internal
2019-03-07
SpringBoot找不到@EnableRety注解
2019-03-07
简易计算器案例
2019-03-07
在Vue中使用样式——使用内联样式
2019-03-07
Explore Optimization
2019-03-07
Kali Linux 内网渗透教程 - ARP欺骗攻击 | 超详细
2019-03-07
白红宇的个人博客 - 记录点点滴滴的事 - 您是第 461204834 位访客