本文共 10116 字,大约阅读时间需要 33 分钟。
自旋锁和排他锁和可重入锁有什么区别
可重入锁外层函数获取锁之后,内层代码仍然可以获取该锁,在同一线程在外层方法获取锁的时候,在进入内层方法会自动获取锁
自旋就是
获取锁的时候,如果锁已经被其它线程获取,那么使用循环的方式不断尝试去获取锁,这样可以减少线程上下文之间的切换
AQS,即AbstractQueuedSynchronizer, 队列同步器,是一个抽象类,它是Java并发用来构建锁和其他同步组件的基础框架。
CAS:
乐观锁思想
比较当前工作内存中的值和主内存中的值,如果这个值是期望的,那么则执行操作! 如果不是就一直循环
缺点:
-
循环会耗时
-
一次性只能保证一个共享变量的原子性
-
ABA问题
ConcurrentHashMap里面是如何用CAS实现加锁
CAS:在判断数组中当前位置为null的时候,使用CAS来把这个新的Node写入数组中对应的位置
了解过什么垃圾回收器
CMS、G1 区别
区别一
内存碎片
CMS收集器是使用“标记-清除”算法进行的垃圾回收,容易产生内存碎片
G1收集器使用的是“标记-压缩”算法,进行了空间整合,降低了内存空间碎片
使用范围不一样
CMS收集器是老年代的收集器,可以配合新生代的Serial和ParNew收集器一起使用
G1收集器收集范围是老年代和新生代。不需要结合其他收集器使用总结GC三种算法
从效率的角度来看
复制算法>标记清除算法>标记压缩算法(时间复杂度)
内存整齐度
复制算法=标记压缩算法>标记清除算法
内存利用率
标记清除算法=标记压缩算法>复制算法
思考一个问题:难道没有最优算法吗?
答:没有,没有最好的算法,只有最合适的算法 ---->GC:分代收集算法
年轻代:
- 存活率低
- 复制算法
老年代:
- 区域大;存活率高
- 标记清除算法(内存碎片不是太多)+标记压缩混合实现
mybatis刚插入一条数据,如何同时获得这条数据的主键ID
可以用通过三个属性来指定,把usegeneratekeys设置为true,keyproperty指定实体类的哪个属性
keycolumn指定自增主键
**9 种动态 SQL 标签:**if、choose、when、otherwise、trim、where、set、foreach、bind
mysql索引:
索引是为了提高查询数据的速度,缺点是索引需要维护,占用一定的存储空间,降低增删改的效率;
索引是一种数据结构,有hash索引和B+树索引,mysql现在默认的数据结构是B+树结构,可以提高sql查询效率
mysql的索引有普通索引、唯一索引、复合索引、主键索引
主键索引和唯一索引的区别: 主键索引的值不能为null 唯一索引可以为null 共同点:值不能重复
什么时候情况需要创建索引呢?
- 表经常进行select操作
- 表的记录很多
- 列名经常在where子句或连接条件中出现
什么时候不要创建索引呢?
- 表经常进行增删改操作
- 表的记录很小
- 列名没有经常作为where子句中或者连接条件中
索引失效:
- 查询条件中带 or
- like查询以%开头
1.有or必全有索引;
2.复合索引未用左列字段; 3.like以%开头; 4.需要类型转换; 5.where中索引列有运算; 6.where中索引列使用了函数; 7.如果mysql觉得全表扫描更快时(数据少);建表的时候需要注意什么?
注意char和varchar的使用,char和varchar的区别是
[外链图片转存失败,源站可能有防盗链机制,建议将图片保存下来直接上传(img-NLRoTiIr-1619535927770)(C:\Users\陈育豪\AppData\Roaming\Typora\typora-user-images\image-20210426204017413.png)]
如果 表经常进行select或操作表的记录很多或列名经常在where子句或连接条件中出现,考虑建立相关的索引
SQL语句优化
1)应尽量避免在 where 子句中使用!=或<>操作符,否则将导致引擎放弃使用索引而进行全表扫描。
2)应尽量避免在 where 子句中对字段进行 null 值判断,否则将导致引擎放弃使用索引而进行全表扫描,如: select id from t where num is null 可以在num上设置默认值0,确保表中num列没有null值,然后这样查询: select id from t where num=0 3)很多时候用 exists 代替 in 是一个好的选择 4)用Where子句替换HAVING 子句 因为HAVING 只会在检索出所有记录之后才对结果集进行过滤缓存淘汰策略 LRU
https://blog.csdn.net/qq_39513430/article/details/106425283
class DLinkedNode { String key; int value; DLinkedNode pre; DLinkedNode post;}public class LRUCache { private Hashtable cache = new Hashtable (); private int count; private int capacity; private DLinkedNode head, tail; public LRUCache(int capacity) { this.count = 0; this.capacity = capacity; head = new DLinkedNode(); head.pre = null; tail = new DLinkedNode(); tail.post = null; head.post = tail; tail.pre = head; } public int get(String key) { DLinkedNode node = cache.get(key); if(node == null){ return -1; // should raise exception here. } // move the accessed node to the head; this.moveToHead(node); return node.value; } public void set(String key, int value) { DLinkedNode node = cache.get(key); if(node == null){ DLinkedNode newNode = new DLinkedNode(); newNode.key = key; newNode.value = value; this.cache.put(key, newNode); this.addNode(newNode); ++count; if(count > capacity){ // pop the tail DLinkedNode tail = this.popTail(); this.cache.remove(tail.key); --count; } }else{ // update the value. node.value = value; this.moveToHead(node); } } /** * Always add the new node right after head; */ private void addNode(DLinkedNode node){ node.pre = head; node.post = head.post; head.post.pre = node; head.post = node; } /** * Remove an existing node from the linked list. */ private void removeNode(DLinkedNode node){ DLinkedNode pre = node.pre; DLinkedNode post = node.post; pre.post = post; post.pre = pre; } /** * Move certain node in between to the head. */ private void moveToHead(DLinkedNode node){ this.removeNode(node); this.addNode(node); } // pop the current tail. private DLinkedNode popTail(){ DLinkedNode res = tail.pre; this.removeNode(res); return res; }} spring mvc讲一下
什么是 SpringMvc?
SpringMvc 是 spring 的一个模块,基于 MVC 的一个框架,无需中间整合层来整合。
Spring MVC运行流程图:
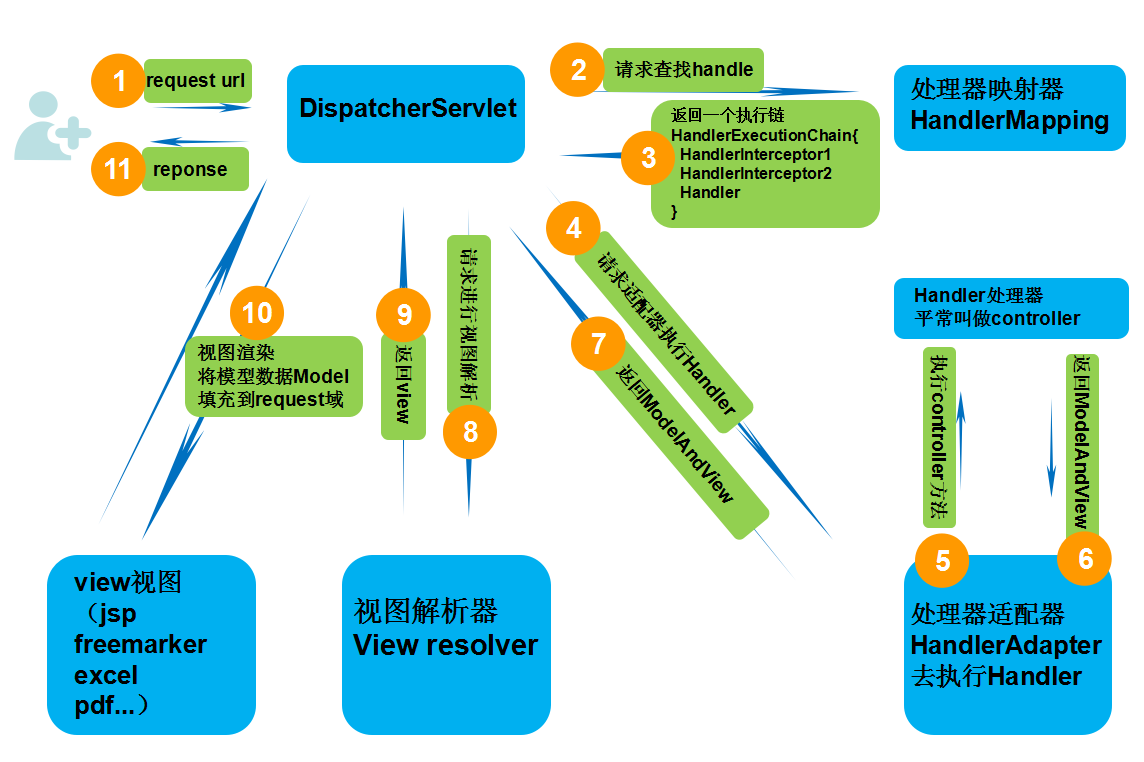
- 第一步:用户发起请求到前端控制器(DispatcherServlet)
- 第二步:前端控制器请求HandlerMapping查找 Handler (可以根据xml配置、注解进行查找)
- 第三步:处理器映射器HandlerMapping向前端控制器返回Handler (HandlerMapping会把请求映射为HandlerExecutionChain对象(包含一个Handler处理器(页面控制器)对象,多个HandlerInterceptor拦截器对象),通过这种策略模式,很容易添加新的映射策略)
- 第四步:前端控制器调用处理器适配器去执行Handler
- 第五步:处理器适配器HandlerAdapter将会根据适配的结果去执行Handler
- 第六步:Handler执行完成给适配器返回ModelAndView
- 第七步:处理器适配器向前端控制器返回ModelAndView (ModelAndView是springmvc框架的一个底层对象,包括 Model和view)
- 第八步:前端控制器请求视图解析器去进行视图解析 (根据逻辑视图名解析成真正的视图(jsp)),通过这种策略很容易更换其他视图技术,只需要更改视图解析器即可
- 第九步:视图解析器向前端控制器返回View
- 第十步:前端控制器进行视图渲染 (视图渲染将模型数据(在ModelAndView对象中)填充到request域)
- 第十一步:前端控制器向用户响应结果
spring mvc 有哪些组件?
Spring MVC的核心组件:
-
DispatcherServlet:中央控制器,把请求给转发到具体的控制类
-
Controller:具体处理请求的控制器
-
HandlerMapping:映射处理器,负责映射中央处理器转发给controller时的映射策略
-
ModelAndView:服务层返回的数据和视图层的封装类
-
ViewResolver:视图解析器,解析具体的视图
-
Interceptors :拦截器,负责拦截我们定义的请求然后做处理工作
Bean 的生命周期
1、实例化一个Bean--也就是我们常说的new;
2、Spring创建对象的过程中,将对象依赖属性通过配置进行注入,不能单独存在,需要在IOC的基础上完成操作--也就是DI注入;
3、如果这个Bean实现了BeanNameAware接口,会调用它实现的setBeanName(String)方法,此处传递的是Spring配置文件中Bean的id值
4、如果这个Bean实现了BeanFactoryAware接口,会调用它实现的setBeanFactory(setBeanFactory(BeanFactory)传递的是Spring工厂自身(可以用这个方式来获取其它Bean);
5、如果这个Bean实现了ApplicationContextAware接口,会调用setApplicationContext(ApplicationContext)方法,传入Spring上下文(可以用这个方式来获取其它Bean,但比4更好,因为ApplicationContext是BeanFactory的子接口,有更多的实现方法);
6、如果这个Bean关联了BeanPostProcessor接口,将会调用postProcessBeforeInitialization(Object obj, String s)方法,BeanPostProcessor经常被用作是Bean内容的更改
7、如果Bean在Spring配置文件中配置了init-method属性会自动调用其配置的初始化方法。
8、如果这个Bean关联了BeanPostProcessor接口,将会调用postProcessAfterInitialization(Object obj, String s)方法、;
9、当Bean不再需要时,会经过清理阶段,如果Bean实现了DisposableBean这个接口,会调用那个其实现的destroy()方法;
10、最后,如果这个Bean的Spring配置中配置了destroy-method属性,会自动调用其配置的销毁方法。
@RequestMapping 的作用是什么?
RequestMapping是一个用来处理请求地址映射的注解,可用于类或方法上。用于类上,表示类中的所有响应请求的方法都是以该地址作为父路径。
value, method:
- value:指定请求的实际地址,指定的地址可以是URI Template 模式(后面将会说明);
- method:指定请求的method类型, GET、POST、PUT、DELETE等;
redis讲一下你所有了解的
redis是C语言编写的,单线程
数据类型:String、list、set(无序集合)、hash、zset(有序集合)
Redis 的持久化机制是什么?分别说下他们的区别
支持AOF和RDB持久化
AOF(append only file) 以日志的形式记录服务器所处理的每一个写、删除操作,查询操作不会记录,以文本的方式记录 支持秒级持久化、兼容性好,对于相同数量的数据集而言,AOF文件通常要大于RDB文件,所以恢复比RDB慢 RDB(redis database) 在指定的时间间隔内将内存中的数据集以快照的形式写入磁盘,可以指定时间归档数据,但不能做到实时持久化 ⽂件紧凑,体积小,对于灾难恢复而言,RDB是非常不错的选择,相比于AOF机制,如果数据集很大,RDB 在恢复大数据集时的速度比 AOF 的恢复速度要快同一个类的不同方法,A方法没有@Transactional,B方法有@Transactional,A调用B方法,事务不起作用
原理解析:
spring 在扫描bean的时候会扫描方法上是否包含@Transactional注解,如果包含,spring会为这个bean动态地生成一个子类(即代理类,proxy),代理类是继承原来那个bean的。 此时,当这个有注解的方法被调用的时候,实际上是由代理类来调用的,代理类在调用之前就会启动事务。然而,如果这个有注解的方法是被同一个类中的其他方法调用的,那么该方法的调用并没有通过代理类,而是直接通过原来的那个bean,所以就不会启动事务。TCP和HTTP的区别是什么?
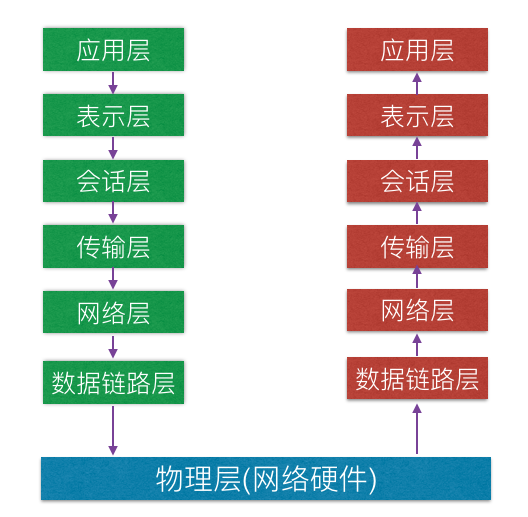
网络七层模型
tcp四层模型
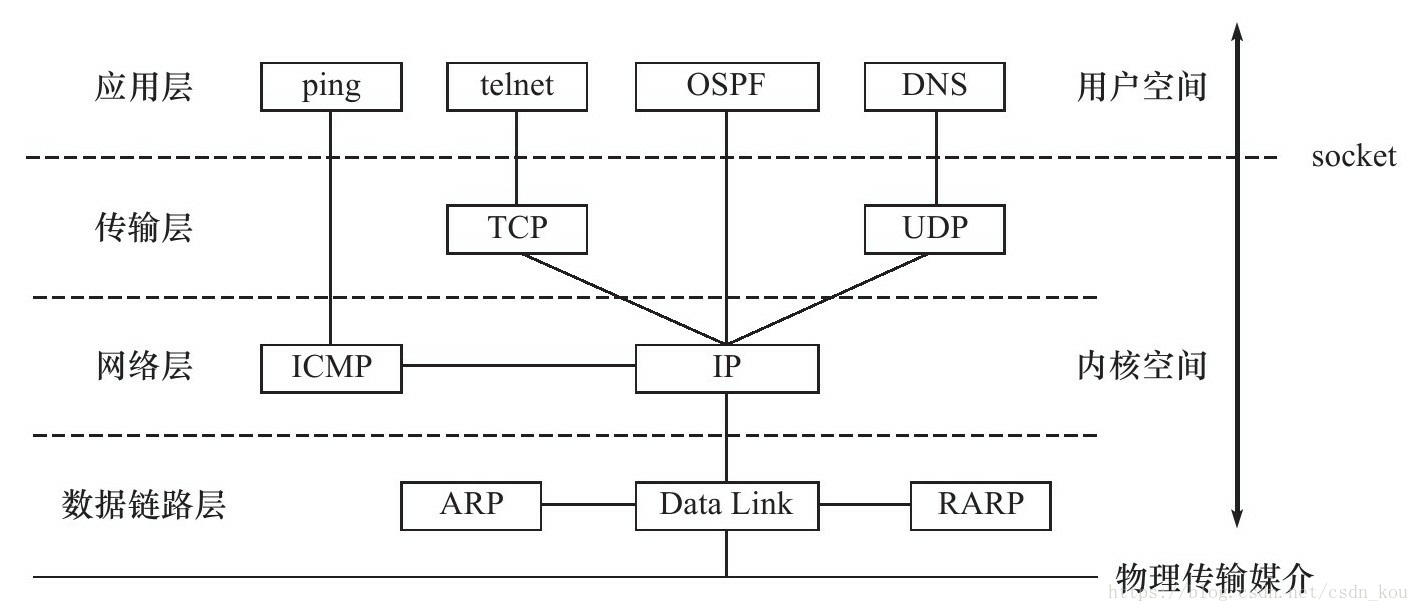
大致讲了下网络七层模型和tcp四层模型,http是在应用层,是应用层协议,tcp是在传输层,是传输层协议,http协议依赖于tcp协议,就讲了下http网址访问的大致过程
TCP协议是传输层协议,主要解决数据如何在网络中传输,而HTTP是应用层协议,主要解决如何包装数据。TCP/IP和HTTP协议的关系,,我们在传输数据时,可以只使用(传输层)TCP/IP协议,但是那样的话,如果没有应用层,便无法识别数据内容,如果想要使传输的数据有意义,则必须使用到应用层协议,这时候应用层协议http就产生了
讲一下tcp三次握手,说一下tcp和udp的区别?
三次握手,四次挥手:
1.客户端发送syn0给服务器
2.服务器收到syn0,回复syn1,ack(syn0+1) 3.客户端收到syn1,回复ack(syn1+1) 四次挥手(这里以客户端主动断开为例) 1.客户端发送fin 2.服务端收到fin,回复ack,然后服务器去处理其他事 3.服务器事情处理完,回复fin 4.客户端收到之后回复acktcp和udp的区别:
1.基于连接与无连接; 2.对系统资源的要求(TCP较多,UDP少); 3.UDP程序结构较简单; 4.流模式与数据报模式 ; 5.TCP保证数据正确性,UDP可能丢包,TCP保证数据顺序,UDP不保证。讲一下你对http和https的认识
http是超文本网络传输协议,信息是明文加密,HTTPS 协议是由 SSL+HTTP 协议构建的可进行加密传输、身份认证的网络协议,比 HTTP 协议安全,http的网络端口号是80,https是443
线程池场景,说下线程池几个参数的意义
corePoolSize 线程池核心线程大小、
maximumPoolSize 线程池最大线程数量、 keepAliveTime 空闲线程存活时间、 workQueue 工作队列、线程池在一开始创建的时候就会先创建5个空闲线程在里面,然后有任务用到线程就会从这5个里面取,用完以后会放回去,如果5个线程都在用,那么来的任务会加到阻塞队列中
说一下redis的了解
redis是用C写的
从关系型数据库和非关系数据库的角度看,他是非关系型数据库
从功能上来看,他是用于作为缓存 根据key进行查询,查询数据更快
redis的数据类型有 string、list、set、hash、zset
redis会产生
缓存穿透:
http是无状态的,怎么知道是哪个用户访问
在这里我的项目是采用jwt来生成一个token,用于记录是哪个用户访问,然后返回给客户端,存储在浏览器中。
为什么不用cookie呢,由于cookie会保存在服务端,从而浪费服务端的资源,所以采用jwt生成一个token返回给客户端然后存储在浏览器是一个比较好的方案。
springAOP原理?
JDK动态代理为什么要提供接口?
1、生成的代理类继承了Proxy,由于java是单继承,所以只能实现接口,通过接口实现
2、从代理模式的设计来说,充分利用了java的多态特性,也符合基于接口编码的规范
JVM卸载类的条件
-
该类所有的实例已经被回收
-
加载该类的ClassLoder已经被回收
-
该类对应的java.lang.Class对象没有任何地方被引用
自己怎么把java程序玩崩溃?
不断new对象让虚拟机发生OOM
最近在学啥?
我最近学了AlibabaCloud+SpringCloud,现在对于微服务有一定的了解
【面试题】掌握微服务你必须知道的CAP理论
-
可能会有疑惑,可以看多几遍
-
CAP定理: 指的是在一个分布式系统中,Consistency(一致性)、 Availability(可用性)、Partition tolerance(分区容错性),三者不可同时获得
- 一致性(C):所有节点都可以访问到最新的数据
- 可用性(A):每个请求都是可以得到响应的,不管请求是成功还是失败
- 分区容错性(P):除了全部整体网络故障,其他故障都不能导致整个系统不可用
-
CAP理论就是说在分布式存储系统中,最多只能实现上面的两点。而由于当前的网络硬件肯定会出现延迟丢包等问题,所以分区容忍性是我们必须需要实现的。所以我们只能在一致性和可用性之间进行权衡
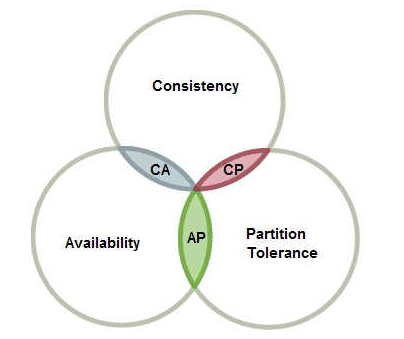
CA: 如果不要求P(不允许分区),则C(强一致性)和A(可用性)是可以保证的。但放弃P的同时也就意味着放弃了系统的扩展性,也就是分布式节点受限,没办法部署子节点,这是违背分布式系统设计的初衷的CP: 如果不要求A(可用),每个请求都需要在服务器之间保持强一致,而P(分区)会导致同步时间无限延长(也就是等待数据同步完才能正常访问服务),一旦发生网络故障或者消息丢失等情况,就要牺牲用户的体验,等待所有数据全部一致了之后再让用户访问系统AP:要高可用并允许分区,则需放弃一致性。一旦分区发生,节点之间可能会失去联系,为了高可用,每个节点只能用本地数据提供服务,而这样会导致全局数据的不一致性。
【面试题】CAP里面下的注册中心选择思考
简介:讲解常见的分布式核心CAP理论介绍
- 常见注册中心:zk、eureka、nacos
- 那你应该怎么选择
| Nacos | Eureka | Consul | Zookeeper | |
|---|---|---|---|---|
| 一致性协议 | CP+AP | AP | CP | CP |
| 健康检查 | TCP/HTTP/MYSQL/Client Beat | 心跳 | TCP/HTTP/gRPC/Cmd | Keep Alive |
| 雪崩保护 | 有 | 有 | 无 | 无 |
| 访问协议 | HTTP/DNS | HTTP | HTTP/DNS | TCP |
| SpringCloud集成 | 支持 | 支持 | 支持 | 支持 |
-
Zookeeper:CP设计,保证了一致性,集群搭建的时候,某个节点失效,则会进行选举行的leader,或者半数以上节点不可用,则无法提供服务,因此可用性没法满足
-
Eureka:AP原则,无主从节点,一个节点挂了,自动切换其他节点可以使用,去中心化
-
结论:
- 分布式系统中P,肯定要满足,所以只能在CA中二选一
- 没有最好的选择,最好的选择是根据业务场景来进行架构设计
- 如果要求一致性,则选择zookeeper/Nacos,如金融行业 CP
- 如果要求可用性,则Eureka/Nacos,如电商系统 AP
- CP : 适合支付、交易类,要求数据强一致性,宁可业务不可用,也不能出现脏数据
- AP: 互联网业务,比如信息流架构,不要求数据强一致,更想要服务可用
【面试题】一致性和可用性的权衡结果 BASE理论
简介:讲解分布式CAP的权衡结果 BASE理论
- 什么是Base理论
CAP 中的一致性和可用性进行一个权衡的结果,核心思想就是:我们无法做到强一致,但每个应用都可以根据自身的业务特点,采用适当的方式来使系统达到最终一致性, 来自 ebay 的架构师提出
-
Basically Available(基本可用)
- 假设系统,出现了不可预知的故障,但还是能用, 可能会有性能或者功能上的影响
-
Soft state(软状态)
- 允许系统中的数据存在中间状态,并认为该状态不影响系统的整体可用性,即允许系统在多个不同节点的数据副本存在数据延时
-
Eventually consistent(最终一致性)
- 系统能够保证在没有其他新的更新操作的情况下,数据最终一定能够达到一致的状态,因此所有客户端对系统的数据访问最终都能够获取到最新的值
jar冲突:
我了解jar包冲突,比如 A依赖 D1 B依赖D2 D1和D2是同一个jar包的不同版本,此时就产生了jar冲突
Maven默认处理策略是:
最短路径优先
如果路径相同,则选择最先声明
我们也可以手动去掉,用标签
JAVA锁了解吗?有什么应用场景
发表评论
最新留言
关于作者
