本文共 9534 字,大约阅读时间需要 31 分钟。
原文地址:
1. 概述 
Redis有5个基本数据结构,string、list、hash、set和zset。它们是日常开发中使用频率非常高应用最为广泛的数据结构,把这5个数据结构都吃透了,你就掌握了Redis应用知识的一半了。
2. string

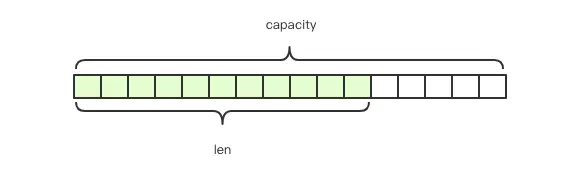 Redis的字符串是动态字符串,是可以修改的字符串,内部结构实现上类似于Java的ArrayList,采用预分配冗余空间的方式来减少内存的频繁分配,如图中所示,内部为当前字符串实际分配的空间capacity一般要高于实际字符串长度len。当字符串长度小于1M时,扩容都是加倍现有的空间,如果超过1M,扩容时一次只会多扩1M的空间。需要注意的是字符串最大长度为512M。
Redis的字符串是动态字符串,是可以修改的字符串,内部结构实现上类似于Java的ArrayList,采用预分配冗余空间的方式来减少内存的频繁分配,如图中所示,内部为当前字符串实际分配的空间capacity一般要高于实际字符串长度len。当字符串长度小于1M时,扩容都是加倍现有的空间,如果超过1M,扩容时一次只会多扩1M的空间。需要注意的是字符串最大长度为512M。 初始化字符串 需要提供「变量名称」和「变量的内容」
> set ireader beijing.zhangyue.keji.gufen.youxian.gongsiOK
获取字符串的内容 提供「变量名称」
> get ireader"beijing.zhangyue.keji.gufen.youxian.gongsi"
获取字符串的长度 提供「变量名称」
> strlen ireader(integer) 42
获取子串 提供「变量名称」以及开始和结束位置[start, end]
> getrange ireader 28 34"youxian"
覆盖子串 提供「变量名称」以及开始位置和目标子串
> setrange ireader 28 wooxian(integer) 42 # 返回长度> get ireader"beijing.zhangyue.keji.gufen.wooxian.gongsi"
追加子串
> append ireader .hao(integer) 46 # 返回长度> get ireader"beijing.zhangyue.keji.gufen.wooxian.gongsi.hao"
遗憾的是字符串没有提供字串插入方法和子串删除方法。
计数器 如果字符串的内容是一个整数,那么还可以将字符串当成计数器来使用。
> set ireader 42OK> get ireader"42"> incrby ireader 100(integer) 142> get ireader"142"> decrby ireader 100(integer) 42> get ireader"42"> incr ireader # 等价于incrby ireader 1(integer) 43> decr ireader # 等价于decrby ireader 1(integer) 42
计数器是有范围的,它不能超过Long.Max,不能低于Long.MIN
> set ireader 9223372036854775807OK> incr ireader(error) ERR increment or decrement would overflow> set ireader -9223372036854775808OK> decr ireader(error) ERR increment or decrement would overflow
过期和删除 字符串可以使用del指令进行主动删除,可以使用expire指令设置过期时间,到点会自动删除,这属于被动删除。可以使用ttl指令获取字符串的寿命。
> expire ireader 60(integer) 1 # 1表示设置成功,0表示变量ireader不存在> ttl ireader(integer) 50 # 还有50秒的寿命,返回-2表示变量不存在,-1表示没有设置过期时间> del ireader(integer) 1 # 删除成功返回1> get ireader(nil) # 变量ireader没有了
3. list

负下标 链表元素的位置使用自然数0,1,2,…n-1表示,还可以使用负数-1,-2,…-n来表示,-1表示「倒数第一」,-2表示「倒数第二」,那么-n就表示第一个元素,对应的下标为0。
队列/堆栈 链表可以从表头和表尾追加和移除元素,结合使用rpush/rpop/lpush/lpop四条指令,可以将链表作为队列或堆栈使用,左向右向进行都可以
# 右进左出> rpush ireader go(integer) 1> rpush ireader java python(integer) 3> lpop ireader"go"> lpop ireader"java"> lpop ireader"python"# 左进右出> lpush ireader go java python(integer) 3> rpop ireader"go"...# 右进右出> rpush ireader go java python(integer) 3> rpop ireader "python"...# 左进左出> lpush ireader go java python(integer) 3> lpop ireader"python"...
在日常应用中,列表常用来作为异步队列来使用。
长度 使用llen指令获取链表长度
> rpush ireader go java python(integer) 3> llen ireader(integer) 3
随机读 可以使用lindex指令访问指定位置的元素,使用lrange指令来获取链表子元素列表,提供start和end下标参数
> rpush ireader go java python(integer) 3> lindex ireader 1"java"> lrange ireader 0 21) "go"2) "java"3) "python"> lrange ireader 0 -1 # -1表示倒数第一1) "go"2) "java"3) "python"
使用lrange获取全部元素时,需要提供end_index,如果没有负下标,就需要首先通过llen指令获取长度,才可以得出end_index的值,有了负下标,使用-1代替end_index就可以达到相同的效果。
修改元素 使用lset指令在指定位置修改元素。
> rpush ireader go java python(integer) 3> lset ireader 1 javascriptOK> lrange ireader 0 -11) "go"2) "javascript"3) "python"
插入元素 使用linsert指令在列表的中间位置插入元素,有经验的程序员都知道在插入元素时,我们经常搞不清楚是在指定位置的前面插入还是后面插入,所以antirez在linsert指令里增加了方向参数before/after来显示指示前置和后置插入。不过让人意想不到的是linsert指令并不是通过指定位置来插入,而是通过指定具体的值。这是因为在分布式环境下,列表的元素总是频繁变动的,意味着上一时刻计算的元素下标在下一时刻可能就不是你所期望的下标了。
> rpush ireader go java python(integer) 3> linsert ireader before java ruby(integer) 4> lrange ireader 0 -11) "go"2) "ruby"3) "java"4) "python"
到目前位置,我还没有在实际应用中发现插入指定的应用场景。
删除元素 列表的删除操作也不是通过指定下标来确定元素的,你需要指定删除的最大个数以及元素的值
> rpush ireader go java python(integer) 3> lrem ireader 1 java(integer) 1> lrange ireader 0 -11) "go"2) "python"
定长列表 在实际应用场景中,我们有时候会遇到「定长列表」的需求。比如要以走马灯的形式实时显示中奖用户名列表,因为中奖用户实在太多,能显示的数量一般不超过100条,那么这里就会使用到定长列表。维持定长列表的指令是ltrim,需要提供两个参数start和end,表示需要保留列表的下标范围,范围之外的所有元素都将被移除。
> rpush ireader go java python javascript ruby erlang rust cpp(integer) 8> ltrim ireader -3 -1OK> lrange ireader 0 -11) "erlang"2) "rust"3) "cpp"
如果指定参数的end对应的真实下标小于start,其效果等价于del指令,因为这样的参数表示需要需要保留列表元素的下标范围为空。
快速列表
 如果再深入一点,你会发现Redis底层存储的还不是一个简单的linkedlist,而是称之为快速链表quicklist的一个结构。首先在列表元素较少的情况下会使用一块连续的内存存储,这个结构是ziplist,也即是压缩列表。它将所有的元素紧挨着一起存储,分配的是一块连续的内存。当数据量比较多的时候才会改成quicklist。因为普通的链表需要的附加指针空间太大,会比较浪费空间。比如这个列表里存的只是int类型的数据,结构上还需要两个额外的指针prev和next。所以Redis将链表和ziplist结合起来组成了quicklist。也就是将多个ziplist使用双向指针串起来使用。这样既满足了快速的插入删除性能,又不会出现太大的空间冗余。
如果再深入一点,你会发现Redis底层存储的还不是一个简单的linkedlist,而是称之为快速链表quicklist的一个结构。首先在列表元素较少的情况下会使用一块连续的内存存储,这个结构是ziplist,也即是压缩列表。它将所有的元素紧挨着一起存储,分配的是一块连续的内存。当数据量比较多的时候才会改成quicklist。因为普通的链表需要的附加指针空间太大,会比较浪费空间。比如这个列表里存的只是int类型的数据,结构上还需要两个额外的指针prev和next。所以Redis将链表和ziplist结合起来组成了quicklist。也就是将多个ziplist使用双向指针串起来使用。这样既满足了快速的插入删除性能,又不会出现太大的空间冗余。 4. hash


> hset ireader go fast(integer) 1> hmset ireader java fast python slowOK
获取元素 可以通过hget定位具体key对应的value,可以通过hmget获取多个key对应的value,可以使用hgetall获取所有的键值对,可以使用hkeys和hvals分别获取所有的key列表和value列表。这些操作和Java语言的Map接口是类似的。
> hmset ireader go fast java fast python slowOK> hget ireader go"fast"> hmget ireader go python1) "fast"2) "slow"> hgetall ireader1) "go"2) "fast"3) "java"4) "fast"5) "python"6) "slow"> hkeys ireader1) "go"2) "java"3) "python"> hvals ireader1) "fast"2) "fast"3) "slow"
删除元素 可以使用hdel删除指定key,hdel支持同时删除多个key
> hmset ireader go fast java fast python slowOK> hdel ireader go(integer) 1> hdel ireader java python(integer) 2
判断元素是否存在 通常我们使用hget获得key对应的value是否为空就直到对应的元素是否存在了,不过如果value的字符串长度特别大,通过这种方式来判断元素存在与否就略显浪费,这时可以使用hexists指令。
> hmset ireader go fast java fast python slowOK> hexists ireader go(integer) 1
计数器 hash结构还可以当成计数器来使用,对于内部的每一个key都可以作为独立的计数器。如果value值不是整数,调用hincrby指令会出错。
> hincrby ireader go 1(integer) 1> hincrby ireader python 4(integer) 4> hincrby ireader java 4(integer) 4> hgetall ireader1) "go"2) "1"3) "python"4) "4"5) "java"6) "4"> hset ireader rust good(integer) 1> hincrby ireader rust 1(error) ERR hash value is not an integer
扩容 当hash内部的元素比较拥挤时(hash碰撞比较频繁),就需要进行扩容。扩容需要申请新的两倍大小的数组,然后将所有的键值对重新分配到新的数组下标对应的链表中(rehash)。如果hash结构很大,比如有上百万个键值对,那么一次完整rehash的过程就会耗时很长。这对于单线程的Redis里来说有点压力山大。所以Redis采用了渐进式rehash的方案。它会同时保留两个新旧hash结构,在后续的定时任务以及hash结构的读写指令中将旧结构的元素逐渐迁移到新的结构中。这样就可以避免因扩容导致的线程卡顿现象。
缩容 Redis的hash结构不但有扩容还有缩容,从这一点出发,它要比Java的HashMap要厉害一些,Java的HashMap只有扩容。缩容的原理和扩容是一致的,只不过新的数组大小要比旧数组小一倍。
5. set
Java程序员都知道HashSet的内部实现使用的是HashMap,只不过所有的value都指向同一个对象。Redis的set结构也是一样,它的内部也使用hash结构,所有的value都指向同一个内部值。
增加元素 可以一次增加多个元素
> sadd ireader go java python(integer) 3
读取元素 使用smembers列出所有元素,使用scard获取集合长度,使用srandmember获取随机count个元素,如果不提供count参数,默认为1
> sadd ireader go java python(integer) 3> smembers ireader1) "java"2) "python"3) "go"> scard ireader(integer) 3> srandmember ireader"java"
删除元素 使用srem删除一到多个元素,使用spop删除随机一个元素
> sadd ireader go java python rust erlang(integer) 5> srem ireader go java(integer) 2> spop ireader"erlang"
判断元素是否存在 使用sismember指令,只能接收单个元素
> sadd ireader go java python rust erlang(integer) 5> sismember ireader rust(integer) 1> sismember ireader javascript(integer) 0
6. sortedset

zset底层实现使用了两个数据结构,第一个是hash,第二个是跳跃列表,hash的作用就是关联元素value和权重score,保障元素value的唯一性,可以通过元素value找到相应的score值。跳跃列表的目的在于给元素value排序,根据score的范围获取元素列表
增加元素 通过zadd指令可以增加一到多个value/score对,score放在前面
> zadd ireader 4.0 python(integer) 1> zadd ireader 4.0 java 1.0 go(integer) 2
长度 通过指令zcard可以得到zset的元素个数
> zcard ireader(integer) 3
删除元素 通过指令zrem可以删除zset中的元素,可以一次删除多个
> zrem ireader go python(integer) 2
计数器 同hash结构一样,zset也可以作为计数器使用。
> zadd ireader 4.0 python 4.0 java 1.0 go(integer) 3> zincrby ireader 1.0 python"5"
获取排名和分数 通过zscore指令获取指定元素的权重,通过zrank指令获取指定元素的正向排名,通过zrevrank指令获取指定元素的反向排名[倒数第一名]。正向是由小到大,负向是由大到小。
> zscore ireader python"5"> zrank ireader go # 分数低的排名考前,rank值小(integer) 0> zrank ireader java(integer) 1> zrank ireader python(integer) 2> zrevrank ireader python(integer) 0
根据排名范围获取元素列表 通过zrange指令指定排名范围参数获取对应的元素列表,携带withscores参数可以一并获取元素的权重。通过zrevrange指令按负向排名获取元素列表[倒数]。正向是由小到大,负向是由大到小。
> zrange ireader 0 -1 # 获取所有元素1) "go"2) "java"3) "python"> zrange ireader 0 -1 withscores1) "go"2) "1"3) "java"4) "4"5) "python"6) "5"> zrevrange ireader 0 -1 withscores1) "python"2) "5"3) "java"4) "4"5) "go"6) "1"
根据score范围获取列表 通过zrangebyscore指令指定score范围获取对应的元素列表。通过zrevrangebyscore指令获取倒排元素列表。正向是由小到大,负向是由大到小。参数-inf表示负无穷,+inf表示正无穷。
> zrangebyscore ireader 0 51) "go"2) "java"3) "python"> zrangebyscore ireader -inf +inf withscores1) "go"2) "1"3) "java"4) "4"5) "python"6) "5"> zrevrangebyscore ireader +inf -inf withscores # 注意正负反过来了1) "python"2) "5"3) "java"4) "4"5) "go"6) "1"
根据范围移除元素列表 可以通过排名范围,也可以通过score范围来一次性移除多个元素
> zremrangebyrank ireader 0 1(integer) 2 # 删掉了2个元素> zadd ireader 4.0 java 1.0 go(integer) 2> zremrangebyscore ireader -inf 4(integer) 2> zrange ireader 0 -11) "python"
跳跃列表 zset内部的排序功能是通过「跳跃列表」数据结构来实现的,它的结构非常特殊,也比较复杂。这一块的内容深度读者要有心理准备。
因为zset要支持随机的插入和删除,所以它不好使用数组来表示。我们先看一个普通的链表结构。

想想一个创业公司,刚开始只有几个人,团队成员之间人人平等,都是联合创始人。随着公司的成长,人数渐渐变多,团队沟通成本随之增加。这时候就会引入组长制,对团队进行划分。每个团队会有一个组长。开会的时候分团队进行,多个组长之间还会有自己的会议安排。公司规模进一步扩展,需要再增加一个层级——部门,每个部门会从组长列表中推选出一个代表来作为部长。部长们之间还会有自己的高层会议安排。
跳跃列表就是类似于这种层级制,最下面一层所有的元素都会串起来。然后每隔几个元素挑选出一个代表来,再将这几个代表使用另外一级指针串起来。然后在这些代表里再挑出二级代表,再串起来。最终就形成了金字塔结构。
想想你老家在世界地图中的位置:亚洲–>中国->安徽省->安庆市->枞阳县->汤沟镇->田间村->xxxx号,也是这样一个类似的结构。

发表评论
最新留言
关于作者
