Python机器学习算法之线性回归算法
发布日期:2021-05-08 16:13:56
浏览次数:21
分类:精选文章
本文共 2485 字,大约阅读时间需要 8 分钟。
线性回归
1.算法概述
- 回归就是用一条曲线对数据点进行拟合,该曲线称为最佳拟合曲线,这个拟合过程称为回归。当该曲线是一条直线时,就是线性回归。
- 线性回归(Linear Regression)是利用数理统计中回归分析,来确定两种或两种以上变量间相互依赖关系的一种统计分析方法。
- 线性回归一般用来做连续值的预测,预测的结果是一个连续值。
- 线性回归在训练学习样本时,不仅需要提供特征向量X,还需要提供样本的实际结果(标记label),因此线性回归模型属于监督学习里的回归模型。
2.算法步骤

- 加载数据集
- 数据预处理
- 建立线性回归模型
- 极小化损失函数
- 参数求解
- 模型检验
- 经济预测
3.梯度下降法

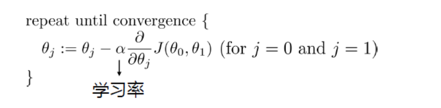
4.最小二乘法

5.算法实现
-
自定义实现import numpy as npimport matplotlib.pyplot as pltfrom scipy import stats# 构造训练数据x = np.arange(0., 10., 0.2)m = len(x)x0 = np.full(m, 1.0)input_data = np.vstack([x0, x]).Ttarget_data = 2 * x + 5 + np.random.randn(m)# 终止条件loop_max = 10000 # 最大迭代次数epsilon = 1e-3 # 收敛条件最小值# 初始化权值np.random.seed(0)theta = np.random.randn(2)alpha = 0.001 # 步长diff = 0.error = np.zeros(2)count = 0 # 循环次数finish = 0 # 终止标志# 迭代while count < loop_max: count += 1 # 在标准梯度下降中,权值更新的每一步对多个样例求和,需要更多的计算 sum_m = np.zeros(2) for i in range(m): dif = (np.dot(theta, input_data[i]) - target_data[i]) * input_data[i] # 当alpha取值过大时,sum_m会在迭代过程中会溢出 sum_m = sum_m + dif # 注意步长alpha的取值,过大会导致振荡 theta = theta - alpha * sum_m # 判断是否已收敛 if np.linalg.norm(theta - error) < epsilon: finish = 1 break else: error = theta print('迭代次数 = %d' % count, '\t w:', theta)print('迭代次数 = %d' % count, '\t w:', theta)# 用scipy线性回归进行检查slope, intercept, r_value, p_value, slope_std_error = stats.linregress(x, target_data)print('截距 = %s 斜率 = %s' % (intercept, slope))# 用plot进行展示plt.plot(x, target_data, 'b*')plt.plot(x, theta[1] * x + theta[0], 'r')plt.xlabel("x")plt.ylabel("y")plt.show() -
利用Sklearn库实现import pandas as pdimport numpy as npimport matplotlib.pyplot as pltfrom sklearn import datasetsfrom sklearn.linear_model import LinearRegressionboston_dataset = datasets.load_boston()data = pd.DataFrame(boston_dataset.data)data.columns = boston_dataset.feature_namesdata['PRICE'] = boston_dataset.target# 取出房间数和房价并转化成矩阵形式x = data.loc[:, 'RM'].as_matrix(columns=None)y = data.loc[:, 'PRICE'].as_matrix(columns=None)# 进行矩阵的转置x = np.array([x]).Ty = np.array([y]).T# 训练线性模型l = LinearRegression()l.fit(x, y)plt.rcParams['font.sans-serif'] = ['SimHei']plt.rcParams['axes.unicode_minus'] = Falseplt.scatter(x, y, s=10, alpha=0.5, c='green')plt.plot(x, l.predict(x), c='blue', linewidth='1')plt.xlabel("房间数(Number)")plt.ylabel("房价(Price)")plt.show()
6.算法优化
当数据间存在线性关系时,用普通的最小二乘法建模得到的结果误差会很大,甚至会出现和实际相悖的情况,在这种情况下,普通最小二乘法是失效的。而化学家 S. Wold于1983年提出的偏最小二乘法在某种程度上改善了普通最小二乘法对变量间存在线性关系时建模的弊端。
发表评论
最新留言
表示我来过!
[***.240.166.169]2025年04月08日 04时49分47秒
关于作者

喝酒易醉,品茶养心,人生如梦,品茶悟道,何以解忧?唯有杜康!
-- 愿君每日到此一游!
推荐文章
基础练习 十六进制转八进制(模拟)
2019-03-06
L - Large Division (大数, 同余)
2019-03-06
39. Combination Sum
2019-03-06
41. First Missing Positive
2019-03-06
80. Remove Duplicates from Sorted Array II
2019-03-06
83. Remove Duplicates from Sorted List
2019-03-06
410. Split Array Largest Sum
2019-03-06
开源项目在闲鱼、b 站上被倒卖?这是什么骚操作?
2019-03-06
Vue3发布半年我不学,摸鱼爽歪歪,哎~就是玩儿
2019-03-06
《实战java高并发程序设计》源码整理及读书笔记
2019-03-06
Java开源博客My-Blog(SpringBoot+Docker)系列文章
2019-03-06
程序员视角:鹿晗公布恋情是如何把微博搞炸的?
2019-03-06
【JavaScript】动态原型模式创建对象 ||为何不能用字面量创建原型对象?
2019-03-06
Linux应用-线程操作
2019-03-06
多态体验,和探索爷爷类指针的多态性
2019-03-06
系统编程-进程间通信-无名管道
2019-03-06
记2020年初对SimpleGUI源码的阅读成果
2019-03-06
C语言实现面向对象方法学的GLib、GObject-初体验
2019-03-06
白红宇的个人博客 - 记录点点滴滴的事 - 您是第 459584302 位访客