本文共 5614 字,大约阅读时间需要 18 分钟。
NoSQL基础
1.NoSQL的兴起缘由
- 关系数据库已经无法满足Web2.0的需求
- 关系数据库无法满足海量数据的管理需求
- 关系数据库无法满足数据高并发的需求
- 关系数据库无法满足高可扩展性和高可用性的需求
- 关系数据库已经无法满足Web2.0的特性
- Web2.0网站系统通常不要求严格的数据库事务
- Web2.0并不要求严格的读写实时性
- Web2.0通常不包含大量复杂的SQL查询
- Mysql集群不能解决问题
复杂性问题:部署、管理、配置很复杂数据库复制问题:MySQL主备之间采用复制方式,只能是异步复制,当主库压力较大时可能产生较大延迟,主备切换可能会丢失最后一部分更新事务,这时往往需要人工介入,备份和恢复不方便扩容问题:如果系统压力过大需要增加新的机器,这个过程涉及数据重新划分,整个过程比较复杂,且容易出错动态数据迁移问题:如果某个数据库组压力过大,需要将其中部分数据迁移出去,迁移过程需要总控节点整体协调,以及数据库节点的配合。这个过程很难做到自动化
- "One size fits all"模式很难适用于截然不同的业务场景
- 关系模型作为统一的数据模型既被用于数据分析,也被用于在线业务。但这两者一个强调高吞吐,一个强调低延时,已经演化出完全不同的架构,用同一套模型来抽象显然是不合适的。
- 而MongoDB、Redis等都是针对在线业务对数据进行分析的,两者都抛弃了关系模型,比较适合这种场景。
2.NoSQL的基础特性
-
易扩展
NoSQL数据库种类繁多,但是一个共同的特点都是去掉关系数据库的关系型特性。数据之间无关系,这样就非常容易扩展。无形之间,在架构的层面上带来了可扩展的能力。
-
大数据量高性能
NoSQL数据库都具有非常高的读写性能,尤其在大数据量下,同样表现优秀。这得益于它的无关系性,数据库的结构简单。一般MySQL使用Query Cache。NoSQL的Cache是记录级的,是一种细粒度的Cache,所以NoSQL在这个层面上来说性能就要高很多。
-
灵活的数据模型
NoSQL无须事先为要存储的数据建立字段,随时可以存储自定义的数据格式。而在关系数据库里,增删字段是一件非常麻烦的事情。如果是非常大数据量的表,增加字段简直就是——个噩梦。这点在大数据量的Web 2.0时代尤其明显。
-
高可用
NoSQL在不太影响性能的情况,就可以方便地实现高可用的架构。比如Cassandra、HBase模型,通过复制模型也能实现高可用。
3.NoSQL的适用场景
-
数据模型比较简单
-
需要灵活性更强的IT系统
-
对数据库性能要求较高
-
不需要高度的数据一致性
-
对于给定key,比较容易映射复杂值的环境
4.NoSQL数据库与关系型数据库对比
| 比较标准 | RDBMS | NoSQL | 备注 |
|---|---|---|---|
| 数据库原理 | 完全支持 | 部分支持 | RDBMS有关系代数理论作为基础 NoSQL没有统一的理论基础 |
| 数据规模 | 大 | 超大 | RDBMS很难实现横向扩展,纵向扩展的空间也比较有限,性能会随着数据规模的增大而降低。NoSQL可以很容易通过添加更多设备来支持更大规模的数据。 |
| 数据库模式 | 固定 | 灵活 | RDBMS需要定义数据库模式,严格遵守数据定义和相关约束条件。NoSQL不存在数据库模式,可以自由灵活定义并存储各种不同类型的数据。 |
| 查询效率 | 快 | 可以实现高效的简单查询,但是不具备高度结构化查询等特性,复杂查询的性能不尽人意 | RDBMS借助于索引机制可以实现快速查询(包括记录查询和范围查询)。 很多NoSQL数据库没有面向复杂查询的索引,虽然NoSQL可以使用MapReduce来加速查询,但是,在复杂查询方面的性能仍然不如RDBMS。 |
| 一致性 | 强一致性 | 弱一致性 | RDBMS严格遵守事务ACID模型,可以保证事务强一致性。很多NoSQL数据库放松了对事务ACID四性的要求,而是遵守BASE模型,只能保证最终一致性。 |
| 数据完整性 | 容易实现 | 很难实现 | 任何一个RDBMS都可以很容易实现数据完整性,比如通过主键或者非空约束来实现实体完整性,通过主键、外键来实现参照完整性,通过约束或者触发器来实现用户自定义完整性。但是,在NoSQL数据库却无法实现。 |
| 扩展性 | 一般 | 好 | RDBMS很难实现横向扩展,纵向扩展的空间也比较有限。NoSQL在设计之初就充分考虑了横向扩展的需求,可以很容易通过添加廉价设备实现扩展 |
| 可用性 | 好 | 很好 | RDBMS在任何时候都以保证数据一致性为优先目标,其次才是优化系统性能,随着数据规模的增大,RDBMS为了保证严格的一致性,只能提供相对较弱的可用性。大多数NoSQL都能提供较高的可用性 |
| 标准化 | 是 | 否 | RDBMS已经标准化(SQL)NoSQL还没有行业标准,不同的NoSQL数据库都有自己的查询语言,很难规范应用程序接口。StoneBraker认为:NoSQL缺乏统一查询语言,将会拖慢NoSQL发展 |
| 技术支持 | 高 | 低 | RDBMS经过几十年的发展,已经非常成熟,Oracle等大型厂商都可以提供很好的技术支持。NoSQL在技术支持方面仍然处于起步阶段,还不成熟,缺乏有力的技术支持 |
| 可维护性 | 复杂 | 复杂 | RDBMS需要专门的数据库管理员(DBA)维护。NoSQL数据库虽然没有DBMS复杂,也难以维护 |
- 关系型数据库
优点- 以完善的关系代数理论作为基础,有严格的标准,支持事务ACID四性
- 借助索引机制可以实现高效的查询,技术成熟,有专业公司的技术支持
缺点- 可扩展性较差,无法较好支持海量数据存储
- 数据模型过于死板、无法较好支持Web2.0应用,事务机制影响了系统的整体性能等
场景- 电信、银行等领域的关键业务系统,需要保证强事务一致性的系统
- NoSQL数据库
优点- 可以支持超大规模数据存储
- 灵活的数据模型可以很好地支持Web2.0应用,具有强大的横向扩展能力等
缺点- 缺乏数学理论基础,复杂查询性能不高
- 大都不能实现事务强一致性,很难实现数据完整性
- 技术尚不成熟,缺乏专业团队的技术支持,维护较困难等
场景- 互联网企业、传统企业的非关键业务
5.NoSQL的四大类型

- 键值数据库
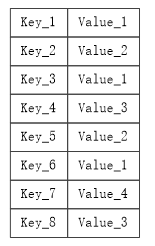

| 关键词 | 介绍 |
|---|---|
| 相关产品 | Redis、Riak、SimpleDB、Chordless、Scalaris、Memcached |
| 数据模型 | 键/值对 键是一个字符串对象 值可以是任意类型的数据,比如整型、字符型、数组、列表、集合等 |
| 典型应用 | 涉及频繁读写、拥有简单数据模型的应用 内容缓存,比如会话、配置文件、参数、购物车等 存储配置和用户数据信息的移动应用 |
| 优点 | 扩展性好,灵活性好,大量写操作时性能高 |
| 缺点 | 无法存储结构化信息,条件查询效率较低 |
| 不适用情形 | 不是通过键而是通过值来查:键值数据库根本没有通过值查询的途径 需要存储数据之间的关系:在键值数据库中,不能通过两个或两个以上的键来关联数据 需要事务的支持:在一些键值数据库中,产生故障时,不可以回滚 |
| 使用者 | 百度云数据库(Redis)、GitHub(Riak)、BestBuy(Riak)、Twitter(Redis和Memcached)、StackOverFlow(Redis)、Instagram (Redis)、Youtube(Memcached)、Wikipedia(Memcached) |
-
列族数据库

关键词 介绍 相关产品 BigTable、HBase、Cassandra、HadoopDB、GreenPlum、PNUTS 数据模型 列族 典型应用 分布式数据存储与管理、数据在地理上分布于多个数据中心的应用程序、可以容忍副本中存在短期不一致情况的应用程序、拥有动态字段的应用程序、拥有潜在大量数据的应用程序 优点 查找速度快,可扩展性强,容易进行分布式扩展,复杂性低 缺点 功能较少,大都不支持强事务一致性 不适用情形 需要ACID事务支持的情形,Cassandra等产品就不适用 使用者 Ebay(Cassandra)、Instagram(Cassandra)、NASA(Cassandra)、Twitter(Cassandra and HBase)、Facebook(HBase)、Yahoo!(HBase) -
文档数据库

关键词 介绍 相关产品 MongoDB、CouchDB、Terrastore、ThruDB、RavenDB、SisoDB、RaptorDB、CloudKit、Perservere、Jackrabbit 数据模型 键/值对,值(value)是版本化的文档 典型应用 存储、索引并管理面向文档的数据或者类似的半结构化数据,比如,用于后台具有大量读写操作的网站、使用JSON数据结构的应用、使用嵌套结构等非规范化数据的应用程序 优点 性能好(高并发),灵活性高,复杂性低,数据结构灵活,提供嵌入式文档功能 缺点 缺乏统一的查询语法 不适用情形 在不同的文档上添加事务。文档数据库并不支持文档间的事务,如果对这方面有需求则不应该选用这个解决方案 使用者 百度云数据库(MongoDB)、SAP (MongoDB)、Codecademy (MongoDB)、Foursquare (MongoDB)、NBC News (RavenDB) -
图形数据库
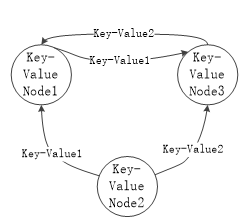
关键词 介绍 相关产品 Neo4J、OrientDB、InfoGrid、Infinite Graph、GraphDB 数据模型 图结构 典型应用 专门用于处理具有高度相互关联关系的数据,比较适合于社交网络、模式识别、依赖分析、推荐系统以及路径寻找等问题 优点 灵活性高,支持复杂的图形算法,可用于构建复杂的关系图谱 缺点 复杂性高,只能支持一定的数据规模 使用者 Adobe(Neo4J)、Cisco(Neo4J)、T-Mobile(Neo4J)
6.NoSQL的三大基石
-
CAP

-
C(Consistency)一致性,是指任何一个读操作总是能够读到之前完成的写操作的结果,也就是在分布式环境中,多点的数据是一致的,或者说,所有节点在同一时间具有相同的数据
-
A(Availability)可用性,是指快速获取数据,可以在确定的时间内返回操作结果,保证每个请求不管成功或者失败都有响应
-
P(Tolerance of Network Partition)分区容忍性,是指当出现网络分区的情况时(即系统中的一部分节点无法和其他节点进行通信),分离的系统也能够正常运行,也就是说,系统中任意信息的丢失或失败不会影响系统的继续运作。

-
CA也就是强调一致性(C)和可用性(A),放弃分区容忍性(P),最简单的做法是把所有与事务相关的内容都放到同一台机器上。很显然,这种做法会严重影响系统的可扩展性。传统的关系数据库(MySQL、SQL Server和PostgreSQL),都采用了这种设计原则,因此,扩展性都比较差
-
CP也就是强调一致性(C)和分区容忍性(P),放弃可用性(A),当出现网络分区的情况时,受影响的服务需要等待数据一致,因此在等待期间就无法对外提供服务
-
AP也就是强调可用性(A)和分区容忍性(P),放弃一致性(C),允许系统返回不一致的数据
-
-
BASE
-
基本可用(Basically Availble)基本可用,是指一个分布式系统的一部分发生问题变得不可用时,其他部分仍然可以正常使用,也就是允许分区失败的情形出现
-
软状态(Soft-state)“软状态(soft-state)”是与“硬状态(hard-state)”相对应的一种提法。数据库保存的数据是“硬状态”时,可以保证数据一致性,即保证数据一直是正确的。“软状态”是指状态可以有一段时间不同步,具有一定的滞后性
-
最终一致性(Eventual consistency)一致性的类型包括强一致性和弱一致性,二者的主要区别在于高并发的数据访问操作下,后续操作是否能够获取最新的数据。对于强一致性而言,当执行完一次更新操作后,后续的其他读操作就可以保证读到更新后的最新数据。反之,如果不能保证后续访问读到的都是更新后的最新数据,那么就是弱一致性。
-
-
最终一致性
最终一致性根据更新数据后各进程访问到数据的时间和方式的不同,可以划分为以下几类
-
因果一致性如果进程A通知进程B它已更新了一个数据项,那么进程B的后续访问将获得A写入的最新值。而与进程A无因果关系的进程C的访问,仍然遵守一般的最终一致性规则
-
读己写一致性可以视为因果一致性的一个特例。当进程A自己执行一个更新操作之后,它自己总是可以访问到更新过的值,绝不会看到旧值
-
单调读一致性如果进程已经看到过数据对象的某个值,那么任何后续访问都不会返回在那个值之前的值
-
会话一致性它把访问存储系统的进程放到会话(session)的上下文中,只要会话还存在,系统就保证“读己之所写”一致性。如果由于某些失败情形令会话终止,就要建立新的会话,而且系统保证不会延续到新的会话
-
单调写一致性系统保证来自同一个进程的写操作顺序执行。系统必须保证这种程度的一致性,否则就非常难以编程了
-
7.NoSQL数据库演变
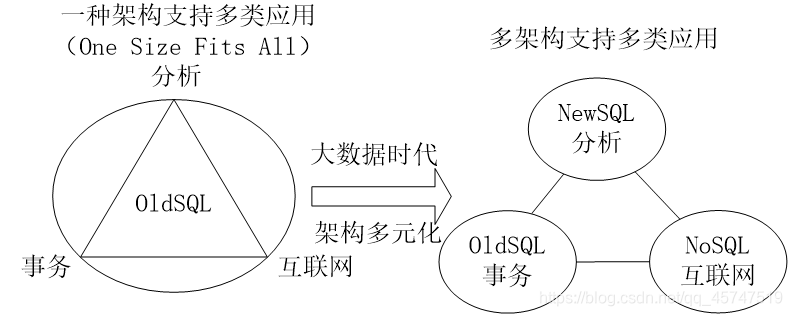
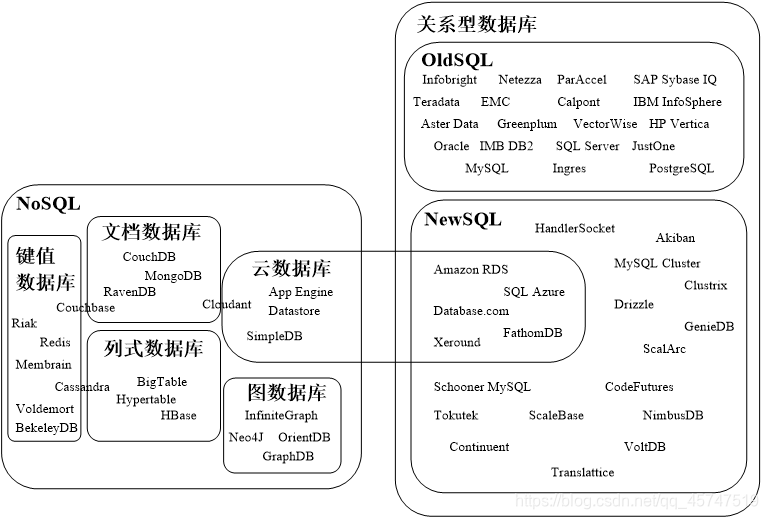
8.几个常见数据库的对比

-
MySQL
产生年代较早,而且随着LAMP大潮得以成熟。尽管其没有什么大的改进,但是新兴的互联网使用的最多的数据库
-
MongoDB
是个新生事物,提供更灵活的数据模型、异步提交、地理位置索引等五花十色的功能
-
HBase
是个“仗势欺人”的大象兵。依仗着Hadoop的生态环境,可以有很好的扩展性。但是就像象兵一样,使用者需要养一头大象(Hadoop),才能驱使他
-
Redis
是键值存储的代表,功能最简单。提供随机数据存储。就像一根棒子一样,没有多余的构造。但是也正是因此,它的伸缩性特别好。就像悟空手里的金箍棒,大可捅破天,小能成缩成针
发表评论
最新留言
关于作者
