本文共 8469 字,大约阅读时间需要 28 分钟。
文章目录
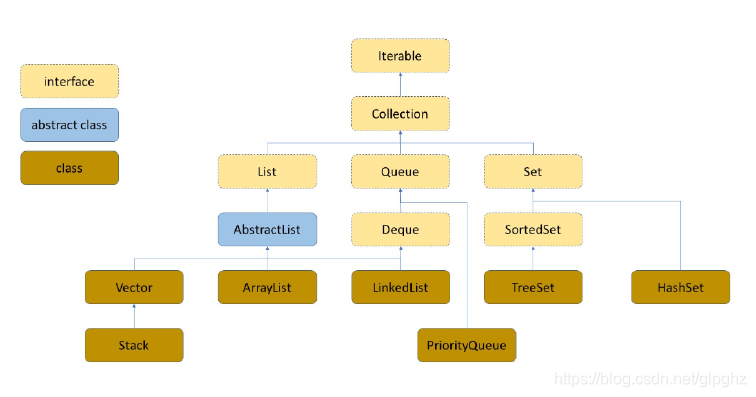
一 集合(Collection接口)
0 java.util.Collections——集合工具类
除了Collection接口,还有一个Collections类,Collections是集合类的一个工具类/帮助类,其中提供了一系列静态方法,用于对集合中元素进行排序、搜索以及线程安全等各种操作。import java.util.Collections
boolean addAll(Collection<?extends E> c,T... elements):可以接受多个Collection对象
Listlist = new ArrayList<>(); Collections.addAll(list,3,4,5,6,7); System.out.println(list); 结果:[3, 4, 5, 6, 7]
reverse(List<?> list):反转指定列表中元素的顺序。
Listlist = new ArrayList<>(); Collections.addAll(list,3,4,5,6,7); Collections.reverse(list); System.out.println(list); 结果:[7, 6, 5, 4, 3]
sort(List<T> list, Comparator<? super T> c)根据指定的比较器引起的顺序对指定的列表进行排序。
① 降序排序
Listlist = new ArrayList<>(); int b=0; Collections.addAll(list,3,4,5,6,7,b); Collections.sort(list, new Comparator () { @Override public int compare(Integer o1, Integer o2) { return o2-o1; } }); System.out.println(list); 结果: [7, 6, 5, 4, 3, 0]
可以替换为lambda表达式
Collections.sort(list, (o1, o2) -> o2-o1);
swap(List<?> list, int i, int j) :交换指定列表中指定位置的元素。
Listlist = new ArrayList<>(); Collections.addAll(list,3,4,5,6,7); Collections.swap(list, 0,list.size()-1); System.out.println(list);
1 Iterator接口 迭代器
Iterable接口: 迭代器,可以通过迭代器遍历集合的数据。
只要实现了Iterator接口,就可以使用foreach进行遍历 因为Collection实现了Iterator接口,所以Collection下面的所有容器,都可以使用Iterator进行遍历,可以说迭代器统一了对容器的迭代方式。(1) 迭代器——也是一种设计模式
java.util.Iterator接口:迭代器(对集合进行遍历并选择集合中的元素)
boolean hasNext():判断集合中还有没有下个元素,有就返回true,没有则返回false E next() 取出集合的下一个元素 remove:将迭代器新近返回的元素删除 注意:
Interator迭代器是一个接口,需要使用Collection接口的iterator()方法,返回迭代器的实现类对象Listlist = new ArrayList<>();Iterator it = list.iterator();while(it.hasNext()){ Integer num = it.next();}
(2) for each循环 增强for循环
底层为迭代器 Collection extends Iterable:所有的单列集合都可以使用增强for循环ArrayListlist = new ArrayList<>();list.add("a");list.add("b");for(String s:list){ Syetem.out.println(s);}
2 接口Collection

Collection接口: 是集合类List、Set、Queue的一个最基本的接口。它提供了对集合对象进行基本操作的通用接口方法。
- List 接口: 必须按照插入的顺序保存元素
- Set 接口:不能有重复元素
- Queue 接口: 按照插入顺序来确定对象产生的顺序。
Collection常用方法:
boolean add(E e):将e放入集合中void clear():清空集合contains(Object o):如果此集合包含指定的元素,则返回 true 。hashCode():返回此集合的哈希码值。iterator():返回此集合中的元素的迭代器。boolean isEmpty():判断是否为空boolean remove(Object e):删除一个元素eint size():返回集合中的元素个数Object[] toArray():返回一个装有所有集合元素的数组
注意:
对于打印数组需要调用Arrays.toString()方法先转为字符串再打印,而集合元素可以直接打印 Integer[] array = { 1,3,4,5};System.out.println(Arrays.toString(array));List list2 = Arrays.asList(array);System.out.println(list2); (1) List——有序集合
List是一个有序的集合(Collection)类,List可以精确控制列表中每个元素的插入位置。 可以通过整数索引(列表中的位置)访问元素,并搜索列表中的元素。 List允许重复的元素。
 List接口在Collection接口的基础上添加了大量的方法。
List接口在Collection接口的基础上添加了大量的方法。 add(E e):将指定的元素追加到此列表的末尾(可选操作)。addAll(Collection<? extends E> c):按指定集合的迭代器(可选操作)返回的顺序将指定集合中的所有元素附加到此列表的末尾。clear():从此列表中删除所有元素。contains(Object o):如果此列表包含指定的元素,则返回 true 。get(int index):返回此列表中指定位置的元素。hashCode():返回此列表的哈希码值。indexOf(Object o):返回此列表中指定元素的第一次出现的索引,如果此列表不包含元素,则返回-1。lastIndexOf(Object o):返回此列表中指定元素的最后一次出现的索引,如果此列表不包含元素,则返回-1。isEmpty():如果此列表不包含元素,则返回 true 。remove(int index): 删除该列表中指定位置的元素。remove(Object o):从列表中删除指定元素的第一个出现(如果存在)。removeAll(Collection<?> c):从此列表中删除包含在指定集合中的所有元素。set(int index, E element):用指定的元素替换此列表中指定位置的元素。size():返回此列表中的元素数。sort(Comparator<? super E> c):使用Comparator排序此列表来比较元素。toArray():以正确的顺序(从第一个到最后一个元素)返回一个包含此列表中所有元素的数组。
实现List接口的常用类有, LinkedList, ArrayList, Vector, Stack:
1)ArrayList(可调整大小的数组):
ArrayList内部通过数组实现,它允许对元素进行快速随机访问。数组的缺点是每个元素之间不能有间隔,当数组大小不满足时需要进行扩容,即将已经有数据的数组复制到新的存储空间中。当从ArrayList的中间位置插入或者删除元素时,需要对数组进行复制、移动代价比较高,时间复杂度为O(n)。因此ArrayList适合查找和遍历,不适合插入和删除。
Listlist = new ArrayList<>();
除了实现List 接口之外,该类还提供了一些方法来操纵内部使用的数组大小。
- ensureCapacity(int minCapacity) :如果需要,增加此ArrayList实例的容量,以确保它可以至少保存最小容量参数指定的元素数。
2)LinkedList(链表):
LinkedList是用链表结构存储数据的,适合数据的动态插入和删除,随机访问和遍历速度比较慢。允许null元素,另外LinkedList还提供了List接口中没有定义的方法,用来操作表头和表尾元素,可以当作栈(Stack)、队列(Queue)和双端队列(Deque)使用。
Listlist1 = new LinkedList<>();
双链表实现了List和Deque接口。
addFirst(E e):在该列表开头插入指定的元素。addLast(E e):将指定的元素追加到此列表的末尾。- removeFirst():删除并返回列表的第一个元素
- removeLast():删除并返回列表的最后一个元素
getFirst():返回此列表中的第一个元素。getLast() :返回此列表中的最后一个元素。get(int index):返回此列表中指定位置的元素。offer(E e):将指定的元素添加为此列表的尾部(最后一个元素)。peek():检索但不删除此列表的头(第一个元素)。poll():检索并删除此列表的头(第一个元素)。pop():从此列表表示的堆栈中弹出一个元素。push(E e):将元素推送到由此列表表示的堆栈上。set(int index, E element):用指定的元素替换此列表中指定位置的元素。
3) Vector(数组实现,同步)
Vector和ArrayList一样都是通过数组实现的,不同的是Vector支持线程同步,即某一时刻只有一个线程能够写Vector,避免多线程同时写而引起的不一致性,但实现同步需要很高的花费,因此访问Vector比访问ArrayList慢。
注意:
采用List<String> list = new ArrayList<>();而非ArrayList<String> list = new ArrayList<>();是想统一使用一个接口,在需要修改时,只需要对实现类进行修改。但是当需要使用LinkedList在List基类中没有的方法时,则不能将LinkedList向上转型为为更通用的List接口,此时需要创建出具体的LinkedList:LinkedList<String> list = new LinkedList<>(); 4) Stack类
Stack继承自Vector,实现了一个后进先出(LIFO)的堆栈。Stack提供了push,pop,peek等额外的方法使得Vector得以被当作堆栈使用。
import java.util.Stack;Stackstack = new Stack<>();
常用方法:
empty():测试此堆栈是否为空。peek():查看此堆栈顶部的对象,而不从堆栈中删除它。pop():删除此堆栈顶部的对象,并将该对象作为此函数的值返回。push(E item):将项目推送到此堆栈的顶部。
(2)Set

- Set不保存重复元素, 最多允许一个null元素 ,存入和取出的顺序不一定相同,主要用来快速查找元素。Set具有和Collection一样的接口,因此没有额外的功能。实际上Set就是Collection,只是行为不同。(多态思想的典型应用:相同的接口,表现不同的行为)
- HashSet所维护的顺序与TreeSet或LinkedHashSet都不同,它们实现了不同的元素存储方式。例如,TreeSet将元素存储在红黑树数据结构中,而HashSet使用的是散列函数。LinkedHashSet使用散列查询数据,使用链表来维护元素的插入顺序。
1) HashSet(哈希表)
HashSet实现Set接口,由哈希表(实际为HashMap实例)支持。对集合的迭代次序不作任何保证; 允许null元素 。 HashSet是按照哈希值来存的,所以取数据也是按照哈希值来取的。元素的哈希值是通过元素的hashcode方法来获取的,HashSet首先判断两个元素的哈希值,如果一样,接着会比较equals方法,如果equals结果为true,HashSet就视为同一个元素,如果为false就不是同一个元素。哈希值一样而equals为false的元素,会存放在同一个哈系桶中(一个hashcode位置上可以存储多个元素):
 常用方法:
常用方法: -
add(E e):将指定的元素添加到此集合(如果尚未存在)。 -
contains(Object o):如果此集合包含指定的元素,则返回 true 。 -
isEmpty():如果此集合不包含元素,则返回 true 。 -
remove(Object o):如果存在,则从该集合中删除指定的元素。 -
size():返回此集合中的元素数(其基数)。
2) TreeSet(二叉树)
TreeSet类的实现基于TreeMap,Integer和String对象都可以使用TreeSet进行排序,但是自定义的类必须要实现Comparable接口,并覆写compareTo()函数才可以正常使用;或者在构造TreeSet时传入一个比较器Comparator.
3) LinkedHashSet (HashSet+LinkedHashMap)
LinkedHashSet继承于HashSet,内部是基于LinkedHashMap来实现的。LinkedHashSet底层使用LinkedHashMap来保存所有的元素。所使用的方法与HashSet基本相同。
(3)Queue

PriorityQueueminHeap = new PriorityQueue<> (k, new Comparator () { @Override public int compare(Integer o1, Integer o2) { return o1.compareTo(o2);//默认是小堆 //return o2.compareTo(o1);//大堆 } });
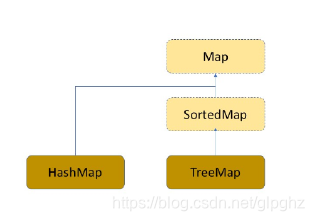
3 Map 接口

Map常用方法:
get(Object k):获取对应K值的valuegetOrDefault(Object k,V defaultValue): 查找K值对应得value,没有则使用默认值替代put(k key,V value):将指定得k-v放入Map中containsKey(Object key):判断是否包含keycontainsValue(Object value):判断是否包含valueSet<Map.Entry<K,V>> entrySet(): 将所有键值对返回isEmpty():判断是否为空size():返回键值对的数量
(1)HashMap(数组+链表+红黑树)
HashMap根据键的hashCode值存储数据,大多数情况下可以直接定位到它的值,因而具有很快的访问速度,但访问顺序却是不确定的。 HashMap的键最多只允许一条记录为null,值可以为null不受限制.。 HashMap是非线程安全的,即任一时刻可以有多个线程同时写HashMap,可能会导致数据的不一致。如果需要满足线程安全,可以用Collections的synchronizedMap方法使HashMap具有线程安全的能力,或者使用ConcurrentHashMap。
HashMap的数组容量始终保持为2n ,扩容后,数组大小为当前的2倍。其中负载因子默认为0.75.
当链表的元素超过8个以后,会将链表转换为红黑树,查找的时候可以将单链表的时间复杂度O(n)降为O(logN)。
(2)ConcurrentHashMap
ConcurrentHashMap支持并发操作。整个ConcurrentHashMap是由一个个Segment(段,分段锁)组成,ConcurrentHashMap是一个Segment数组,Segment通过继承 ReetrantLock 来进行加锁,所以每次加锁的操作锁住的都是一个segment,这样只要保证每个Segment是线程安全的,也就实现了全局的线程安全。segment的数量默认为16个,即ConcurrentHashMap能够同时允许16个线程并发的进行写操作。segment的数量可以在初始化的时候进行设定,但是一旦初始化完成后,它是不能够进行扩容的。
注:
concurrencyLevel:并行级别、并发数、Segment数ConcurrentHashMap1.7 1.8详解:
(3)HashTable(线程安全)
HashTable继承Dictionary类,实现一个key-value映射的哈希表。任何非空(non-null)的对象都可作为key或者value。是线程安全的,但是任一时间只能有一个线程写HashTable,并发性不如ConcurrentHashMap,因为ConcurrentHashMap引入了分段锁。实际开发中,不建议使用。
(4)TreeMap(可排序)
TreeMap实现了SortedMap接口,能够根据记录的键进行升序排序(默认),也可以指定比较器。当用Iterator遍历TreeMap时,得到的记录是有序的。如果需要使用有序的映射,建议使用TreeMap。
注:
- 使用TreeMap时,key必须实现Comparabel接口或者在构造TreeMap时传入自定义的Comparator比较器,否则会抛出java.lang.ClassCastException异常。
- HashMap通过hashcode对其内容进行快速查找,而TreeMap中所有的元素都保持着某种固定的顺序,如果你需要得到一个有序的结果你就应该 使用TreeMap,
(5)LinkHashMap(记录插入顺序)
LinkedHashMap 是 HashMap的一个子类,在底层使用了一个链表保存了记录的插入顺序,在用Iterator遍历时,先得到的记录肯定是先插入的。
(6)WeakHashMap类
WeakHashMap是一种改进的HashMap, 它对key实行“弱引用”, 如果一个key不再被外部所引用,那么该key可以被GC回收。
发表评论
最新留言
关于作者
