本文共 12207 字,大约阅读时间需要 40 分钟。
接我上一条的笔记,今天我加了遗传算法进行优化BP神经网络,其基本思想就是用个体代表网络的初始权值和阈值、个体值初始化的BP神经网络的预测误差作为该个体的适应度值,通过选择、交叉、变异操作寻找最优个体,即最优的BP神经网络初始权值。
了解过BP神经网络的朋友都知道,BP神经网络初始神经元之间的权值和阈值一般随机选择,因此容易陷入局部最小值,通过引入遗传算法就可以很好找到全局最小值,废话不多说,直接上。(代码仅供参考,小白起步)
题目:拟合非线性函数:y=x1x1+x2x2(平方和)
设置网络:输入层2个神经元,隐含层5个神经元,输出层1个神经元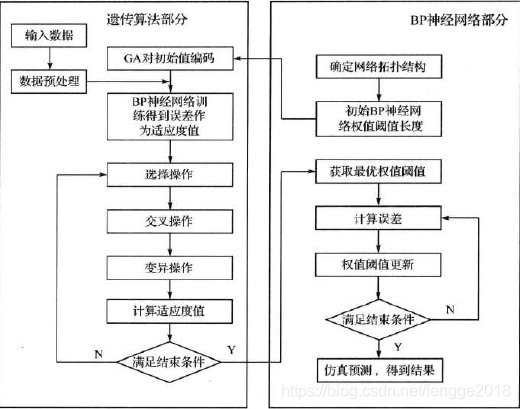
具体会发生什么、怎么发生,我们通过下面代码一步一步来:
%% 该代码为基于遗传算法神经网络的预测代码% 清空环境变量clcclear% %%网络结构建立%读取数据load data input output%节点个数inputnum=2;hiddennum=5;outputnum=1;%训练数据和预测数据input_train=input(1:1900,:)';%取1到1900行的数据来训练input_test=input(1901:2000,:)';%取1901到2000行的数据来测试output_train=output(1:1900);output_test=output(1901:2000);%选连样本输入输出数据归一化[inputn,inputps]=mapminmax(input_train);%归一化到[-1,1]之间,inputps用来作下一次同样的归一化[outputn,outputps]=mapminmax(output_train);%构建网络net=newff(inputn,outputn,hiddennum);%单隐含层,5个隐含层神经元%% 遗传算法参数初始化maxgen=20; %进化代数,即迭代次数sizepop=10; %种群规模pcross=0.2; %交叉概率选择,0和1之间pmutation=0.1; %变异概率选择,0和1之间%节点总数:输入隐含层权值、隐含阈值、隐含输出层权值、输出阈值(4个基因组成一条染色体)numsum=inputnum*hiddennum+hiddennum+hiddennum*outputnum+outputnum;%21个,10,5,5,1lenchrom=ones(1,numsum);%个体长度,暂时先理解为染色体长度,是1行numsum列的矩阵 bound=[-3*ones(numsum,1) 3*ones(numsum,1)]; %是numsum行2列的串联矩阵,第1列是-3,第2列是3%------------------------------------------------------种群初始化--------------------------------------------------------individuals=struct('fitness',zeros(1,sizepop), 'chrom',[]); %将种群信息定义为一个结构体:10个个体的适应度值,10条染色体编码信息avgfitness=[]; %每一代种群的平均适应度,一维bestfitness=[]; %每一代种群的最佳适应度bestchrom=[]; %适应度最好的染色体,储存基因信息%初始化种群for i=1:sizepop %随机产生一个种群 individuals.chrom(i,:)=Code(lenchrom,bound); %编码(binary(二进制)和grey的编码结果为一个实数,float的编码结果为一个实数向量) x=individuals.chrom(i,:); %计算适应度 individuals.fitness(i)=fun(x,inputnum,hiddennum,outputnum,net,inputn,outputn); %染色体的适应度end 通过上面代码我们就知道,结构体individuals就是种群,里面包含了两个矩阵,一个用来放全部个体的适应度值,一个用来存放染色体的信息。好,函数从Code开始,也就是给染色体进行编码,让每个基因都赋值初始值。
function ret=Code(lenchrom,bound)%本函数将变量编码,用于随机初始化一个种群% lenchrom input : 染色体长度(其实就是1行21列的矩阵)% bound input : 变量的取值范围% ret output: 染色体的编码值flag=0;while flag==0 pick=rand(1,length(lenchrom));%length得到一个矩阵里较大的行数或者列数,lenchrom是1行numsum列矩阵故返回numsum,即pick是1行numsum列的随机数矩阵 %bound(:,1)'为取1行numsum列的值都是-3,bound(:,2)为取numsum行第2列的值都是3,(bound(:,2)-bound(:,1))'得到1行numsum列矩阵为6再与pick逐个元素相乘 ret=bound(:,1)'+(bound(:,2)-bound(:,1))'.*pick; %线性插值,编码结果以实数向量存入ret中,ret是1行numsum列的矩阵 flag=test(ret); %检验染色体的可行性end
编码之后,每个基因都有了随机数初始值,我们再接着看test函数里有什么。
function flag=test(code)%判断阈值和权值是否超界% lenchrom input : 染色体长度% bound input : 变量的取值范围% code output: 染色体的编码值% x=code; %先解码,x是1行numsum列的矩阵% flag=1;f1=isempty(find(code>3, 1));%isempty(A)若A为空,则返回1,否则返回0(这个3其实是bound的边界值)f2=isempty(find(code<-3, 1));%find中如果满足条件,则返回元素位置,最后面的1是为了让程序提高寻找效率%fine(code<-3)能够找出所有满足条件的元素位置,但我们只需要检测code<-3就好了没必要找到全部,因此用find(code<-3,1)if f1*f2==0 %有基因(权值或者阈值)超界,返回0让程序重新编码 flag=0;else flag=1;%编码符合条件,返回1跳出编码end% if (x(1)<0)&&(x(2)<0)&&(x(3)<0)&&(x(1)>bound(1,2))&&(x(2)>bound(2,2))&&(x(3)>bound(3,2))% flag=0;% end
接着就是我们的fun函数(要拉上去再看看啦),fun函数是用来给每个个体生成适应度值的,初始值是随机数
function error = fun(x,inputnum,hiddennum,outputnum,net,inputn,outputn)%该函数用来计算适应度值%x input 染色体信息%inputnum input 输入层节点数%outputnum input 隐含层节点数%net input 网络%inputn input 训练输入数据%outputn input 训练输出数据%error output 个体适应度值%提取w1=x(1:inputnum*hiddennum);%取到输入层与隐含层连接的权值,在Code函数里已经赋值B1=x(inputnum*hiddennum+1:inputnum*hiddennum+hiddennum);%隐含层神经元阈值w2=x(inputnum*hiddennum+hiddennum+1:inputnum*hiddennum+hiddennum+hiddennum*outputnum);%取到隐含层与输出层连接的权值B2=x(inputnum*hiddennum+hiddennum+hiddennum*outputnum+1:inputnum*hiddennum+hiddennum+hiddennum*outputnum+outputnum);%输出层神经元阈值%网络进化参数net.trainParam.epochs=20;%迭代次数net.trainParam.lr=0.1;%学习率net.trainParam.goal=0.00001;%最小目标值误差net.trainParam.show=100;net.trainParam.showWindow=0; %网络权值赋值net.iw{ 1,1}=reshape(w1,hiddennum,inputnum);%将w1由1行inputnum*hiddennum列转为hiddennum行inputnum列的二维矩阵net.lw{ 2,1}=reshape(w2,outputnum,hiddennum);%更改矩阵的保存格式net.b{ 1}=reshape(B1,hiddennum,1);%1行hiddennum列,为隐含层的神经元阈值net.b{ 2}=reshape(B2,outputnum,1);%网络训练net=train(net,inputn,outputn);an=sim(net,inputn);error=sum(abs(an-outputn));%染色体对应的适应度值% [m n]=size(inputn);% A1=tansig(net.iw{ 1,1}.*inputn+repmat(net.b{ 1},1,n)); %需与main函数中激活函数相同% A2=purelin(net.iw{ 2,1}.*A1+repmat(net.b{ 2},1,n)); %需与main函数中激活函数相同 % error=sumsqr(outputn-A2); 到这里,我们已经得到了种群的初始化信息,每个基因已经赋值,并且每个个体的适应度值已经得到(适应度值是误差,所以越小越好),那我们再通过种群的初始化信息计算出最好的适应度值,找到那个个体。
%找最好的染色体[bestfitness, bestindex]=min(individuals.fitness);%bestindex是最小值的索引(位置/某个个体),bestfitness的值为最小适应度值bestchrom=individuals.chrom(bestindex,:); %最好的染色体,从10个个体中挑选到的avgfitness=sum(individuals.fitness)/sizepop; %染色体的平均适应度(所有个体适应度和 / 个体数)% 记录每一代进化中最好的适应度和平均适应度trace=[avgfitness bestfitness]; %trace矩阵,1行2列,avgfitness和bestfitness仅仅是数值
以上工作做完,我们就已经能够把握这个种群的基本信息了,但是肯定,她是第一代,不是最好的,那么我们就要让种群进行选择,选出最好的个体,进行繁殖生子(交叉、变异),不断地得到新的个体,再不断地选择……直到种群能得到最好的个体,才能最有效病准确地解决我们的问题,我们设置让种群进化20代。
在这之前,我们要先来了解一下,如何让代码实现自然界中的“选择”,并不是说个体的适应度值不好,就永远不会被选择到,真实情况应该是:适应度值好的个体,被选中的概率就会高一些,但是它还是有可能不会被选到的,这才叫公平。
我们已经把是个个体的适应度值随机初始化了,那么我们可以把这个适应度值都转成一个个概率,概率大的被选中概率就大一点,所有个体被选中的概率加起来就等于1。把十个个体集中放到一个轮盘里,概率的大小对应着扇形面积的大小,然后我们产生0~1的随机数,随机数在哪个扇形区,哪个对应个体就会被选中。看代码实现:
function ret=Select(individuals,sizepop)% 本函数对每一代种群中的染色体进行选择,以进行后面的交叉和变异% individuals input : 种群信息% sizepop input : 种群规模% ret output : 经过选择后的种群% 选择操作即为决定整个遗传算法种群走向的关键性步骤,遗传算法的选择操作% 通常以较大的概率保留父代优良个体到子代中,以此使得种群往适应度值最佳的方向进化,% 通俗的讲就是:有若干个备选方案,而且每个方案都有自己的潜力分值,但是在选择的时候并不完全按照分值的高低来选% 而是有一定的概率接受,分值高的接受概率高,分值较低接受的概率也低。%根据个体适应度值进行排序fitness1=10./individuals.fitness;%10为系数,取倒数得到新的数组fitness1,其值越大个体被选中的概率就越大%.*或者./表示对矩阵里每个元素都执行同样操作sumfitness=sum(fitness1);sumf=fitness1./sumfitness;%每个个体遗传到下一代的概率,1行sizepop列index=[]; %仅仅是一个角标,当做记号即可%采用轮盘赌法选择新个体for i=1:sizepop %转sizepop次轮盘,%共选出sizepop个个体保留至下代 pick=rand; %产生随机数赋给pick while pick==0 %若随机数是0,则重新产生随机数 pick=rand; end for j=1:sizepop %循环每个个体,找出此次的rank落在哪个个体的区间 pick=pick-sumf(j); %寻找rank落在哪个个体所在的区间,个体被选中的概率越大,其所占区间越大 if pick<0 %说明个体j的概率比较大(适应度值较小) index=[index j]; %1行sizepop列的矩阵,存放被选中的个体标记 break; %寻找落入的区间,此次转轮盘选中了染色体i,注意:在转sizepop次轮盘的过程中,有可能会重复选择某些染色体 end endend%新的种群individuals.chrom=individuals.chrom(index,:);individuals.fitness=individuals.fitness(index);ret=individuals;
如果算法已经能够实现自然界中的“公平选择”,那么我们就让它进化吧,不断产生子代、变异,然后再一轮一轮地选择。
%% 迭代求解最佳初始阀值和权值% 进化开始for i=1:maxgen % 选择 individuals=Select(individuals,sizepop); % avgfitness=sum(individuals.fitness)/sizepop;%种群的平均适应度值 %交叉 individuals.chrom=Cross(pcross,lenchrom,individuals.chrom,sizepop); % 变异 individuals.chrom=Mutation(pmutation,lenchrom,individuals.chrom,sizepop,i,maxgen,bound); % 计算适应度 for j=1:sizepop x=individuals.chrom(j,:); %个体信息 individuals.fitness(j)=fun(x,inputnum,hiddennum,outputnum,net,inputn,outputn); %计算每个个体的适应度值 end %找到最小和最大适应度的染色体及它们在种群中的位置 [newbestfitness,newbestindex]=min(individuals.fitness);%最佳适应度值 [worestfitness,worestindex]=max(individuals.fitness); % 最优个体更新 if bestfitness>newbestfitness bestfitness=newbestfitness; bestchrom=individuals.chrom(newbestindex,:); end individuals.chrom(worestindex,:)=bestchrom;%取代掉最差的,相当于淘汰 individuals.fitness(worestindex)=bestfitness; avgfitness=sum(individuals.fitness)/sizepop; trace=[trace;avgfitness bestfitness]; %记录每一代进化中最好的适应度和平均适应度 FitRecord=[FitRecord;individuals.fitness];%记录每一代进化中种群所有个体的适应度值end
以上代码就已经实现了种群的进化和选择,把不好的个体淘汰掉,把优秀的个体留下,下面来看交叉函数与变异函数:
function ret=Cross(pcross,lenchrom,chrom,sizepop)%本函数完成交叉操作% pcorss input : 交叉概率% lenchrom input : 染色体的长度% chrom input : 染色体群% sizepop input : 种群规模% ret output : 交叉后的染色体 for i=1:sizepop %每一轮for循环中,可能会进行一次交叉操作,染色体是随机选择的,交叉位置也是随机选择的,%但该轮for循环中是否进行交叉操作则由交叉概率决定(continue控制) % 随机选择两个染色体进行交叉 pick=rand(1,2); %产生1行2列的随机数矩阵 while prod(pick)==0 %prod(A)检测矩阵是否有0,有则重新生成随机数 pick=rand(1,2); end index=ceil(pick.*sizepop); %ceil(z)函数将输入z中的元素取整,2.1则取3 % 交叉概率决定是否进行交叉 pick=rand; while pick==0 pick=rand; end if pick>pcross continue; %如果随机数比交叉概率大,则重新回到for语句,不执行下面的语句 end flag=0; %随机数比交叉概率小,说明可以交叉 while flag==0 % 随机选择交叉位 pick=rand; while pick==0 pick=rand; end pos=ceil(pick.*sum(lenchrom)); %随机选择进行交叉的位置,即选择第几个变量进行交叉,注意:两个染色体交叉的位置相同 pick=rand; %交叉开始 v1=chrom(index(1),pos);%随机选到index(1)条染色体以及它的位置pos,将其变量值取出 v2=chrom(index(2),pos); chrom(index(1),pos)=pick*v2+(1-pick)*v1;%实数交叉法,交叉公式 chrom(index(2),pos)=pick*v1+(1-pick)*v2; %交叉结束 flag1=test(chrom(index(1),:)); %检验染色体1的可行性 flag2=test(chrom(index(2),:)); %检验染色体2的可行性 if flag1*flag2==0 %如果两个染色体不是都可行,则重新交叉 flag=0; else flag=1; end end endret=chrom;
function ret=Mutation(pmutation,lenchrom,chrom,sizepop,num,maxgen,bound)% 本函数完成变异操作% pcorss input : 变异概率% lenchrom input : 染色体长度% chrom input : 染色体群% sizepop input : 种群规模% opts input : 变异方法的选择% pop input : 当前种群的进化代数和最大的进化代数信息% bound input : 每个个体的上届和下届% maxgen input :最大迭代次数% num input : 当前迭代次数% ret output : 变异后的染色体for i=1:sizepop %每一轮for循环中,可能会进行一次变异操作,染色体是随机选择的,变异位置也是随机选择的, %但该轮for循环中是否进行变异操作则由变异概率决定(continue控制) % 随机选择一个染色体进行变异 pick=rand; while pick==0 pick=rand; end index=ceil(pick*sizepop);%ceil(z)函数将输入z中的元素取整,2.1则取3,得到随机一条染色体 % 变异概率决定该轮循环是否进行变异 pick=rand; if pick>pmutation continue; end flag=0; while flag==0 % 变异位置 pick=rand; while pick==0 pick=rand; end pos=ceil(pick*sum(lenchrom)); %随机选择了染色体变异的位置,即选择了第pos个变量进行变异 pick=rand; %变异开始 fg=(rand*(1-num/maxgen))^2;%变异公式 if pick>0.5 chrom(index,pos)=chrom(index,pos)+(bound(pos,2)-chrom(index,pos))*fg; else chrom(index,pos)=chrom(index,pos)-(chrom(index,pos)-bound(pos,1))*fg; end %变异结束 flag=test(chrom(index,:)); %检验染色体的可行性 endendret=chrom;
好了,到这里,我们已经通过代码让这个种群进化了20代,挑选出了对于有利于解决我们问题的个体,形象地对应起来就是,现在我们每个基因都有了最好的赋值,当把它们放到网络中之后,它们就能够来解决问题了(预测作用)
%% 把最优初始阀值权值赋予网络预测w1=x(1:inputnum*hiddennum);B1=x(inputnum*hiddennum+1:inputnum*hiddennum+hiddennum);w2=x(inputnum*hiddennum+hiddennum+1:inputnum*hiddennum+hiddennum+hiddennum*outputnum);B2=x(inputnum*hiddennum+hiddennum+hiddennum*outputnum+1:inputnum*hiddennum+hiddennum+hiddennum*outputnum+outputnum);net.iw{ 1,1}=reshape(w1,hiddennum,inputnum);net.lw{ 2,1}=reshape(w2,outputnum,hiddennum);net.b{ 1}=reshape(B1,hiddennum,1);net.b{ 2}=reshape(B2,outputnum,1); 回想一下此时此刻的网络,已经有了权值阈值,输入层、隐含层和输出层已经有明确的数值了,我们接下来再训练好这个网络就行了。
%% BP网络训练%网络进化参数net.trainParam.epochs=100;net.trainParam.lr=0.1;net.trainParam.goal=0.00001;%网络训练[net,per2]=train(net,inputn,outputn);%% BP网络预测%数据归一化inputn_test=mapminmax('apply',input_test,inputps);an=sim(net,inputn_test);test_simu=mapminmax('reverse',an,outputps);error=test_simu-output_test; 接着,再把改打印出来的图形设置一下:
%% 遗传算法结果分析 figure(1)[r, c]=size(trace);plot([1:r]',trace(:,2),'b--');title(['适应度曲线 ' '终止代数=' num2str(maxgen)]);xlabel('进化代数');ylabel('适应度');legend('平均适应度','最佳适应度');disp('适应度 变量');figure(2)plot((output_test-test_simu)./test_simu,'-*');title('神经网络预测误差百分比')figure(3)plot(error,'-*')title('BP网络预测误差','fontsize',12)ylabel('误差','fontsize',12)xlabel('样本','fontsize',12) 完工,到这里就能够实现用遗传算法来优化BP神经网络了,最后运行得到图形就能发现,加了遗传算法之后网络的预测能力就更强,误差更小了。
如果要用代码的朋友,不要复制上面的,因为我已经把它拆开了,应该有好几个.m文件的,最后,包括使用到的数据,我已经打包好了,代码如果我有理解错误,欢迎朋友们纠正,谢谢!
(百度云连接,密码:gz73)发表评论
最新留言
关于作者
