本文共 3352 字,大约阅读时间需要 11 分钟。
伪分布式安装Hadoop
文档:http://hadoop.apache.org/docs/r2.7.6/hadoop-project-dist/hadoop-common/SingleCluster.html1.上传解压 tar -zxvf hadoop-2.7.3.tar.gz -C /opt/modules/
2.了解目录结构,删除无用文件
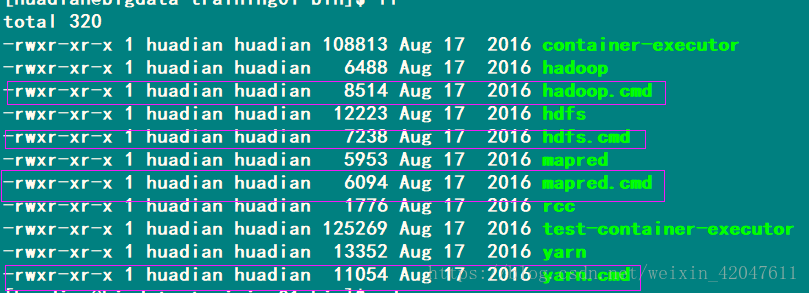


3.修改配置:etc/hadoop/
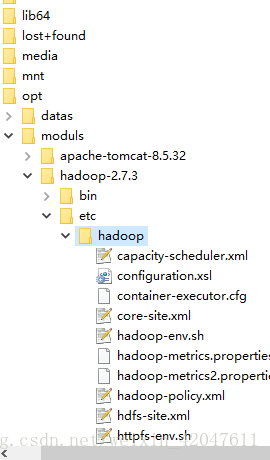
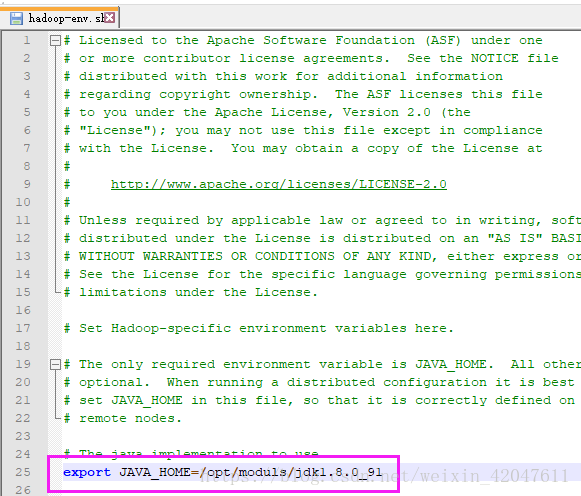
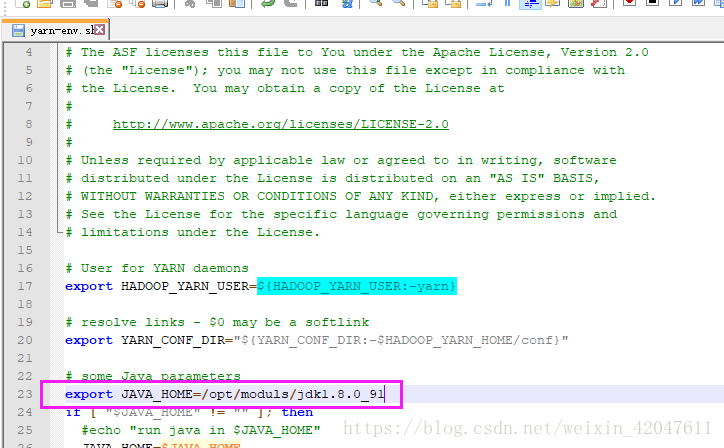
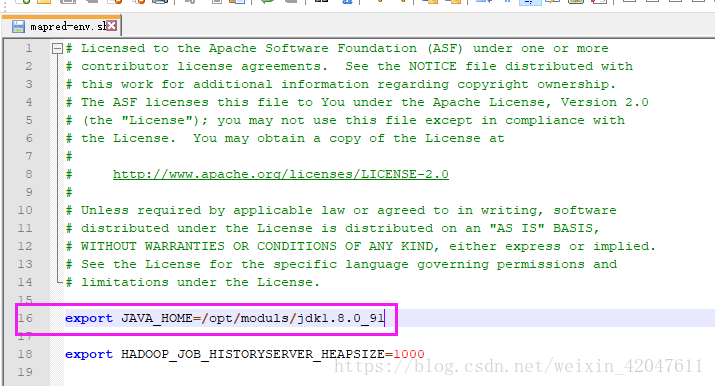
(1)*-env.sh:3个模块的环境变量文件
hadoop-env.sh 、yarn-env.sh(23行)、mapred-env.sh JAVA_HOME=/opt/modules/jdk1.8.0_91
(2)按模块配置,这个时候一般根据官方文档来配置
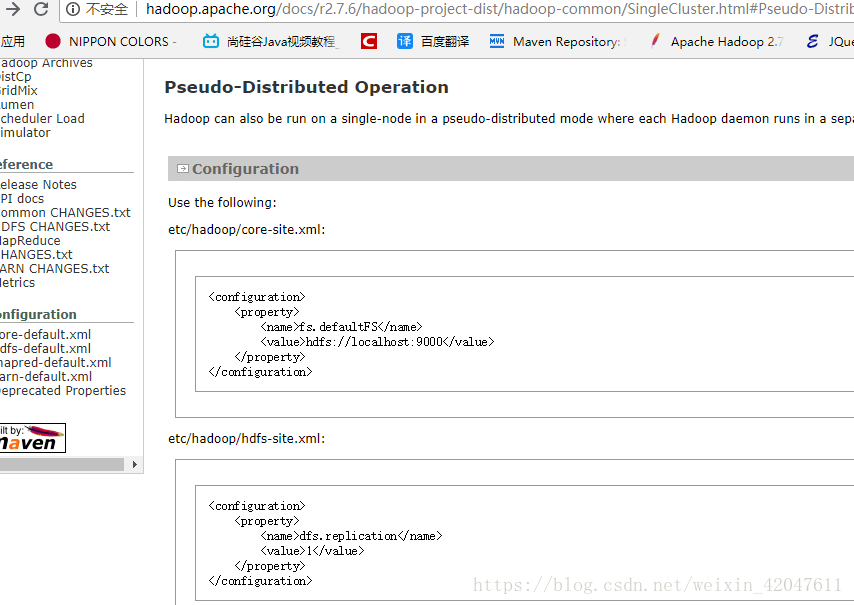
a、common模块:core-site.xml
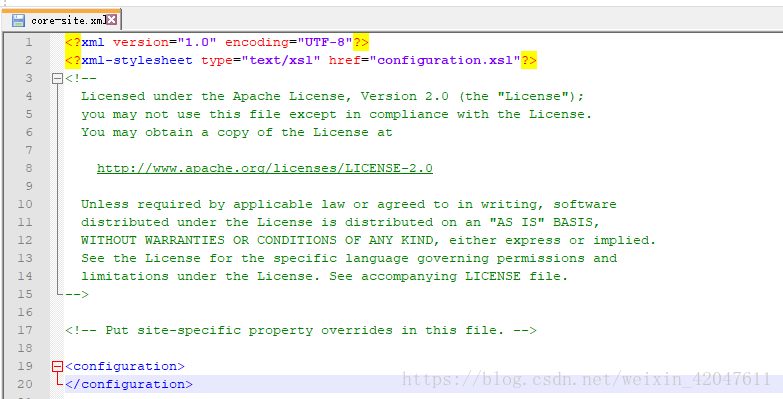


fs.defaultFS hdfs://bigdata-training01.huadian.com:8020 hadoop.tmp.dir /opt/moduls/hadoop-2.7.3/etc/hadoop/data/tempData
b、HDFS模块配置:hdfs-site.xml
dfs.replication 1
配置slaves:指定小弟DataNode运行在那台机器上,如果有多个小弟,一行一个

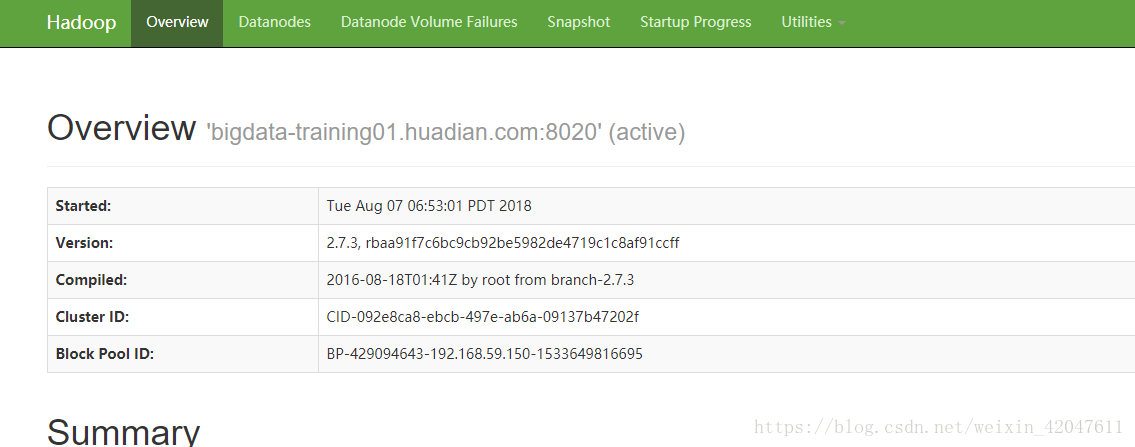
c、测试HDFS模块是否OK
-》格式化
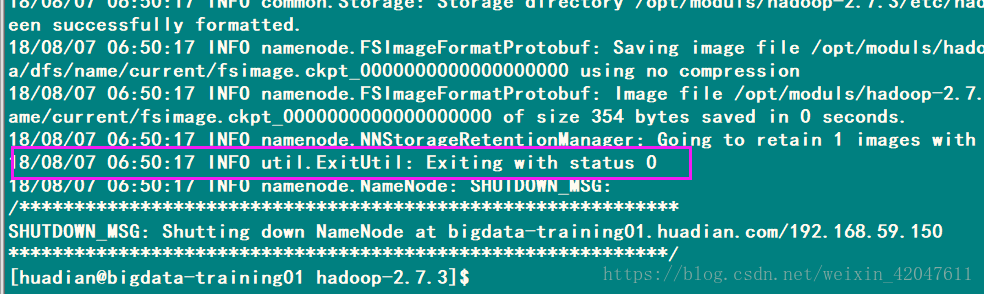
当status为0的时候,为格式化成功。
-》启动
主节点

从节点

启动的这些服务相当于一个一个的Java进程,所以当执行启动命令之后,需要查看一下是否启动成功。
-》验证是否成功: 方式一:查看进程jps
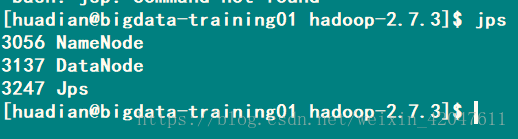
-》测试HDFS: (1)怎么用 bin/hdfs dfs
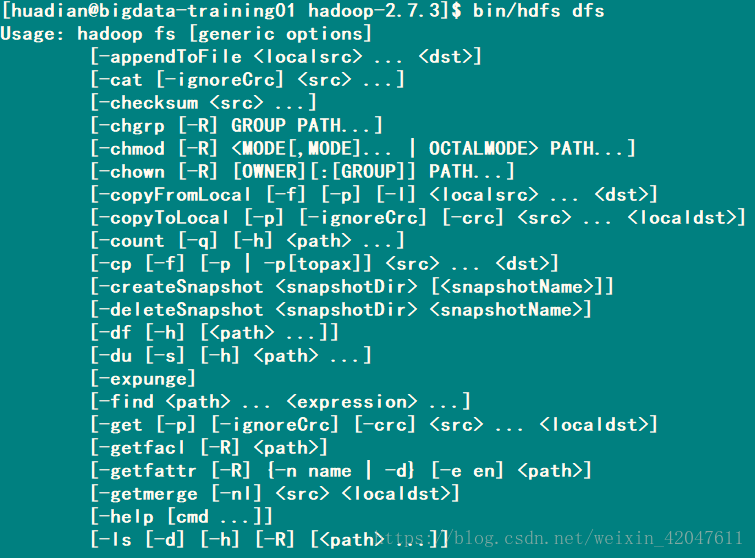



新写一个文件,上传到hdfs




d、YARN 对于分布式资源管理和任务调度框架来说,在YARN上可以运行多种应用程序 - MapReduce - spark - tez (1) 配置:yarn-site.xml
yarn.resourcemanager.hostname bigdata-training01.huadian.com yarn.nodemanager.aux-services mapreduce_shuffle
(2)slaves 指定nodemanager运行的主机名名称,由于NameNode和 DataNode在同一台机器上,前面已经配置,所以不用再去配置。
e、启动YARN服务 -》启动: 主节点ResourceManager: sbin/yarn-daemon.sh start resourcemanager 从节点NodeManager: sbin/yarn-daemon.sh start nodemanager
-》验证启动: 方式一:jps 方式二:bigdata-training01.huadian.com:8088

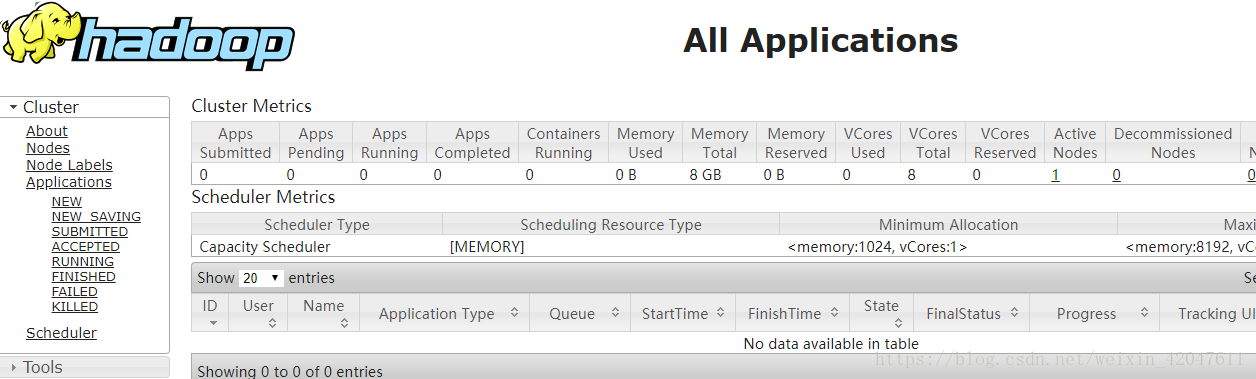
f、MapReduce模块 并行计算的一个框架。 思想:分而治之 核心:map:分 并行处理数据,将数据分割,一部分一部分的处理 reduce:合 将Map处理数据的结果进行合并。
配置: 第一步:将模板重命名为xml文件
mapreduce.framework.name yarn
g、测试MapReduce程序
案例:wordcount程序 Hadoop提供了一个程序,为我们统计。
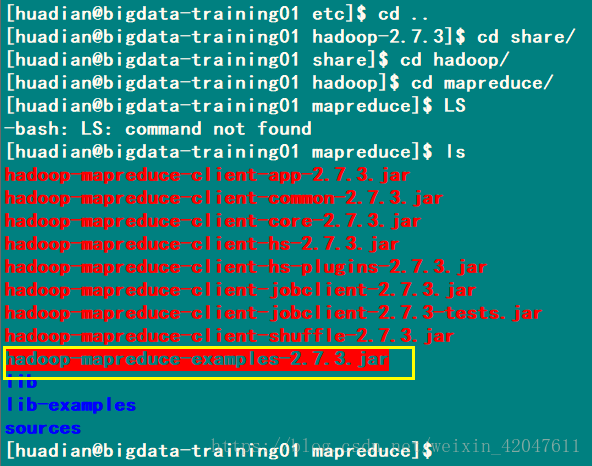
准备数据:在/datas/input.data

将MapReduce应用提交到YARN上运行。
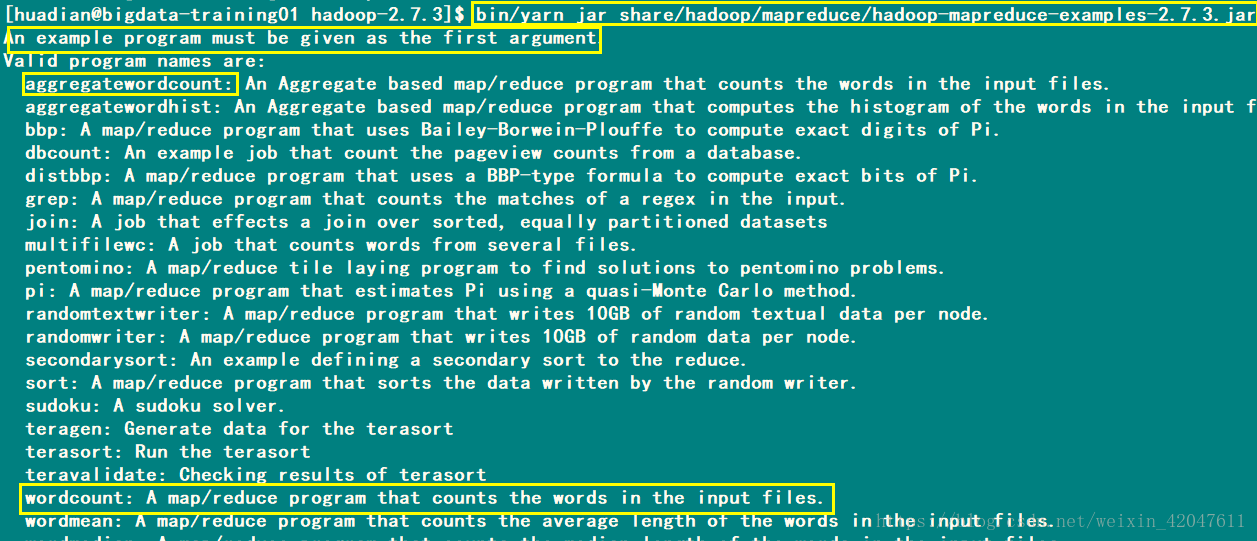
bin/yarn jar share/hadoop/mapreduce/hadoop-mapreduce-examples-2.7.3.jar wordcount Usage: wordcount <in> [<in>...] <out> <in>:表示MapReduce程序要处理的数据在哪里
<out>:表示MapReduce程序处理数据之后的结果,存储在哪里,这个目录不能存在。 bin/yarn jar share/hadoop/mapreduce/hadoop-mapreduce-examples-2.7.3.jar wordcount /datas/input.data /datas/output/output001








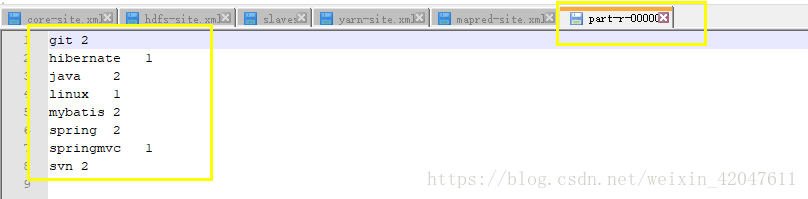
额外配置:历史服务器 HistoryServer mapred-site.xml 后面添加:
mapreduce.jobhistory.address bigdata-training01.huadian.com:10020 mapreduce.jobhistory.webapp.address bigdata-training01.huadian.com:19888
启动服务:sbin/mr-jobhistory-daemon.sh start historyserver
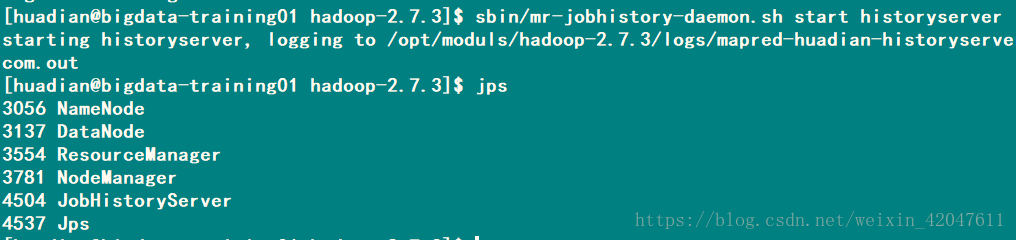
日志聚集功能 YARN提供日志中央化管理功能,他能将运行完成的任务 日志 上传到HDFS指定目录下。 以便后期监控查看 配置:yarn-site.xml
yarn.log-aggregation-enable true yarn.log-aggregation.retain-seconds 604800
注意:重启YARN和JobHistoryServer服务, 修改了配置文件,需要重新读取

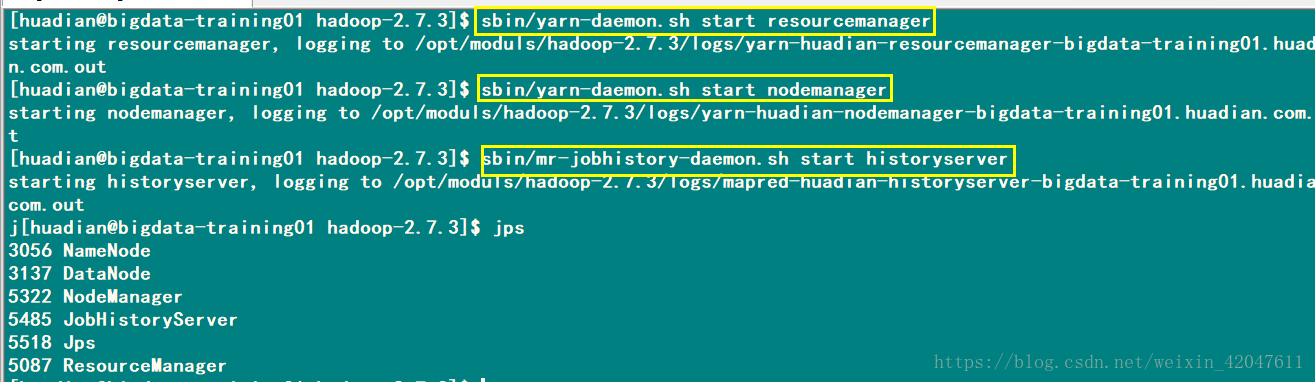


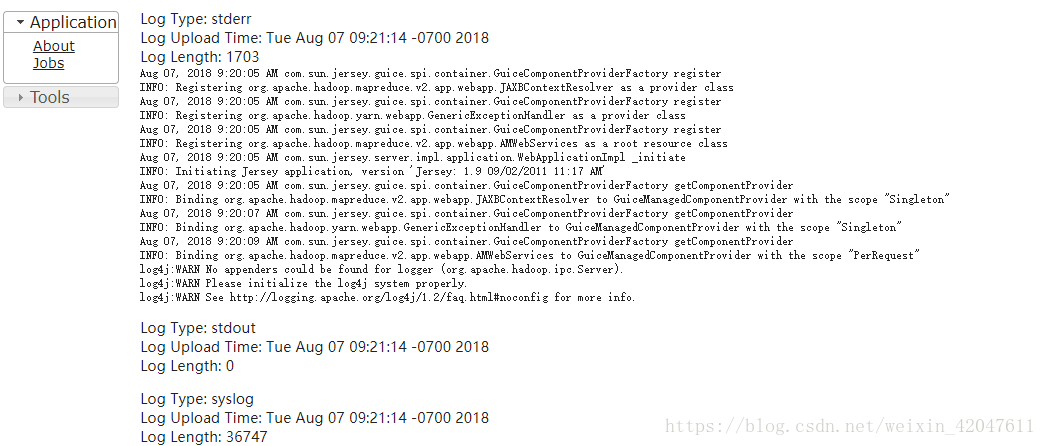
如果格式化、启动某个进程失败,怎么办???? 看日志文件。。。。就是IDEA控制台的输出
发表评论
最新留言
关于作者
