本文共 20128 字,大约阅读时间需要 67 分钟。
之前的博文,《》里有一些关于线程的基础知识。
1)什么是并发?
指多个线程操作同一个资源,不是同时操作,而是交替操作,只不过因为速度太快,看起来是同时执行(单核 /多核CPU均是如此,因为通常任务的数量远远多于CPU的核数,所以任务最终也是交替执行的)。
通过时间片轮转机制RR(CPU时间片轮转机制,cpu给每个进程分配一个“时间段”,这个时间就是这个进程允许运行的时间,如果当这个进程的时间片段结束/阻塞,操作系统就会把分配给这个进程的cpu剥夺,分配给另外一个进程。)调度实现并发。
好处:高并发编程可以充分利用cpu的资源;可以充分地加快用户的响应时间;可以使我们的代码模块化、异步化。
坏处:线程之间会共享进程的资源,既然说是共享资源,就有可能存在冲突;在高并发编程中如果控制不好,还有可能会造成线程的死锁(无限等待,唯有强制结束进程)。
2)创建新线程
Java程序中默认有两个线程——main线程和GC线程;Android中默认有一个主线程,除此之外的线程都需要创建。
① 类Thread
② 接口Runnable(推荐使用这种,因为接口可以多实现) ③ 接口Callable:与Runnable的区别是,实现Runnabble接口里的run方法是没有返回值的,而Callable是允许有返回值的。
public class Test { private static class RunnableThread implements Runnable { @Override public void run() { System.out.println("实现Runnable方式创建线程"); System.out.println("thread run..."); System.out.println("thread end."); } } private static class CallableThread implements Callable { @Override public String call() throws Exception { return "this is return result"; } } public static void main(String[] args) throws ExecutionException, InterruptedException { System.out.println("main start..."); RunnableThread runnableThread = new RunnableThread(); //要启动实现Runnablede的线程的话还需要把runnable的实例传到Thread里 new Thread(runnableThread).start(); CallableThread callableThread = new CallableThread(); //由于new Thread只接受Runnable类型的构造参数,所以要先把Callable包装一下 FutureTask futureTask = new FutureTask<>(callableThread); new Thread(futureTask).start(); //获取返回值,get方法是阻塞的 System.out.println(futureTask.get()); System.out.println("main end..."); }} 思考一个问题,上面的例子中使用线程执行的打印语句,和直接在main()方法执行的打印语句有区别吗?
—— 除了可以肯定,main start会先打印外,main end打印在thread run之前、thread end之后或者之间,都无法确定。因为从t线程开始运行以后,两个线程就开始同时运行了,并且由操作系统调度,程序本身无法确定线程的调度顺序。要模拟并发执行的效果,我们可以在线程中调用Thread.sleep(),强迫当前线程暂停一段时间:
private static class RunnableThread implements Runnable { @Override public void run() { System.out.println("实现Runnable方式创建线程"); try { Thread.sleep(20); } catch (InterruptedException e) {} System.out.println("thread end."); } } } 线程的优先级,可以对线程设定优先级,设定优先级的方法是:
Thread.setPriority(int n) // 1~10, 默认值5
优先级高的线程被操作系统调度的优先级较高,操作系统对高优先级线程可能调度更频繁,但我们决不能通过设置优先级来确保高优先级的线程一定会先执行。
3)线程的状态
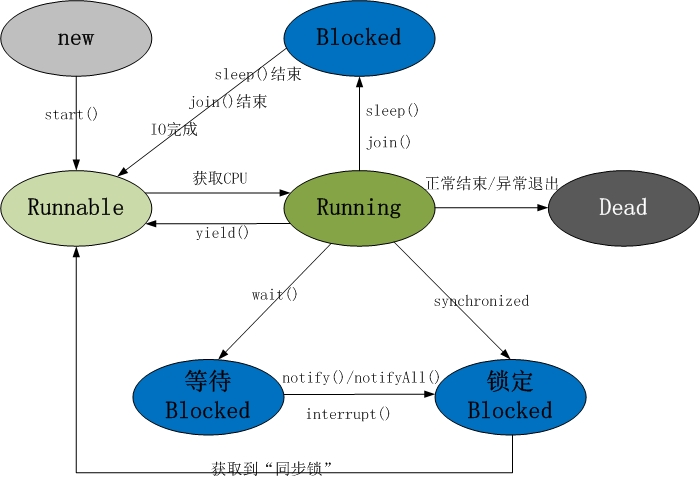
线程共包括以下 5 种状态:
1. 新建状态(New): 线程对象被创建后,就进入了新建状态。例如,Thread thread = new Thread()。
2. 就绪状态(Runnable): 也被称为“可执行状态”。线程对象被创建后,其它线程调用了该对象的start()方法,从而来启动该线程。例如,thread.start()。处于就绪状态的线程,随时可能被CPU调度执行。
3. 运行状态(Running): 线程获取CPU权限进行执行。需要注意的是,线程只能从就绪状态进入到运行状态。
4. 阻塞状态(Blocked): 阻塞状态是线程因为某种原因放弃CPU使用权,暂时停止运行。直到线程进入就绪状态,才有机会转到运行状态。阻塞的情况分三种:
等待阻塞 -- 通过调用线程的wait()方法,让线程等待某工作的完成。
同步阻塞 -- 线程在获取synchronized同步锁失败(因为锁被其它线程所占用),它会进入同步阻塞状态。
其他阻塞 -- 通过调用线程的sleep()或join()或发出了I/O请求时,线程会进入到阻塞状态。当sleep()状态超时、join()等待线程终止或者超时、或者I/O处理完毕时,线程重新转入就绪状态。
5. 死亡状态(Dead): 线程执行完了或者因异常退出了run()方法,该线程结束生命周期。
比如,一个线程需等待另一个线程直到其运行结束。如下main线程在启动t线程后,可以通过t.join()等待t线程结束后再继续运行:
public class Main { public static void main(String[] args) throws InterruptedException { Thread t = new Thread(() -> { System.out.println("hello"); }); System.out.println("start"); t.start(); t.join(); System.out.println("end"); }} 当main线程对线程对象t调用join()方法时,主线程将等待变量t表示的线程运行结束,即join就是指等待该线程结束,然后才继续往下执行自身线程。所以,上述代码打印顺序可以肯定是main线程先打印start,t线程再打印hello,main线程最后再打印end。
如果t线程已经结束,对实例t调用join()会立刻返回。此外,join(long)的重载方法也可以指定一个等待时间,超过等待时间后就不再继续等待。
4)中断线程
方法执行完自动终止 / 抛出异常,又没有捕获异常,此时线程自己中断;如果需要中断线程,有两种处理方法:
第一种中断线程的方法,调用Thread类内的方法,如下:
public void interrupt() { throw new RuntimeException("Stub!"); } public static native boolean interrupted(); public native boolean isInterrupted(); ① interrupt():作用终止一个线程,但并不是强行关闭一个线程(java的线程是协作式的,不是强迫式的,调用一个线程的interrupt()方法并不会强制关闭一个线程,它就好比其他线程对要关闭的线程打了一声招呼,告诉被关闭线程它要中断了,但被关闭线程什么时候关闭完全由它自身做主),线程调用该方法并不会立刻终止。它的目的是把线程中的“中断标志位”置为true
② isInterrupted(),判定当前线程是否处于中断状态。通过这个方法判断中断标志位是否为true。 ③ 静态方法interrupted(), 也是判断当前线程是否处于中断状态。当调用此方法时,它会把中断标志位改为false。需要注意的是,当线程中调用了wait(),join(),sleep()方法时,方法会抛出InterruptedException,这个时候线程的中断标志会被复位成为false,所以这个时候我们应该在catch里面再调用一次interrupt(),再次中断一次。public class HasInterrputException { private static final String TAG = "HasInterrputException"; private static class UseThread extends Thread { public UseThread(String name) { super(name); } @Override public void run() { String threadName = Thread.currentThread().getName(); while (!isInterrupted()) { try { Thread.sleep(100); } catch (InterruptedException e) { Log.d(TAG, "run 00: " + threadName + " catch interrput flag is " + isInterrupted()); interrupt(); e.printStackTrace(); } Log.d(TAG, "run 11: " + threadName); System.out.println(threadName); } Log.d(TAG, "run 22: " + threadName + " interrput flag is " + isInterrupted()); } } public static void main(String[] args) throws InterruptedException { Thread endThread = new UseThread("HasInterrputEx"); endThread.start(); Thread.sleep(20); endThread.interrupt(); UseRunnable useRunnable = new UseRunnable(); Thread endThread = new Thread(useRunnable, "endThread"); endThread.start(); Thread.sleep(1); endThread.interrupt(); } private static class UseRunnable implements Runnable { @Override public void run() { while (!Thread.currentThread().isInterrupted()) { Log.d(TAG, "run 33: " + "Thread " + Thread.currentThread().getName() + " is running."); try { Thread.sleep(1000); } catch (InterruptedException e) { Log.d(TAG, "run 44: " + e.getMessage()); e.printStackTrace(); Thread.currentThread().interrupt(); } } } }} 第二种中断线程的方法,设置标记位。我们通常会用一个running标志位来标识线程是否应该继续运行,在外部线程中,通过把HelloThread.running置为false,就可以让线程结束:
public class Main { public static void main(String[] args) throws InterruptedException { HelloThread t = new HelloThread(); t.start(); Thread.sleep(1); t.running = false; // 标志位置为false }}class HelloThread extends Thread { public volatile boolean running = true; public void run() { int n = 0; while (running) { n ++; System.out.println(n + " hello!"); } System.out.println("end!"); }} 4.1)volatile关键字
注意到HelloThread的标志位boolean running是一个线程间共享的变量。线程间共享变量需要使用volatile关键字标记,确保每个线程都能读取到更新后的变量值。
为什么要对线程间共享的变量用关键字volatile声明?这涉及到Java的内存模型。在Java虚拟机中,变量的值保存在主内存中,但是,当线程访问变量时,它会先获取一个副本,并保存在自己的工作内存中。如果线程修改了变量的值,虚拟机会在某个时刻把修改后的值回写到主内存,但是,这个时间是不确定的!
这会导致如果一个线程更新了某个变量,另一个线程读取的值可能还是更新前的。例如,主内存的变量a = true,线程1执行a = false时,它在此刻仅仅是把变量a的副本变成了false,主内存的变量a还是true,在JVM把修改后的a回写到主内存之前,其他线程读取到的a的值仍然是true,这就造成了多线程之间共享的变量不一致。
因此,volatile关键字的目的是告诉虚拟机:
- 每次访问变量时,总是获取主内存的最新值;
- 每次修改变量后,立刻回写到主内存。
volatile关键字解决的是可见性问题:当一个线程修改了某个共享变量的值,其他线程能够立刻看到修改后的值(适用于一个线程写,多个线程读这种场景)。
如果我们去掉volatile关键字,运行上述程序,发现效果和带volatile差不多,这是因为在x86的架构下,JVM回写主内存的速度非常快,但是,换成ARM的架构,就会有显著的延迟。
5)守护线程
Java程序入口就是由JVM启动main线程,main线程又可以启动其他线程。当所有线程都运行结束时,JVM退出,进程结束。
如果有一个线程没有退出,JVM进程就不会退出。所以,必须保证所有线程都能及时结束。
守护线程通过调用接口实现设置,setDaemon(boolean on),参数boolean类型,true则是守护线程,false则不是守护线程;
public static void main(String[] arg0) { System.out.println("main start====="); Thread thread1 = new Thread("守护线程"){ @Override public void run() { int i = 0; while (i <= 4){ i++; try { Thread.sleep(500); } catch (InterruptedException e) { e.printStackTrace(); } System.out.println(Thread.currentThread().getName()+":"+i); } super.run(); } }; Thread thread2 = new Thread("用户线程"){ @Override public void run() { int i = 0; while (i <= 2){ i++; try { Thread.sleep(500); } catch (InterruptedException e) { e.printStackTrace(); } System.out.println(Thread.currentThread().getName()+":"+i); } super.run(); } }; //setDaemon, 不设置则默认false thread1.setDaemon(true);//设置thread1为守护线程 thread2.setDaemon(false);//设置thread2为普通线程 thread1.start(); thread2.start(); System.out.println("main end=="); } main start=====main end==用户线程:1守护线程:1守护线程:2用户线程:2守护线程:3用户线程:3
- 主线程,main执行结束后,普通线程可以继续执行直至执行完毕;
- 用户线程执行完毕后,守护线程立刻结束;
守护线程是指为其他线程服务的线程。在JVM中,所有非守护线程都执行完毕后,无论有没有守护线程,虚拟机都会自动退出。因此,JVM退出时,不必关心守护线程是否已结束。在守护线程中,编写代码要注意:守护线程不能持有任何需要关闭的资源,例如打开文件等,因为虚拟机退出时,守护线程没有任何机会来关闭文件,这会导致数据丢失。
6)线程同步-synchronized
当多个线程同时运行时,线程的调度由操作系统决定,程序本身无法决定。因此,任何一个线程都有可能在任何指令处被操作系统暂停,然后在某个时间段后继续执行。
这个时候,有个单线程模型下不存在的问题就来了:如果多个线程同时读写共享变量,会出现数据不一致的问题。
public class Main { public static void main(String[] args) throws Exception { var add = new AddThread(); var dec = new DecThread(); add.start(); dec.start(); add.join(); dec.join(); System.out.println(Counter.count); }}class Counter { public static int count = 0;}class AddThread extends Thread { public void run() { for (int i=0; i<10000; i++) { Counter.count += 1; } }}class DecThread extends Thread { public void run() { for (int i=0; i<10000; i++) { Counter.count -= 1; } }} 两个线程同时对一个int变量进行操作,一个加10000次,一个减10000次,最后结果应该是0,但是,每次运行,结果实际上都是不一样的。
这是因为对变量进行读取和写入时,结果要正确,必须保证是原子操作。原子操作是指不能被中断的一个或一系列操作。
多线程模型下,要保证逻辑正确,对共享变量进行读写时,必须保证一组指令以原子方式执行:即某一个线程执行时,其他线程必须等待:
┌───────┐ ┌───────┐│Thread1│ │Thread2│└───┬───┘ └───┬───┘ │ │ │-- lock -- │ │ILOAD (100) │ │IADD │ │ISTORE (101) │ │-- unlock -- │ │ │-- lock -- │ │ILOAD (101) │ │IADD │ │ISTORE (102) │ │-- unlock -- ▼ ▼
通过加锁和解锁的操作,就能保证一份连续指令总是在一个线程执行期间,不会有其他线程会进入此指令区间。即使在执行期线程被操作系统中断执行,其他线程也会因为无法获得锁导致无法进入此指令区间。只有执行线程将锁释放后,其他线程才有机会获得锁并执行。这种加锁和解锁之间的代码块我们称之为临界区(Critical Section),任何时候临界区最多只有一个线程能执行。
可见,保证一段代码的原子性就是通过加锁和解锁实现的。Java程序使用synchronized关键字对一个对象进行加锁,synchronized保证了代码块在任意时刻最多只有一个线程能执行。我们把上面的代码用synchronized改写如下:
public class Main { public static void main(String[] args) throws Exception { var add = new AddThread(); var dec = new DecThread(); add.start(); dec.start(); add.join(); dec.join(); System.out.println(Counter.count); }}class Counter { public static final Object lock = new Object(); public static int count = 0;}class AddThread extends Thread { public void run() { for (int i=0; i<10000; i++) { synchronized(Counter.lock) { Counter.count += 1; } } }}class DecThread extends Thread { public void run() { for (int i=0; i<10000; i++) { synchronized(Counter.lock) { Counter.count -= 1; } } }} synchronized(Counter.lock) { // 获取锁 ...} // 释放锁 它表示用Counter.lock实例作为锁,两个线程在执行各自的synchronized(Counter.lock) { ... }代码块时,必须先获得锁,才能进入代码块进行。执行结束后,在synchronized语句块结束会自动释放锁。这样一来,对Counter.count变量进行读写就不可能同时进行。上述代码无论运行多少次,最终结果都是0。
使用synchronized解决了多线程同步访问共享变量的正确性问题。但是,它的缺点是带来了性能下降。因为synchronized代码块无法并发执行。此外,加锁和解锁需要消耗一定的时间,所以,synchronized会降低程序的执行效率。
我们来概括一下如何使用synchronized:
- 找出修改共享变量的线程代码块;
- 选择一个共享实例作为锁;
- 使用
synchronized(lockObject) { ... }。
在使用synchronized的时候,不必担心抛出异常。因为无论是否有异常,都会在synchronized结束处正确释放锁。
小结
多线程同时读写共享变量时,会造成逻辑错误,因此需要通过
synchronized同步;同步的本质就是给指定对象加锁,加锁后才能继续执行后续代码;
注意加锁对象必须是同一个实例;
7)同步方法
Java程序依靠synchronized对线程进行同步,使用synchronized的时候,锁住的是哪个对象非常重要。
让线程自己选择锁对象往往会使得代码逻辑混乱,也不利于封装。更好的方法是把synchronized逻辑封装起来。例如,我们编写一个计数器如下:
public class Counter { private int count = 0; public void add(int n) { synchronized(this) { count += n; } } public void dec(int n) { synchronized(this) { count -= n; } } public int get() { return count; }} 这样一来,线程调用add()、dec()方法时,它不必关心同步逻辑,因为synchronized代码块在add()、dec()方法内部。并且,我们注意到,synchronized锁住的对象是this,即当前实例,这又使得创建多个Counter实例的时候,它们之间互不影响,可以并发执行:
var c1 = Counter();var c2 = Counter();// 对c1进行操作的线程:new Thread(() -> { c1.add();}).start();// 对c2进行操作的线程:new Thread(() -> { c2.add();}).start(); 现在,对于Counter类,多线程可以正确调用。
如果一个类被设计为允许多线程正确访问,我们就说这个类就是“线程安全”的(thread-safe),上面的Counter类就是线程安全的。Java标准库的java.lang.StringBuffer也是线程安全的。
还有一些不变类,例如String,Integer,LocalDate,它们的所有成员变量都是final,多线程同时访问时只能读不能写,这些不变类也是线程安全的。
最后,类似Math这些只提供静态方法,没有成员变量的类,也是线程安全的。
除了上述几种少数情况,大部分类,例如ArrayList,都是非线程安全的类,我们不能在多线程中修改它们。但是,如果所有线程都只读取,不写入,那么ArrayList是可以安全地在线程间共享的。
没有特殊说明时,一个类默认是非线程安全的。
当我们锁住的是this实例时,实际上可以用synchronized修饰这个方法。下面两种写法是等价的:
public void add(int n) { synchronized(this) { // 锁住this count += n; } // 解锁}public synchronized void add(int n) { // 锁住this count += n;} // 解锁 因此,用synchronized修饰的方法就是同步方法,它表示整个方法都必须用this实例加锁。
我们再思考一下,如果对一个静态方法添加synchronized修饰符,它锁住的是哪个对象?
public synchronized static void test(int n) { ...}public class Counter { public static void test(int n) { synchronized(Counter.class) { ... } }} 对于static方法,是没有this实例的,因为static方法是针对类而不是实例。但是我们注意到任何一个类都有一个由JVM自动创建的Class实例,因此,对static方法添加synchronized,锁住的是该类的Class实例。上面两种写法也是等效的。
7)死锁
JVM允许同一个线程重复获取同一个锁,这种能被同一个线程反复获取的锁,就叫做可重入锁。一个线程可以获取一个锁后,再继续获取另一个锁。例如:
public void add(int m) { synchronized(lockA) { // 获得lockA的锁 this.value += m; synchronized(lockB) { // 获得lockB的锁 this.another += m; } // 释放lockB的锁 } // 释放lockA的锁}public void dec(int m) { synchronized(lockB) { // 获得lockB的锁 this.another -= m; synchronized(lockA) { // 获得lockA的锁 this.value -= m; } // 释放lockA的锁 } // 释放lockB的锁} 在获取多个锁的时候,不同线程获取多个不同对象的锁可能导致死锁。对于上述代码,线程1和线程2如果分别执行add()和dec()方法时:
- 线程1:进入
add(),获得lockA; - 线程2:进入
dec(),获得lockB。
随后:
- 线程1:准备获得
lockB,失败,等待中; - 线程2:准备获得
lockA,失败,等待中。
此时,两个线程各自持有不同的锁,然后各自试图获取对方手里的锁,造成了双方无限等待下去,这就是死锁。
死锁发生后,没有任何机制能解除死锁,只能强制结束JVM进程。
因此,在编写多线程应用时,要特别注意防止死锁。因为死锁一旦形成,就只能强制结束进程。
那么我们应该如何避免死锁呢?答案是:线程获取锁的顺序要一致。即严格按照先获取lockA,再获取lockB的顺序,改写dec()方法如下:
public void dec(int m) { synchronized(lockA) { // 获得lockA的锁 this.value -= m; synchronized(lockB) { // 获得lockB的锁 this.another -= m; } // 释放lockB的锁 } // 释放lockA的锁} 8)使用wait和notify
在Java程序中,synchronized解决了多线程竞争的问题。例如,对于一个任务管理器,多个线程同时往队列中添加任务,可以用synchronized加锁:
class TaskQueue { Queue queue = new LinkedList<>(); public synchronized void addTask(String s) { this.queue.add(s); }} 但是synchronized并没有解决多线程协调的问题。
仍然以上面的TaskQueue为例,我们再编写一个getTask()方法取出队列的第一个任务:
class TaskQueue { Queue queue = new LinkedList<>(); public synchronized void addTask(String s) { this.queue.add(s); } public synchronized String getTask() { while (queue.isEmpty()) { } return queue.remove(); }} 上述代码看上去没有问题:getTask()内部先判断队列是否为空,如果为空,就循环等待,直到另一个线程往队列中放入了一个任务,while()循环退出,就可以返回队列的元素了。
但实际上while()循环永远不会退出。因为线程在执行while()循环时,已经在getTask()入口获取了this锁,其他线程根本无法调用addTask(),因为addTask()执行条件也是获取this锁。
因此,执行上述代码,线程会在getTask()中因为死循环而100%占用CPU资源。
如果深入思考一下,我们想要的执行效果是:
- 线程1可以调用
addTask()不断往队列中添加任务; - 线程2可以调用
getTask()从队列中获取任务。如果队列为空,则getTask()应该等待,直到队列中至少有一个任务时再返回。
因此,多线程协调运行的原则就是:当条件不满足时,线程进入等待状态;当条件满足时,线程被唤醒,继续执行任务。
对于上述TaskQueue,我们先改造getTask()方法,在条件不满足时,线程进入等待状态:
public synchronized String getTask() { while (queue.isEmpty()) { this.wait(); } return queue.remove();} 当一个线程执行到getTask()方法内部的while循环时,它必定已经获取到了this锁,此时,线程执行while条件判断,如果条件成立(队列为空),线程将执行this.wait(),进入等待状态。
这里的关键是:wait()方法必须在当前获取的锁对象上调用,这里获取的是this锁,因此调用this.wait()。
调用wait()方法后,线程进入等待状态,wait()方法不会返回,直到将来某个时刻,线程从等待状态被其他线程唤醒后,wait()方法才会返回,然后,继续执行下一条语句。
当一个线程在this.wait()等待时,它就会释放this锁,从而使得其他线程能够在addTask()方法获得this锁。
现在我们面临第二个问题:如何让等待的线程被重新唤醒,然后从wait()方法返回?答案是在相同的锁对象上调用notify()方法。我们修改addTask()如下:
public synchronized void addTask(String s) { this.queue.add(s); this.notify(); // 唤醒在this锁等待的线程} 注意到在往队列中添加了任务后,线程立刻对this锁对象调用notify()方法,这个方法会唤醒一个正在this锁等待的线程(就是在getTask()中位于this.wait()的线程),从而使得等待线程从this.wait()方法返回。
完整的例子:
public class Main { public static void main(String[] args) throws InterruptedException { var q = new TaskQueue(); var ts = new ArrayList (); for (int i=0; i<5; i++) { var t = new Thread() { public void run() { // 执行task: while (true) { try { String s = q.getTask(); System.out.println("execute task: " + s); } catch (InterruptedException e) { return; } } } }; t.start(); ts.add(t); } var add = new Thread(() -> { for (int i=0; i<10; i++) { // 放入task: String s = "t-" + Math.random(); System.out.println("add task: " + s); q.addTask(s); try { Thread.sleep(100); } catch(InterruptedException e) {} } }); add.start(); add.join(); Thread.sleep(100); for (var t : ts) { t.interrupt(); } }}class TaskQueue { Queue queue = new LinkedList<>(); public synchronized void addTask(String s) { this.queue.add(s); this.notifyAll(); } public synchronized String getTask() throws InterruptedException { while (queue.isEmpty()) { this.wait(); } return queue.remove(); }} 这个例子中,我们重点关注addTask()方法,内部调用了this.notifyAll()而不是this.notify(),使用notifyAll()将唤醒所有当前正在this锁等待的线程,而notify()只会唤醒其中一个(具体哪个依赖操作系统,有一定的随机性)。这是因为可能有多个线程正在getTask()方法内部的wait()中等待,使用notifyAll()将一次性全部唤醒。通常来说,notifyAll()更安全。有些时候,如果我们的代码逻辑考虑不周,用notify()会导致只唤醒了一个线程,而其他线程可能永远等待下去醒不过来了。
但是,注意到wait()方法返回时需要重新获得this锁。假设当前有3个线程被唤醒,唤醒后,首先要等待执行addTask()的线程结束此方法后,才能释放this锁,随后,这3个线程中只能有一个获取到this锁,剩下两个将继续等待。
9)使用ThreadLocal
对于多任务,Java标准库提供的线程池可以方便地执行这些任务,同时复用线程。Web应用程序就是典型的多任务应用,每个用户请求页面时,我们都会创建一个任务,类似:
public void process(User user) { checkPermission(); doWork(); saveStatus(); sendResponse();} 然后,通过线程池去执行这些任务。
观察process()方法,它内部需要调用若干其他方法,同时,我们遇到一个问题:如何在一个线程内传递状态?
process()方法需要传递的状态就是User实例。简单地传入User就可以了?
public void process(User user) { checkPermission(user); doWork(user); saveStatus(user); sendResponse(user);} 但是往往一个方法又会调用其他很多方法,这样会导致User传递到所有地方:
void doWork(User user) { queryStatus(user); checkStatus(); setNewStatus(user); log();} 这种在一个线程中,横跨若干方法调用,需要传递的对象,我们通常称之为上下文(Context),它是一种状态,可以是用户身份、任务信息等。
给每个方法增加一个context参数非常麻烦,而且有些时候,如果调用链有无法修改源码的第三方库,User对象就传不进去了。
Java标准库提供了一个特殊的ThreadLocal,它可以在一个线程中传递同一个对象。
ThreadLocal实例通常总是以静态字段初始化如下:
static ThreadLocalthreadLocalUser = new ThreadLocal<>();
void processUser(user) { try { threadLocalUser.set(user); step1(); step2(); } finally { threadLocalUser.remove(); }} 通过设置一个User实例关联到ThreadLocal中,在移除之前,所有方法都可以随时获取到该User实例:
void step1() { User u = threadLocalUser.get(); log(); printUser();}void log() { User u = threadLocalUser.get(); println(u.name);}void step2() { User u = threadLocalUser.get(); checkUser(u.id);} 注意到普通的方法调用一定是同一个线程执行的,所以,step1()、step2()以及log()方法内,threadLocalUser.get()获取的User对象是同一个实例。实际上,可以把ThreadLocal看成一个全局Map<Thread, Object>:每个线程获取ThreadLocal变量时,总是使用Thread自身作为key。ThreadLocal相当于给每个线程都开辟了一个独立的存储空间,各个线程的ThreadLocal关联的实例互不干扰。
最后,特别注意ThreadLocal一定要在finally中清除:
try { threadLocalUser.set(user); ...} finally { threadLocalUser.remove();} 这是因为当前线程执行完相关代码后,很可能会被重新放入线程池中,如果ThreadLocal没有被清除,该线程执行其他代码时,会把上一次的状态带进去。
参考文章:
《》
《》
《》
《》
《》
《》
发表评论
最新留言
关于作者
