本文共 4013 字,大约阅读时间需要 13 分钟。
文章目录
一、锁的优化及注意事项
锁是最常用的同步方法之一。在高并发的环境下,激烈的锁竞争会导致程序的性能下降,因此我们有必要讨论一些有关锁的性能问题,以及一些注意事项,比如避免死锁、减小锁粒度、锁分离等。
在多核时代,使用多线程可以明显地提高系统的性能,但是也会额外增加系统的开销。
对于单任务或者单线程的应用而言,其主要资源消耗都花在任务本身。它既不需要维护并行数据结构间的一致性状态,也不需要为线程的切换和调度花费时间。但对于多线程应用来说,系统除了处理功能需求外,还需要额外维护多线程环境的特有信息,如线程本身的元数据、线程的调度、线程上下文的切换等。
事实上,在单核CPU上采用并行算法的效率一般要低于原始的串行算法的效率,其根本原因也在于此。因此,并行计算之所以能提高系统的性能,并不是因为它“少干活”了,而是因为并行计算可以更合理地进行任务调度,充分利用各个CPU资源。因此,合理的并发,才能将多核CPU的性能发挥到极致。
锁的竞争必然会导致程序的整体性能下降。为了将这种副作用降到最低,这里提出一些关于使用锁的建议,希望可以帮助大家写出性能更高的程序。
二、减少锁持有时间
对于使用锁进行并发控制的应用程序而言,在锁竞争过程中,单个线程对锁的持有时间与系统性能有着直接的关系。如果线程持有锁的时间越长,那么相对地,锁的竞争程度也就越激烈。可以想象一下,如果要求100个人各自填写自己的身份信息,但是只给他们一支笔,那么如果每个人拿着笔的时间都很长,总体所花的时间就会很长。如果真的只有一支笔共享给100个人用,那么最好让每个人花尽量少的时间持笔,务必做到想好了再拿笔写,千万不能拿着笔才去思考这表格应该怎么填。程序开发也是类似的,应该尽可能地减少对某个锁的占有时间,以减少线程间互斥的可能。以下面的代码段为例:
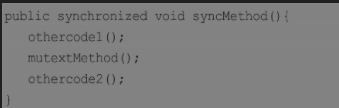
syncMethod()方法中,假设只有mutextMethod()方法是有同步需要的,而othercode1()方法和othercode2()方法并不需要做同步控制。如果othercode1()和othercode2()分别是重量级的方法,则会花费较长的CPU时间。如果在并发量较大时,使用这种对整个方法做同步的方案,则会导致等待线程大量增加。因为一个线程,在进入该方法时获得内部锁,只有在所有任务都执行完后,才会释放锁。 一个较为优化的解决方案是,只在必要时进行同步,这样就能明显减少线程持有锁的时间,提高系统的吞吐量。
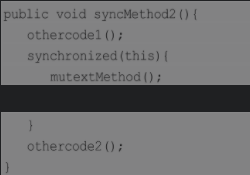
mutextMethod()方法做了同步,锁占用的时间相对较短,因此能有更高的并行度。这种技术手段在JDK的源码包中也可以很容易地找到,比如处理正则表达式的Pattern类。 
matcher()方法有条件地进行锁申请,只有在表达式未编译时,进行局部的加锁。这种处理方式大大提高了matcher()方法的执行效率和可靠性。 注意:减少锁的持有时间有助于降低锁冲突的可能性,进而提升系统的并发能力
三、减小锁粒度
减小锁粒度也是一种削弱多线程锁竞争的有效手段。这种技术典型的使用场景就是ConcurrentHashMap类的实现。大家应该还记得这个类吧!在“3.3不要重复发明轮子:JDK的并发容器”一节中介绍过这个高性能的HashMap,但是当时我们并没有说明它的实现原理。这里,让我们更加细致地看一下这个类。
对于HashMap来说,最重要的两个方法就是get()和put()。一种最自然的想法就是,对整个HashMap加锁从而得到一个线程安全的对象,但是这样做,加锁粒度太大。对于ConcurrentHashMap类,它内部进一步细分了若干个小的HashMap,称之为段(SEGMENT)。在默认情况下,一个ConcurrentHashMap类可以被细分为16个段。
如果需要在ConcurrentHashMap类中增加一个新的表项,并不是将整个HashMap加锁,而是首先根据hashcode得到该表项应该被存放到哪个段中,然后对该段加锁,并完成put()方法操作。在多线程环境中,如果多个线程同时进行put()方法操作,只要被加入的表项不存放在同一个段中,线程间便可以做到真正的并行。
由于默认有16个段,因此,如果够幸运的话,ConcurrentHashMap类可以接受16个线程同时插入(如果都插入不同的段中),从而大大提升其吞吐量。下面代码显示了put()方法操作的过程。第5~6行代码根据key获得对应段的序号。接着在第9行得到段,然后将数据插入给定的段中。

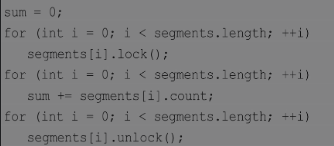
ConcurrentHashMap类的size()方法并不总是这样执行的,事实上,size()方法会先使用无锁的方式求和,如果失败才会尝试这种加锁的方法。但不管怎么说,在高并发场合ConcurrentHashMap类的size()方法的性能依然要差于同步的HashMap。 因此,只有在类似于size()方法获取全局信息的方法调用并不频繁时,这种减小锁粒度的方法才能在真正意义上提高系统的吞吐量。
注意:所谓减小锁粒度,就是指缩小锁定对象的范围,从而降低锁冲突的可能性,进而提高系统的并发能力
四、用读写分离锁来替换独占锁
之前我们已经提过,使用读写分离锁ReadWriteLock可以提高系统的性能。使用读写分离锁来替代独占锁是减小锁粒度的一种特殊情况。如果说减小锁粒度是通过分割数据结构实现的,那么读写分离锁则是对系统功能点的分割。
在读多写少的场合,读写锁对系统性能是很有好处的。因为如果系统在读写数据时均只使用独占锁,那么读操作和写操作间、读操作和读操作间、写操作和写操作间均不能做到真正的并发,并且需要相互等待。而读操作本身不会影响数据的完整性和一致性。因此,从理论上讲,在大部分情况下,可以允许多线程同时读,读写锁正是实现了这种功能。由于我们在第3章中已经介绍了读写锁,因此这里就不再重复了。
注意:在读多写少的场合使用读写锁可以有效提升系统的并发能力
五、锁分离
如果将读写锁的思想进一步延伸,就是锁分离。读写锁根据读写操作功能上的不同,进行了有效的锁分离。依据应用程序的功能特点,使用类似的分离思想,也可以对独占锁进行分离。一个典型的案例就是java.util.concurrent.LinkedBlockingQueue的实现(我们在之前已经讨论了它的近亲ArrayBlockingQueue的内部实现)。
在LinkedBlockingQueue的实现中,take()函数和put()函数分别实现了从队列中取得数据和往队列中增加数据的功能。虽然两个函数都对当前队列进行了修改操作,但由于LinkedBlockingQueue是基于链表的,因此两个操作分别作用于队列的前端和尾端,从理论上说,两者并不冲突。
如果使用独占锁,则要求在两个操作进行时获取当前队列的独占锁,那么take()方法和put()方法就不可能真正的并发,在运行时,它们会彼此等待对方释放锁资源。在这种情况下,锁竞争会相对比较激烈,从而影响程序在高并发时的性能。
因此,在JDK的实现中,并没有采用这样的方式,取而代之的是用两把不同的锁分离了take()方法和put()方法的操作。
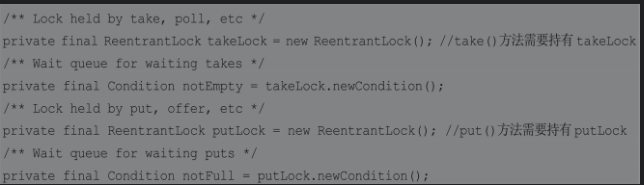
take()方法的实现如下,笔者在代码中给出了详细的注释,故不在正文中做进一步说明了。

 函数put()的实现如下。
函数put()的实现如下。 
六、锁粗化
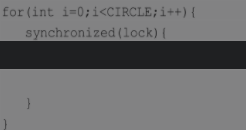
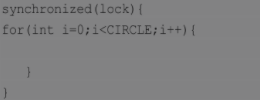
通常情况下,为了保证多线程间的有效并发,会要求每个线程持有锁的时间尽量短,即在使用完公共资源后,应该立即释放锁。只有这样,等待在这个锁上的其他线程才能尽早地获得资源执行任务。但是,凡事都有一个度,如果对同一个锁不停地进行请求、同步和释放,其本身也会消耗系统宝贵的资源,反而不利于性能的优化。
为此,虚拟机在遇到一连串连续地对同一个锁不断进行请求和释放的操作时,便会把所有的锁操作整合成对锁的一次请求,从而减少对锁的请求同步的次数,这个操作叫作锁的粗化。


发表评论
最新留言
关于作者
