Oracle 多行函数(聚合函数)和分组统计
发布日期:2021-05-07 19:44:22
浏览次数:19
分类:精选文章
本文共 1149 字,大约阅读时间需要 3 分钟。
文章目录
一、聚合函数
多行函数 (聚合函数):作用于多行,返回一个值。
--这里的1表示主键那一列select count(1) from emp;---查询总数量select sum(sal) from emp;---工资总和select max(sal) from emp;---最大工资select min(sal) from emp;---最低工资select avg(sal) from emp;---平均工资
二、分组统计
分组统计需要使用 GROUP BY 来分组
语法:
SELECT * |列名 FROM 表名 { WEHRE 查询条件} { GROUP BY 分组字段} ORDER BY 列名 1 ASC|DESC,列名 2...ASC|DESC 分组查询中,出现在 group by 后面的原始列,才能出现在select后面
没有出现在 group by 后面的列,想在 select 后面,必须加上聚合函数。 聚合函数有一个特性,可以把多行记录变成一个值- 查询每个部门的人数
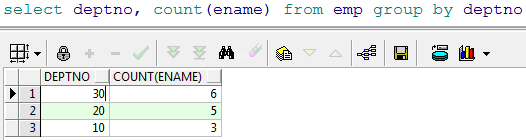
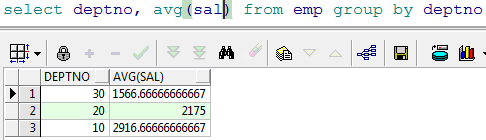
- 查询出每个部门的平均工资
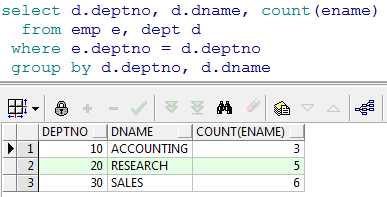
- 如果我们想查询出来部门编号,和部门下的人数

- 按部门分组,查询出部门名称和部门的员工数量
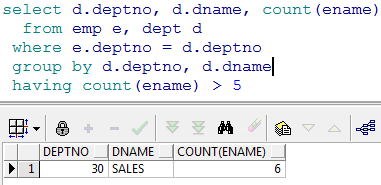
- 查询出部门人数大于 5 人的部门 分析:需要给 count(ename)加条件,此时在本查询中不能使用 where,可以使用 HAVING
- 查询出部门平均工资大于 2000 的部门
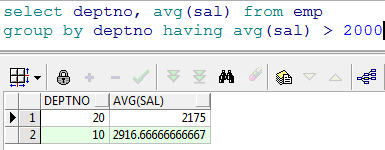
---查询出平均工资高于2000的部门信息select e.deptno, avg(e.sal) asalfrom emp egroup by e.deptnohaving avg(e.sal)>2000;---所有条件都不能使用别名来判断,因为条件的优先级大于select,所以运行where时,别名还未成立--比如下面的条件语句也不能使用别名当条件select ename, sal s from emp where sal>1500;---查询出每个部门工资高于800的员工的平均工资select e.deptno, avg(e.sal) asalfrom emp ewhere e.sal>800group by e.deptno;----where是过滤分组前的数据,having是过滤分组后的数据。---表现形式:where必须在group by之前,having是在group by之后。---查询出每个部门工资高于800的员工的平均工资---然后再查询出平均工资高于2000的部门select e.deptno, avg(e.sal) asalfrom emp ewhere e.sal>800group by e.deptnohaving avg(e.sal)>2000;
发表评论
最新留言
初次前来,多多关照!
[***.217.46.12]2025年04月16日 21时53分38秒
关于作者

喝酒易醉,品茶养心,人生如梦,品茶悟道,何以解忧?唯有杜康!
-- 愿君每日到此一游!
推荐文章
AtCoder Beginner Contest 100 题解
2021-05-09
【数据结构】可持久化线段树初步
2021-05-09
Java高性能编程之CAS与ABA及解决方法
2021-05-09
从BIO到Netty的演变
2021-05-09
《算法导论》第二章笔记
2021-05-09
HTML节点操作
2021-05-09
HTML5新特性
2021-05-09
cmp命令
2021-05-09
一次编辑
2021-05-09
JavaScript中的链式调用
2021-05-09
day-04-列表
2021-05-09
Linux 磁盘管理(df fu fdisk mkfs mount)
2021-05-09
第一类曲面积分
2021-05-09
MySQL锁机制
2021-05-09
Go 数组&切片
2021-05-09
Go 文件操作
2021-05-09
老Python总结的字典相关知识
2021-05-09
vue 不常见操作
2021-05-09
jQuery的事件绑定与触发 - 学习笔记
2021-05-09
Python处理接口测试的签名
2021-05-09
白红宇的个人博客 - 记录点点滴滴的事 - 您是第 459510964 位访客
访问时间: 2025-04-19 09:39:14
访问IP: 18.116.230.250
Copyright © 2020 - 2025 css8.cn 京ICP备2021015314号-1
手机版