本文共 4798 字,大约阅读时间需要 15 分钟。
实战2、pycharm+python+MS SQLSERVER实现爬虫程序。
实现 python 爬老毛桃网站 u盘启动制作工具 所有版本号,然后写入MS SQLSERVER数据库中
稍后更新...

首先在pycharm的点左下角的 Terminal ,输入pip install requests 和 pip install BeautifulSoup4 安装包
一、先热下身,写第一个 爬百度网站。
import requests
from bs4 import BeautifulSoup
resp=requests.get('https://www.baidu.com') #请求百度首页
print(resp) #打印请求结果的状态码
print(resp.content) #打印请求到的网页源码
bsobj=BeautifulSoup(resp.content,'lxml') #将网页源码构造成BeautifulSoup对象,方便操作
a_list=bsobj.find_all('a') #获取网页中的所有a标签对象
text='' # 创建一个空字符串
for a in a_list:
href=a.get('href') #获取a标签对象的href属性,即这个对象指向的链接地址
text+=href+'\n' #加入到字符串中,并换行
with open('url.txt','w') as f: #在当前路径下,以写的方式打开一个名为'url.txt',如果不存在则创建
f.write(text) #将text里的数据写入到文本中
二、爬 老毛桃网站
老毛桃网站有防爬,所以我改为另一个网友的例子并加入写入数据库部分。
我们要爬的网站
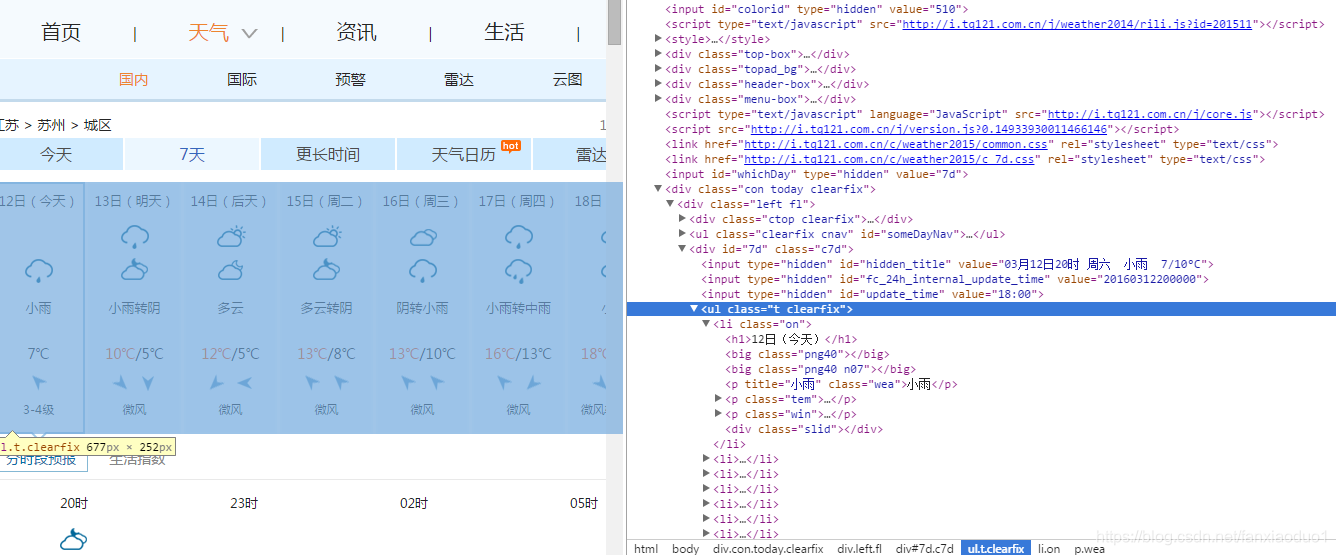
1、首先在MS SQLSERVER 中 建立新表t_tq
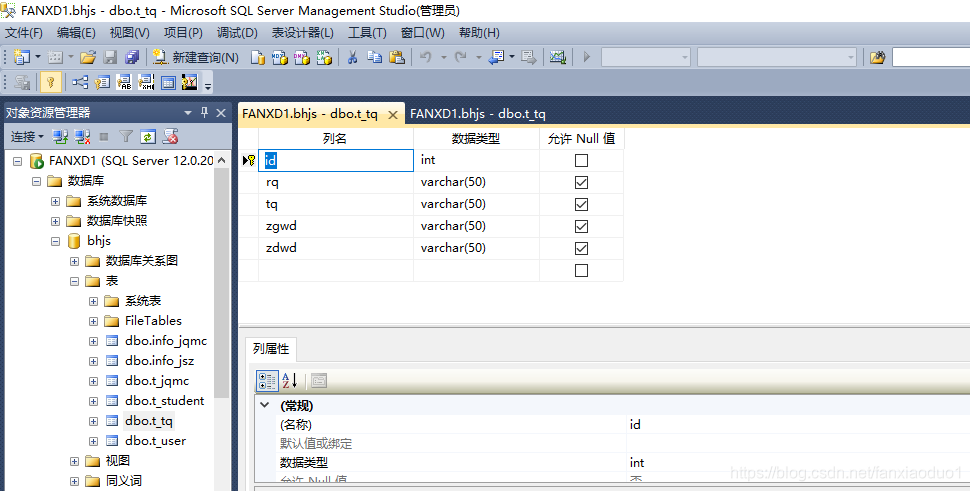
2、pycharm IDE 中选new project->pure python , 在项目上新建一个python文件testtq.py 然后拷贝入如下代码
import requestsimport csvimport randomimport timeimport socketimport http.client# import urllib.requestfrom bs4 import BeautifulSoupimport pymssqldef insert(results): # Create your views here. # 打开数据库连接 db = pymssql.connect(host='127.0.0.1', user='sa', password='3201319', database='bhjs', port=1433) # 使用cursor()方法获取操作游标 cur = db.cursor() sql = "INSERT INTO t_tq (rq,tq,zgwd,zdwd) VALUES (%s, %s, %s, %s)" try: cur.execute(sql,(results['rq'],results['tq'],results['zgwd'],results['zdwd'])) # 执行sql语句 #results = cur.fetchall() # 所有记录 db.commit() except Exception as e: raise e return resultsdef get_content(url , data = None): header={ 'Accept': 'text/html,application/xhtml+xml,application/xml;q=0.9,image/webp,*/*;q=0.8', 'Accept-Encoding': 'gzip, deflate, sdch', 'Accept-Language': 'zh-CN,zh;q=0.8', 'Connection': 'keep-alive', 'User-Agent': 'Mozilla/5.0 (Windows NT 6.3; WOW64) AppleWebKit/537.36 (KHTML, like Gecko) Chrome/43.0.235' } timeout = random.choice(range(80, 180)) while True: try: rep = requests.get(url,headers = header,timeout = timeout) rep.encoding = 'utf-8' # req = urllib.request.Request(url, data, header) # response = urllib.request.urlopen(req, timeout=timeout) # html1 = response.read().decode('UTF-8', errors='ignore') # response.close() break # except urllib.request.HTTPError as e: # print( '1:', e) # time.sleep(random.choice(range(5, 10))) # # except urllib.request.URLError as e: # print( '2:', e) # time.sleep(random.choice(range(5, 10))) except socket.timeout as e: print( '3:', e) time.sleep(random.choice(range(8,15))) except socket.error as e: print( '4:', e) time.sleep(random.choice(range(20, 60))) except http.client.BadStatusLine as e: print( '5:', e) time.sleep(random.choice(range(30, 80))) except http.client.IncompleteRead as e: print( '6:', e) time.sleep(random.choice(range(5, 15))) return rep.textdef get_data(html_text): item_p={'rq':50,'tq':50,'zgwd':50,'zdwd':50} final = [] bs = BeautifulSoup(html_text, "html.parser") # 创建BeautifulSoup对象 body = bs.body # 获取body部分 data = body.find('div', {'id': '7d'}) # 找到id为7d的div ul = data.find('ul') # 获取ul部分 li = ul.find_all('li') # 获取所有的li for day in li: # 对每个li标签中的内容进行遍历 temp = [] date = day.find('h1').string # 找到日期 temp.append(date) # 添加到temp中 item_p['rq']=date inf = day.find_all('p') # 找到li中的所有p标签 temp.append(inf[0].string) # 第一个p标签中的内容(天气状况)加到temp中 item_p['tq']=inf[0].string if inf[1].find('span') is None: temperature_highest = None # 天气预报可能没有当天的最高气温(到了傍晚,就是这样),需要加个判断语句,来输出最低气温 else: temperature_highest = inf[1].find('span').string # 找到最高温 temperature_highest = temperature_highest.replace('℃', '') # 到了晚上网站会变,最高温度后面也有个℃ temperature_lowest = inf[1].find('i').string # 找到最低温 temperature_lowest = temperature_lowest.replace('℃', '') # 最低温度后面有个℃,去掉这个符号 temp.append(temperature_highest) # 将最高温添加到temp中 temp.append(temperature_lowest) #将最低温添加到temp中 item_p['zgwd']=temperature_highest item_p['zdwd']=temperature_lowest final.append(temp) #将temp加到final中 insert(item_p) return finaldef write_data(data, name): file_name = name with open(file_name, 'a', errors='ignore', newline='') as f: f_csv = csv.writer(f) f_csv.writerows(data)if __name__ == '__main__': url ='http://www.weather.com.cn/weather/101190401.shtml' html = get_content(url) result = get_data(html) # write_data(result, 'weather.csv')
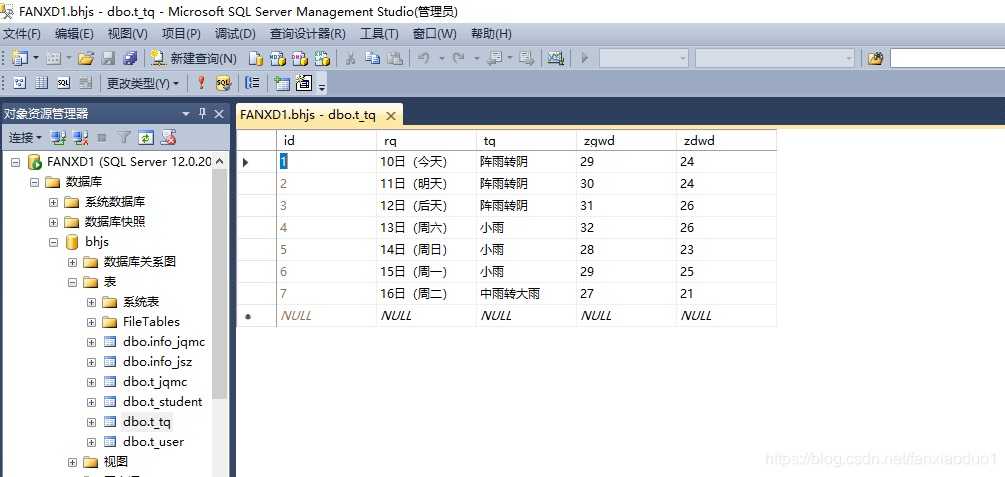
3、运行,在SQLSERVER中可得到如下结果

打呆仗,结硬寨,用最好的工具。——曾国藩

发表评论
最新留言
关于作者
